
Researchers at the University of California, Berkeley, propose a data-driven approach to optimizing neural networks using generative models trained on these parameters. Their study, " Learning to Learn with Generative Models of Neural Network Checkpoints," was published on arXiv in late September.
Radiant-based optimization is the fuel of modern deep learning. Gradient-based optimization methods such as stochastic gradient descent (SGD, Robbins &Monro, 1951) or Adam (Kingma &Ba, 2015) are easy to implement and perform very well even in high-dimensional non-convex loss spaces of neural networks.
In the last decade, they have enabled impressive advances, especially in computer vision and natural language processing and, on the other hand, generated a massive amount of neural network checkpoints. However, they suffer from an important limitation: they cannot improve on past experience. For example, SGD does not converge any faster when used to optimize the same neural network architecture from the same initialization the 100th time than the first. Optimizers learning from past experience have the potential to overcome this limitation and can accelerate future progress in deep learning.
The concept of improved optimizers is not new and dates back to at least the 1980s. In recent years, significant effort has been devoted to designing algorithms that learn via nested meta-optimization, where the inner loop optimizes the task-level objective and the outer loop learns the optimizer. Some of these approaches have been shown to outperform manual optimizers, but their dependence on unrolled optimization and reinforcement learning makes them difficult to train in the real world.
Pre-training a generative model on control points
Instead of leveraging large-scale image or text datasets, the University of California researchers propose learning from checkpoint datasets recorded over many training runs.Neural network checkpoints contain a wealth of information: various parameter configurations and rich metrics such as test losses, misclassification errors and reinforcement learning feedback that drives checkpoint quality. The researchers pre-trained a generative model on millions of checkpoints and used it in testing to generate parameters for a neural network that solves a downstream task.
They called their model G.pt (G and .pt refer to generative models and control point extensions, respectively). G.pt is trained as a diffusion model based on the neural network parameter transformation. It takes as input a starting parameter vector (potentially randomly initialized), the starting loss/error/return, and the user's desire: loss/error/return. Once trained, it samples a parameter update from the model that matches the user's requested metric.
Their pre-training dataset contains 23 million neural network checkpoints over 100,000 training runs. It contains data from MLP and CNN neural networks trained for vision tasks (MNIST, CIFAR-10) and continuous control tasks (Cartpole).
[caption id="attachment_40224" align="alignnone" width="1600"]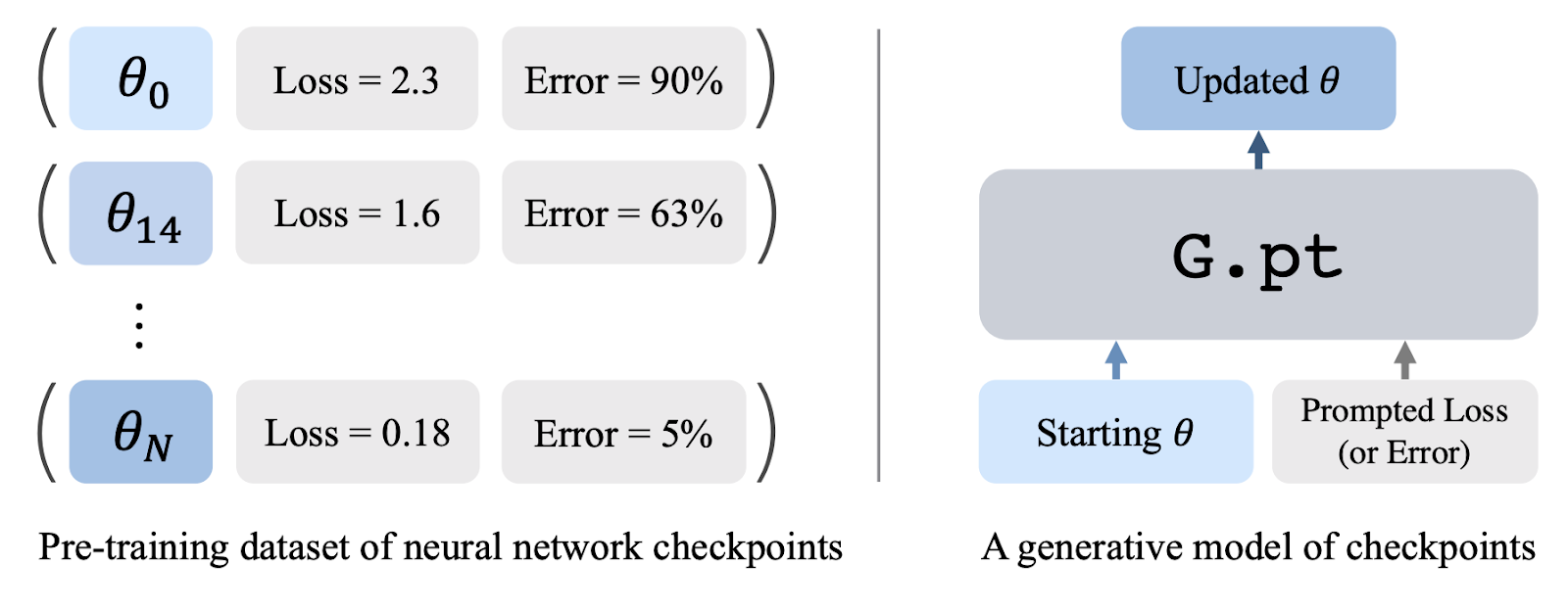 Generative pre-training from control points. Left: Building a dataset of neural network control points. Each control point includes neural network parameters and relevant metadata (losses and test errors for supervised learning tasks, returns for RL tasks). Right: G.pt, a generative model of control points. G.pt takes a parameter vector and a loss/error/return prompt as input and predicts the distribution over the updated parameters that yield the prompt.[/caption]
Generative pre-training from control points. Left: Building a dataset of neural network control points. Each control point includes neural network parameters and relevant metadata (losses and test errors for supervised learning tasks, returns for RL tasks). Right: G.pt, a generative model of control points. G.pt takes a parameter vector and a loss/error/return prompt as input and predicts the distribution over the updated parameters that yield the prompt.[/caption]
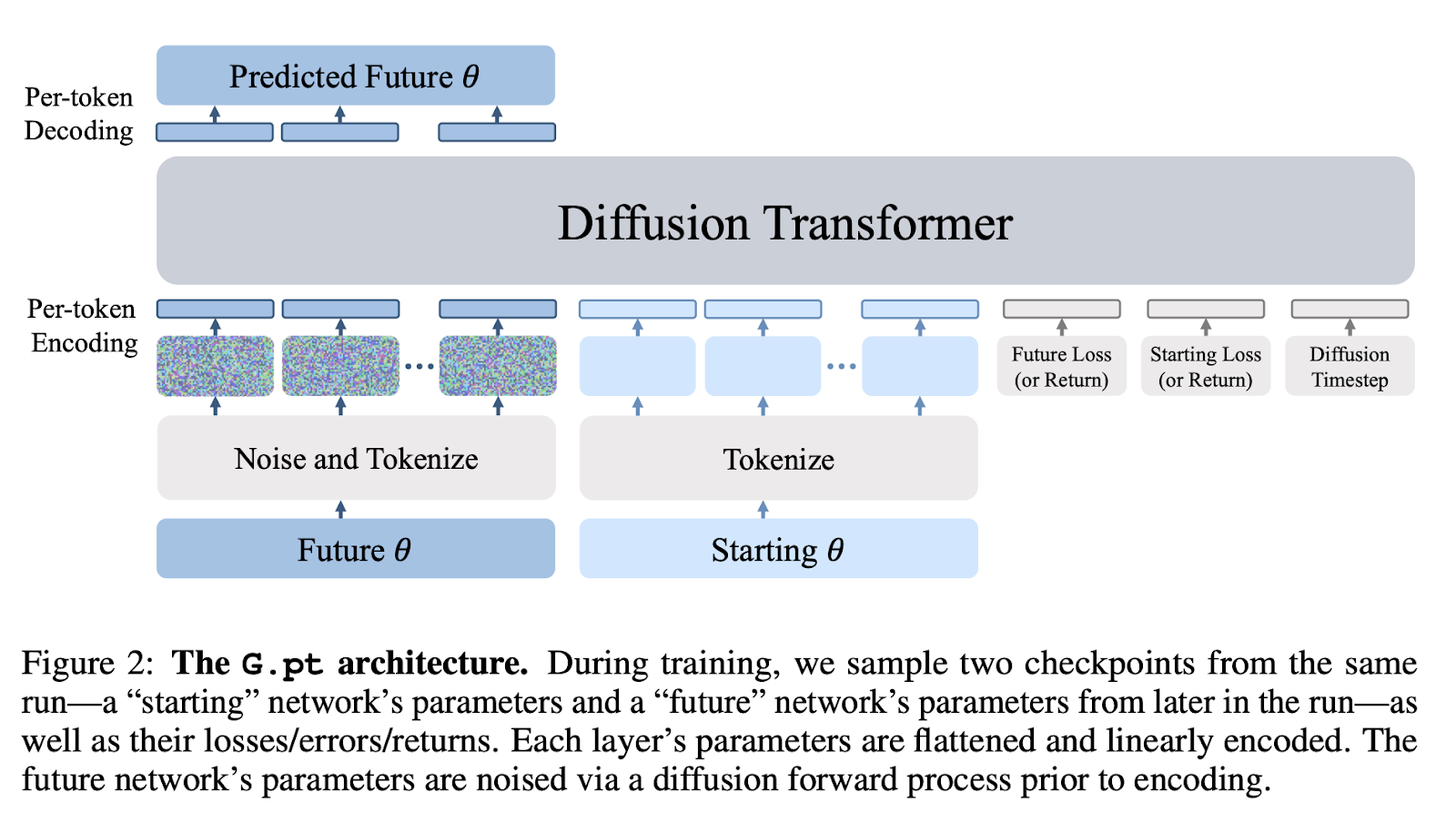
The backbone of their diffusion model is a transformer that operates on sequences of neural network parameters.
The G.pt model was trained for a given dataset, metric, and architecture (e.g., a loss-conditional CNN CIFAR-10 model, an error-conditional MLP MNIST model...). The backbone of their diffusion model is a transformer that operates on sequences of neural network parameters and uses little domain-specific inductive bias beyond tokenization.
The researchers thus demonstrated that their approach has a number of favorable properties. First, it can quickly train neural networks from unseen initializations with a single parameter update. Second, it can generate parameters that allow for a wide range of losses, errors, and induced feedback. Third, it is capable of generalizing to off-distribution weight initialization algorithms. Fourth, as a generative model, it is capable of sampling various solutions.
Another advantage of this method over traditional optimizers is that it can directly optimize non-differentiable metrics, such as classification errors or RL returns. Indeed, G.pt is trained as a diffusion model in parameter space, and the researchers were not required to backpropagate through these metrics in order to train their model.
Article source:
LEARNING TO LEARN WITH GENERATIVE MODELS OF NEURAL NETWORK CHECKPOINTS
arXiv:2209.12892v1, 26 September 2022
Authors: William Peebles, Ilija Radosavovic, Tim Brooks, Alexei A. Efros, Jitendra Malik.
University of California, Berkeley
Translated from Des chercheurs de l'UC Berkeley optimisent les réseaux neuronaux grâce à des modèles génératifs de points de contrôle