Alibabaは7月21日、X上で最新のLLMであるQwen 3のアップデート、Qwen3-235B-A22B-Instruct-2507を発表しました。このオープンソースモデルはApache 2.0ライセンスで配布され、2350億のパラメータを持ち、DeepSeek-V3、AnthropicのClaude Opus 4、OpenAIのGPT-4o、最近中国のスタートアップMoonshotがリリースしたKimi 2よりも4倍大きい、強力な競合となっています。
Alibaba Cloudは投稿で以下のように述べています:
"コミュニティと話し合い、検討した結果、ハイブリッド思考モードを廃止することを決定しました。今後、InstructモデルとThinkingモデルを別々にトレーニングし、可能な限り最高の品質を追求します"。
Qwen3-235B-A22B-Instruct-2507は非思考(ノンシンキング)モデルであり、複雑な連鎖推論を行うのではなく、指示の実行において迅速性と妥当性を重視しています。
この戦略的方向性のおかげで、Qwen 3は指示のフォローにおいて進化するだけでなく、論理的推論、専門分野の深い理解、稀少言語の処理、数学、科学、プログラミング、デジタルツールとの相互作用においても進展を示しています。
開放的なタスクにおいては、判断、トーン、創造性を伴うタスクにおいて、ユーザーの期待により適合し、より有用な回答とより自然な生成スタイルを提供します。
コンテキストウィンドウは256,000トークンに拡張され、8倍に増加し、大量のドキュメントを処理できるようになりました。
柔軟性と効率性を重視したアーキテクチャ
このモデルは128の専門家がいるMixture-of-Experts(MoE)アーキテクチャに基づいており、要求に応じて8つの専門家が選ばれます。2350億のパラメータのうち、22億のみが要求ごとにアクティブになります。
94層の深さを持ち、最適化されたGQA(Grouped Query Attention)スキームに基づいており、64のクエリ(Q)ヘッドとキーおよびバリュー用の4つのヘッドを持ちます。
Qwen3-235B-A22B-Instruct-2507の性能
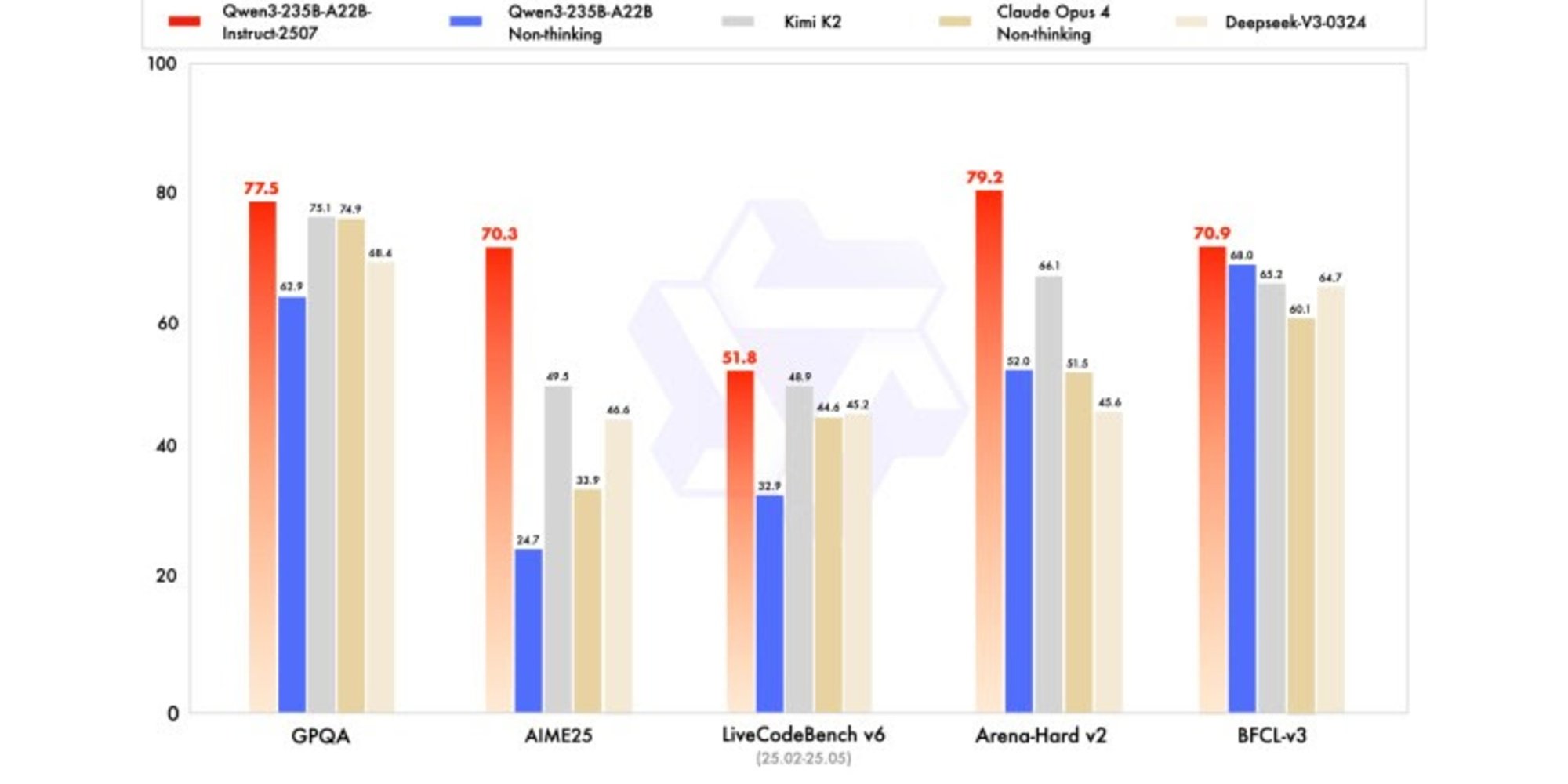
新しいバージョンは、特に数学、コーディング、論理的推論において競争力があり、場合によっては競合他社のリーダーモデルを上回る結果を示しています。
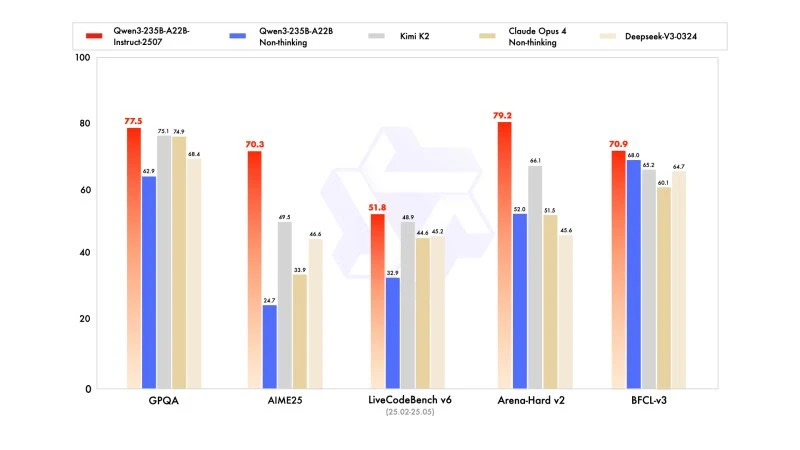
一般的な知識においては、MMLU-Proで83.0(前バージョンは75.2)、MMLU-Reduxで93.1を獲得し、Claude Opus 4(94.2)に近づいています。
高度な推論においては、数学モデリングで非常に高いスコアを達成しました。2025年のAIME(American Invitational Mathematics Examination)で70.3を獲得し、DeepSeek-V3-0324の46.6やOpenAIのGPT-4o-0327の26.7を上回りました。
コーディングでは、MultiPL-Eで87.9のスコアを記録し、Claude(88.5)の後ろですが、GPT-4oやDeepSeekを上回っています。LiveCodeBench v6では51.8を達成し、このベンチマークで測定された最高のパフォーマンスを示しています。
FP8での量子化バージョン:妥協なしの最適化
AlibabaはQwen3-235B-A22B-Instruct-2507と同時にFP8での量子化バージョンを公開しました。この圧縮された数値フォーマットはメモリの必要性を大幅に削減し、推論を加速します。これにより、リソースが限られた環境でも、パフォーマンスの大幅な低下なしにモデルを動作させることができます。