

Main contributors: Axionable, DC Brain, Intel, Microsoft, Orange – members of the Impact AI Environment taskforce
Impact AIis the Think & Do Tank of reference for ethical artificial intelligence in France. Our vision is to work together with the digital ecosystem (companies, startups, institutions, research or training organizations, civil society actors…) to create a collective AI approach that meets the needs and expectations of citizens. Our Taskforce dedicated to the environment aims to study, deepen and provide keys to understanding and concrete applications around two key concepts at the crossroads of AI and the environment: Green AI & AI for Green.
We hope you enjoy reading our paper dedicated to Green AI, which will help you understand the major issues and sort out the real from the fake, but also to initiate an ambitious and state-of-the-art Green AI approach thanks to the sharing of best practices, tools and methodologies[1].
Introduction
The summer of 2022 was a sad witness: the multiplication of extreme weather events (heat domes, floods, fires, drought, hurricanes…) highlighted by the various IPCC reports, confront us every day with the climate disruption caused by human activities that emit greenhouse gases into the atmosphere.
The increase in temperature on Earth depends, in part, on the total amount of carbon present in the atmosphere, and not on the speed at which we emit it. To limit the temperature rise to 1.5 degrees by 2050, we must first stop adding carbon to the atmosphere, and then achieve neutrality on the remaining emissions. This means that for every gram of carbon we emit, we must remove one gram: the overall mass of carbon in the atmosphere remains fixed.
In this context of climate change, digital technology appears to be a ” Pharmakon ” for the environment, which in Greek means both remedy and poison.
On the one hand, according toADEME, digital technology currently accounts for 3.5% of greenhouse gas emissions, and the sharp increase in usage suggests that this figure will double by 2025 if nothing is done to limit its impact.
On the other hand, digital technology is essential to the transformation of organizations and can play a positive role in reducing GHG emissions generated by other sectors (energy, transport, heating, industry, etc.).
In order to reconcile the ecological transition and the digital transition, we must put sustainability at the heart of technology (Green IT) and use technology to serve sustainability (IT for Green). The particular case of the use of Artificial Intelligence (AI) is a perfect example of this contradictory injunction.
Artificial intelligence presents use cases with positive impacts on the environment (AI for Green). Their impact can be measured by their contribution to the 17 United Nations Sustainable Development Goals, encompassing societal, economic and environmental outcomes: AI could contribute to 134 targets but would have a negative effect by inhibiting 59 targets( 2020study published in Nature Communications). The AI for Earth program or the Climate Change AI initiative are examples of initiatives that are bringing out use cases for AI in the service of sustainable development.
On the other hand, AI has a strong and growing carbon impact and therefore contributes to climate change. Indeed, the availability of data and computing capacities has led to a race for performance (Red AI) and a sharp increase in computing costs. We note that the relationship between performance and model complexity (measured in number of parameters or inference time) is at best logarithmic: for a linear gain in performance, model complexity grows exponentially. For example, training the model emits 50% of its CO2 only to achieve a final decrease of 0.3 in the word recognition error rate (“ The Energy and Carbon Footprint of Training End-to-End Speech Recognizers “) or GPT-3, a powerful (175 billion parameters) and recent OpenAI language model, would have consumed enough energy during training to leave a carbon footprint equivalent to driving a car from the Earth to the Moon and back.
The awareness and urgency of climate change has led to the structuring of the “Green AI” movement, initiated by researchers in natural language processing, proposing a compromise between model accuracy and carbon cost. Some conferences(NeurIPS 2019, EMNLP 2020, SustaiNLP2020) now require the computational costs necessary to generate the results proposed in all submissions.
Peter Drucker’s quote “You can’t manage what you can’t measure”, applies of course to sustainable AI for which it is imperative to 1/ understand and apprehend the subject as a whole, 2/ measure greenhouse gas emissions and other environmental impacts and 3/ manage and reduce these impacts.
The Impact AI collective offers below a toolbox based on the three components 1/ understanding 2/ measuring 3/ reducing, in order to help you structure and initiate your Green AI approach and accelerate its operational implementation.
Expert testimony
Gwendal Bihan, CEO of Axionable, Vice-President of Impact AI and leader of the environment taskforce:
“The exemplarity of a Green AI approach is key: robust methodologies and tools exist, but it is necessary to understand and use them well in order to adopt a global, ambitious and consistent approach. Through this paper, we wish to contribute to raising awareness and increasing collective maturity around the understanding, measurement and reduction of the environmental impacts of AI.”
1/ Understanding
The notion of “Green AI” is generally associated with the carbon footprint linked to the energy consumption of AI and in particular to the training phases of neural networks, which are sometimes very complex, such as GPT3. However, the environmental impact of AI cannot be reduced to this alone: the notion of Green AI must be taken into account in a more global way if we wish to adopt a holistic approach.
The need to integrate the Green AI approach into a global Green IT approach
The specific impact of AI is still difficult to estimate or isolate from the overall carbon footprint of digital technology, due to the relatively recent appearance of the subject (see the first founding texts in the introduction and bibliography of this paper) and the absence of standards and benchmarks established around Green AI. The limits of AI must therefore be defined within an organization that wishes to take a Green AI approach: how much of the impact can be attributed specifically to AI compared to the overall impact of digital technology within my organization? The limit is not easy to establish, so it is important not to hide a part of the greenhouse gas emissions linked to AI and on the contrary to adopt a holistic and complete vision of the carbon impacts on the whole value chain. It is therefore necessary to include the Green AI approach in a more global approach to green IT.
Also, it is important to keep in mind the orders of magnitude of the carbon impact related to digital: a recent study by Arcep showed that among digital equipment, terminals represent the majority of the carbon footprint (79%) followed by data centers (16%) and networks (5%). Also, the majority of the carbon footprint of equipment is emitted during the manufacturing of equipment (78%) compared to its use (21%)(source). Thus, most of the GHG emissions related to digital technology are related to the manufacture, transport and end of life of terminals and equipment. These orders of magnitude highlight the need for a global and coherent approach between Green AI and Green IT.
Accounting for greenhouse gas emissions across Scopes 1, 2 and 3
The AI carbon footprint is the indicator commonly used to initiate and manage a Green AI approach and to implement and measure improvement actions. When talking about carbon footprint, it is absolutely necessary to take into account all 3 GHG emission scopes:
- Scope 1 emissions cover direct emissions related to gas and fuel consumption and refrigerant leaks, particularly in the cooling and air conditioning circuits of data centers;
- Scope 2 emissions cover indirect energy-related emissions, i.e. the production and consumption of electricity and steam (heating/cooling);
- Scope 3 emissions cover all other indirect emissions, the main items of which are generally concentrated around :
- the manufacture, transport and end-of-life of IT equipment linked to the training and production of AI and the edge equipment on which AI is deployed;
- the purchase of technical and IT services dedicated to AI projects (software license, outsourcing, etc.);
- the use of products / services targeted by the AI project.
The analysis of the carbon footprint at all stages of the AI life cycle
When we talk about Green AI, we often think first of the carbon footprint related to the training phase of the AI; some studies allow us to obtain first evaluations of this carbon footprint, we estimate for example 85 tons of CO2e for the training of GPT-3(source).
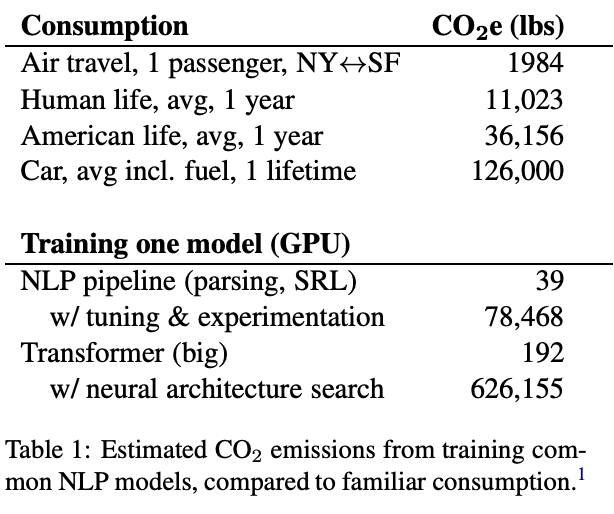
However, measuring the carbon footprint as part of a global Green AI approach should not be limited to the training phase, but should cover all stages of the AI life cycle, from design to inference. The trend is for a sharp increase in the carbon footprint of AI. Indeed, as computing capacities and the amount of available data increase, we are witnessing a race for performance resulting in an increase in the size and complexity of models. A complex model requires more resources for training and production. This has consequences at all stages of the AI life cycle:
- The increase in the amount of data used in AI systems has impacts on the necessary infrastructures: data storage and ingestion pipeline represent a significant part of the energy consumption;
- Increasing the size of models allows for better performance but requires resources for scaling an AI model that clearly exceed those of existing hardware;
- Growth in model size leads to growth in resources required for training (x2.9) and inference (x2.5).
This illustrates how carbon emissions occur throughout the lifecycle of an AI project: development, deployment, use… Therefore, we need to consider the footprint of existing and exploited data, algorithms and physical systems, from the manufacturing of materials to the operational use of all AI components to have a complete view of the carbon footprint of an AI system.
Beyond carbon, taking into account other environmental impacts
Finally, it is important to emphasize that the carbon footprint is not the only environmental impact generated by AI and more generally by digital technology. The study published at the end of 2021 by NegaOctet and GreenIT(source) on the evaluation of the life cycle of digital technologies in Europe has, for example, integrated the impacts related to the depletion of natural abiotic resources (minerals, metals), the consumption of fossil resources, the effects on climate change, the consumption of fresh water and ecotoxicity, particle emissions, ionizing radiation impacting human health, or the production of electrical and electronic waste. The carbon footprint is thus a measurable indicator that is widely used to quantify the environmental impact of an activity. It is this indicator that we have chosen to use for the rest of the article on measuring and identifying reduction actions.
Five key points to remember in order to understand the concept of Green AI and adopt a holistic approach:
- It is necessary to take into account the impact of all 3 scopes of GHG emissions and not only the impact of electricity consumption;
- It is necessary to take into account the whole life cycle of AI, from ideation and design to inference, through training and production of models;
- It is necessary to consider the impact of all the infrastructures and services associated with the AI project: hosting, networks, equipment, applications and software, terminals and edge;
- It is strongly recommended that the Green AI approach is part of a more global Green IT approach, to ensure consistency at the boundaries of AI, which are still difficult to define precisely;
- although it is currently the key indicator of Green AI, carbon is not the only environmental impact of AI and other impacts can be considered (water, abiotic resources, climate change, electrical and electronic waste,…)
Sources / To go further :
- https://www.researchgate.net/publication/354088344_Understanding_and_Co-designing_the_Data_Ingestion_Pipeline_for_Industry-Scale_RecSys_Training
- https://cs.stanford.edu/~matei/papers/2020/iclr_svp.pdf
- https://arxiv.org/pdf/2101.11714.pdf
- https://www.impact-ai.fr/app/uploads/2022/03/IMPACT-AI-FICHES-PRATIQUES-NUMERIQUES.pdf?utm_source=mailchimp&utm_campaign=0300fd4ce0f0&utm_medium=page
- https://www.arcep.fr/uploads/tx_gspublication/etude-numerique-environnement-ademe-arcep-note-synthese_janv2022.pdf
- https://ecoresponsable.numerique.gouv.fr/publications/guide-pratique-achats-numeriques-responsables/
- https://www.greenit.fr/le-numerique-en-europe-une-approche-des-impacts-environnementaux-par-lanalyse-du-cycle-de-vie/
2/ Measuring
The exercise of measuring the carbon footprint of AI is not necessarily a simple one:
- There is no specific and recognized reference framework or methodology to accurately measure the carbon footprint of digital activities, including the AI sub-area;
- the “traditional” carbon benchmarks are not well adapted to the carbon assessment of digital activities;
- All the activity data needed to calculate GHG emissions are not always available, especially when they depend on external providers and partners;
- Measurement solutions are beginning to emerge on the market, but they do not all have the same objectives, the same methodology or the same scope;
- Methodological differences are observed between the various players and reference systems.
We thus propose below a first overview of methodologies and resources available to help you work on measuring the carbon footprint of AI.
Measuring carbon emissions related to the energy consumption of AI models
Operating energy is the energy used during the operation of AI, whether for training models or for models in production. It can be measured at three levels: a priori measurement, a posteriori measurement and on-the-fly measurement.
When measuring the carbon footprint associated with the energy consumption of AI models, it is important to take into account the energy consumed during the training of the model but also the inference once the model is in production. Indeed, this energy is not negligible and could represent 80 to 90% of the carbon footprint of a neural network(source). We have distinguished three main methods to measure the energy consumption of AI models: a priori measurement, a posteriori measurement and on-the-fly measurement.
A priori measurement
The a priori measurement is based on the estimation of the number of operations to be performed by the computer during the execution of the code. This number of operations is generally calculated in FLOPS (floating point operations per second), which corresponds to the number of primary operations. It is then converted into energy according to the characteristics of the equipment used for the execution and then into carbon equivalent.
Several libraries are available depending on the type of model. For example, Keras Flops allows to estimate the number of Flops on a Tensor Flow model and Keras or Torchstat which does the equivalent for a Pytorch model.
To generalize this approach and to estimate the cost of a complete project, we can use the following approximation(source):
![]()
With
- Example: calculation cost for an example
- Dataset: number of examples in the training dataset
- Hyperparameters: number of combinations of hyperparameters tested (number of experiments)
This formula is only an approximation and does not take into account some factors such as the number of epochs (specificity of neural networks).
Posteriori measurement
The a posteriori measurement is an estimation of the carbon footprint based on the calculation time and the infrastructure used. The ML CO2 Impact tool developed by Mila (Quebec AI Institute) allows to estimate the carbon footprint of a training session based on the training time, the type of hardware, the cloud provider and the country. The tool also provides the amount of carbon offset by the cloud provider as well as infrastructure optimization tips to reduce consumption.
On-the-fly measurement
On-the-fly measurement consists in directly measuring the processor’s power consumption during the execution of the code. To do this, you can use the CodeCarbon library which, by adding a few lines of code, allows you to measure the processor’s consumption during the execution of the code.
A more general measurement is carried out by the cloud providers and can be followed on dashboards with more or less detail depending on the cloud. For example, the resources collected by Azure Monitor from an Azure Machine Learning workspace can be used to collect the Energy indicator in joules per minute intervals on a GPU node.
Measuring other carbon emissions
As already mentioned, in order to measure the carbon impact of AI, it is important to be able to take into account the complete life cycle, which covers all 3 scopes, with a very important weight of GHG emissions located in scope 3, both on upstream and downstream activities. We have therefore listed below the GHG emission items proposed byAdeme on the 3 scopes and have identified the items considered as the most impacting in the context of measuring the carbon footprint of AI:
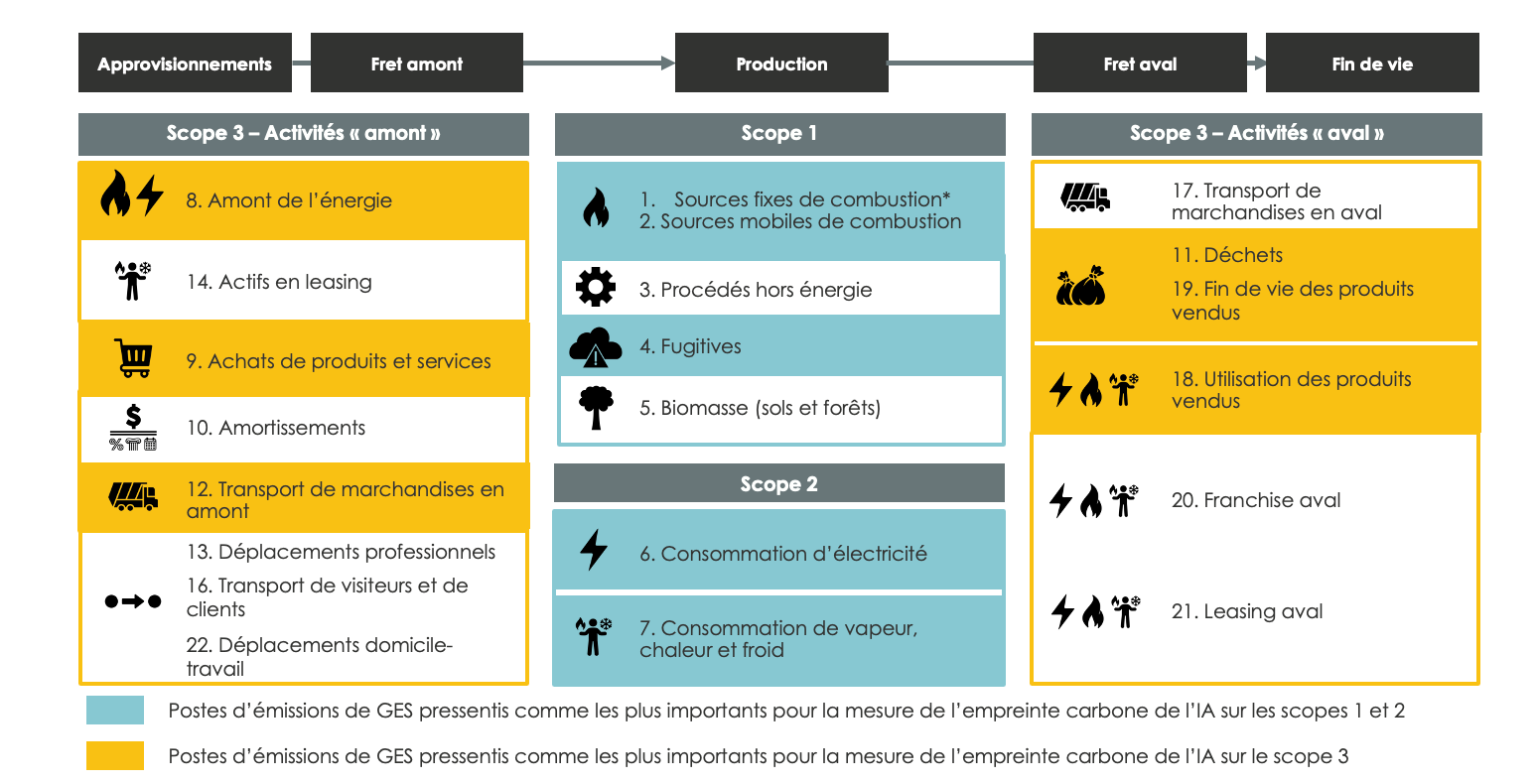
One of the main difficulties in the evaluation of scope 3 is the equipment and infrastructure used by AI projects, which require the consideration of GHG emissions over the entire cycle of this equipment, including:
- Extraction or recycling of raw materials to manufacture new components (CPU, GPU, disk drive,…)
- Assembly of components in servers and equipment
- Transport to the datacenter with different modes (plane, boat, train…)
- Use of these materials to provide services
- Decommissioning (reuse or recycling…)
The measurement of these GHG emissions are highly dependent on the data made available by suppliers and external service providers, particularly through the life cycle analyses of the equipment, including when on-premises infrastructures are involved. However, these analyses are not systematically carried out and/or communicated, especially when dealing with outsourced or Cloud infrastructures.
It should be noted that some Cloud providers such as Microsoft or Google are able to provide their customers with a carbon emission dashboard by geography and specific to their use of Cloud services. For the Microsoft Azure Cloud, for example, the method for calculating GHG emissions on scopes 1, 2 and 3 is broken down into seven steps and based on two main sub-methods, one for calculating carbon emissions at the level of a geographical region, the other for breaking them down at the individual level of each customer based on a unit of use. This data is summarized in a dashboard to create different aggregated views of customer-specific and usage-relevant emissions, including at the scale of specific services, regions, datacenters, and time limits (see Appendix for a summary of the Microsoft Azure Cloud calculation methodology, validated by Stanford University in 2018 and explained in a white paper published in 2021).
Measurement limitations
The accuracy of carbon footprint measurement differs depending on the scope and GHG emission scopes covered, the AI lifecycle stages selected or the calculation method chosen. Also, the information available does not always allow the choice of the most accurate method, which is very dependent on the availability, quality and reliability of activity data. Due to the absence of methodologies recognized and shared by all, there is also a lack of homogeneity and comparability between the data used by companies or those provided by service providers and partners, as in the case of the methodologies proposed by hyperscalers. This strong dependence on external stakeholders for the calculation of the global carbon footprint of AI makes the work more complex and lengthy, especially for the measurement of scope 3 which constitutes the vast majority of GHG emissions.
Thus, measuring the carbon footprint of an IA model is a starting point and a comparison; it is an evolving exercise that tends to improve from year to year with the precision of the methodologies and the publication of new benchmarks and papers / reference studies. It is important to keep in mind that carbon footprint measurements should be interpreted more as orders of magnitude than as perfectly accurate and precise figures, and thus constitute a baseline for comparison and monitoring over time.
3/ Reducing
We propose below some concrete actions to reduce the carbon footprint of AI, throughout the phases of the AI life cycle, in order to initiate and operationalize a Green AI approach.

step #0 – Introduction
- Once the carbon impact measurement has been done, you have a starting point to reduce it and be able to track progress. Publishing the measurement not only raises awareness of environmental impacts but also provides a point of comparison.
- In the good practices of the life cycle of an AI product, we often find documentation. Applied to Green AI, documenting the process and the justification of choices with regard to environmental constraints allows to follow the process, to argue its choices and to disseminate the good practices.
- We propose here a set of measures allowing the reduction of the carbon impact of AI throughout the life cycle. Each one has advantages and disadvantages and a different impact on the reduction of the carbon footprint. These are potential solutions to consider when building AI products.
step #1 – Ideation
- Raise awareness and train employees on the carbon impact of AI: raising awareness allows to understand the consequences and to justify the need to take actions.
- Integrate the measurement and reduction of the carbon footprint in the ethical principles of the company: the reduction of the carbon footprint is a more global process and is part of the company’s strategy. It will then be declined for AI product development.
step #2 – Qualification
- Assessing the value creation of the AI product in relation to environmental impacts:
- Ensure that AI is the right solution for the use case and that another solution with lower carbon footprint and not requiring the use of AI does not exist
- Measure the negative environmental impacts: carbon impact of the development and use of the solution, carbon impact of the current solution
- Evaluate the relevance of the product: contribution to sustainability objectives, response to user needs, reduction of the environmental impact of a process
- Set constraints to limit AI’s carbon impact:
- Sizing the needs and uses according to the user needs and respecting the minimum needs
- Set an environmental budget: carbon budget for training, maximum inference time, carbon impact of the solution in production
- Define a minimum acceptable performance beyond which optimizations will be stopped
step #3 – Development
- Make trade-offs between accuracy and environmental impact, consider model efficiency instead of classical accuracy:
- Identify the most frugal models to meet the need: perform an impact analysis of the different possible solutions, limit the use of Deep Learning, favor less greedy but equally efficient models, favor models that are efficient in terms of memory(example). If scaling is necessary, a small scaling of the model and the data will be less greedy than a large scaling of one or the other.
- Optimize efficiently the hyperparameters of the model to limit the number of trainings: bayesian search or random search (not grid search), reduce the search space of the hyperparameters (number of hyperparameters and possible values), stop the optimization when the minimal performance is reached, Neural architecture search (NAS) and hyperparameter optimization (HPO)
- Start the experiments with a simple algorithm and increase in complexity while evaluating the performance gain in relation to the required resources
- Optimize performance (Throughput (amount of data processed/second in general) and Latency (time needed to process 1 data) to limit consumption and allow deployment in a constrained environment
- Optimize the development environment:
- Choose the optimal infrastructure (on-premise vs. cloud vs. edge) by adopting a global approach to take into account the PUE, the renewable energy supply, but also the rebound effect linked to the use of the cloud and the redundancy used to ensure the robustness of cloud services
- Optimize resources: CPU, GPU, serverless. In fact, just as the software can be thought of in a frugal way, it is also necessary to think about the frugal hardware and therefore the existing infrastructure for the training part. It is also necessary to consider whether we are in a case of machine learning or deep learning. Indeed, processors (CPUs) are already massively deployed in IT infrastructure (data center, cloud, workstations ..) and excel in a wide range of machine learning workloads, which is the need of most companies (versus deep learning). CPUs also excel at low-latency tasks and can handle a large data set that is difficult to split or subsample to fit into gas pedal memory. Where workloads demand it, there is a diverse range of domain-specific gas pedals or GPUs.
- Reuse what already exists:
- Reuse data to avoid multiple storage and processing
- Reuse of algorithms and libraries and their optimization: developers should also think about the case of code reuse on various types of hardware at the edge (on various types of machines or constrained environments such as in trains, cars, terminals, satellites…). In this case, the code could be ported and redeployed on different Hardware (for example from GPU to CPU to XPU) and it is necessary to think about using versatile compilers/tools and libraries (for example: Intel One API), in order to avoid having to rewrite all or part of the code.
- Reuse of already trained models: fine-tuning, Transfer Learning, Incremental Training
- Optimize data storage and use:
- Define and implement a data archiving, expiration and deletion policy
- Limit and optimize data processing, save processed data for reuse without re-processing
- Adapt the storage and format (file format, compression) of data according to usage
- Sample the data to reduce its quantity without compromising performance, the perishability of the data is one of the axes to study(source)
- Think about the target IT infrastructure where the inference will take place (from hardware to edge) and its technical constraints (heat, power, footprint…) :
- Take into account the target IT infrastructure upstream of a project or pilot; often forgotten by developers, this can prevent scaling up because of the energy consumption of the complete solution. If the target infrastructure is, for example, a small box in a train with a few watts of power, it is necessary to think of a target hardware with low power consumption, such as an xPU or CPU.
step #4 – Production and MCO
- Define the SLA (Service Level Agreement) taking into account the sustainability objectives, choose the right resources according to the user constraints (real time, latency, availability…)
- Optimize models for inference (example of tools: Treelite, Hugging Face Infinity, SageMaker Neo…)
- Monitor the model in production and re-train only when necessary (crossing a performance threshold, model or data drift, new data…)
- Integrate environmental impact monitoring as a metric in the monitoring dashboard of the model in production
- Archive or delete unnecessary files: unused versions of the model, log history
step #5 – Usage
- Make users aware of the environmental impacts of the product’s use
- Ensure the usefulness, usability and proper use of the IA product’s features
- Evaluate the opportunities linked to the emergence of new technologies
- Question the relevance of ending the IA product
Sources / to go further
- https://aws.amazon.com/fr/blogs/architecture/optimize-ai-ml-workloads-for-sustainability-part-1-identify-business-goals-validate-ml-use-and-process-data/
- https://aws.amazon.com/fr/blogs/architecture/optimize-ai-ml-workloads-for-sustainability-part-2-model-development/
- https://aws.amazon.com/fr/blogs/architecture/optimize-ai-ml-workloads-for-sustainability-part-3-deployment-and-monitoring/
- AFNOR SPEC 2201
- https://www.statworx.com/en/content-hub/blog/how-to-reduce-the-ai-carbon-footprint-as-a-data-scientist/#:~:text=According%20to%20a%20recent%20estimation,2.4%20Gts%20of%20CO2e.
- https://www.techrxiv.org/articles/preprint/The_Carbon_Footprint_of_Machine_Learning_Training_Will_Plateau_Then_Shrink/19139645
- https://www.carbone4.com/analyse-empreinte-carbone-du-cloud
- Discussions Impact AI
Focus on communication around the Green AI approach: what precautions should be taken?
- Green AI does not mean carbon neutral AI: the concept of Green AI should not be confused with the concept of carbon neutral AI. The notion of carbon neutrality should be used with great care, as Ademe reminds us here: “The objective of carbon neutrality, defined as the arithmetic balance between anthropogenic GHG emissions and sequestrations, only really makes sense on a global scale. Through the Paris Agreement, the States are taking ownership of the objective to enable international coordination of action. The definition of carbon neutrality, as described above, should not be applied at any other scale: sub-national territory, organization (companies, associations, communities, etc.), product or service. Thus, the Impact AI collective strongly recommends not using the notion of “carbon neutral AI” or “carbon neutrality of AI” in the context of Green AI approaches. Any offsets implemented can be presented independently and separately from the total AI carbon footprint measurement, and can in no way be “deducted” from the total emissions calculated in the overall AI carbon footprint measurement.
- Transparency around the objectives of a green AI approach to avoid greenwashing: it is important to communicate in a transparent way on the objectives and underlying of a green AI approach to avoid the pitfalls of greenwashing, by reminding that such an approach certainly contributes to the environmental efficiency but also to the operational efficiency, and must allow to meet the requirements of global performance, at the same time technical, practical, economic and environmental.
Appendix – Microsoft Azure: Summary of the methodology for calculating GHG emissions
Step 1: Calculate emissions for components and hardware
- Upstream emissions include the life cycle stages of component-level manufacturing, storage, and transportation to the Microsoft data center offload dock.
- Downstream material disposal emissions include the disposal, processing and transportation factors for each material component.
Hardware GHG emissions are calculated using emission factors for the different components (disk drives, FPGAs, server blades, racks, power supplies, etc.).
Step 2: Calculate the data center emissions for a given month
The hardware level life cycle emissions from step 1 should be cross-referenced with the hardware supply databases for the data center equipment taking into account an average lifetime (e.g. six years), if the actual lifetime of the equipment extends beyond that, its scope 3 emissions for the extended duration will be zero. If its actual lifetime is shorter, emissions will continue to be accounted for the six-year estimate to ensure full accounting.
Step 3: Calculate the emissions from the data center region
Emissions from individual data centers are aggregated to the regional level. (e.g. a region consisting of 3 availability zones will aggregate the emissions from these 3 data centers.
Step 4: Calculate customer-specific usage emissions
Calculate total customer usage of cloud services based on a normalized cost metric associated with IaaS/PaaS/SaaS services. Total customer utilization includes both direct customer use of resources and a proportionate amount of overhead server capacity dedicated to providing cloud services.
Step 5: Calculate region-specific emission factors.
We divide the total emissions for the region by the total customer usage in that region. The result is a region-specific emission factor per unit of customer usage for a given time period.
Step 6: Calculate total customer-specific emissions
To quantify customer-specific emissions, we multiply a customer’s individual, measured use of services by the region-specific emissions factors calculated in Step 5.
Step 7: Combine and summarize the data
In this step, cloud customers can use the emissions dashboard, create different aggregated views of relevant emissions for specific services, regions, datacenters and time limits.
[1 ] (footnote): The topic of Green AI is constantly evolving and new methods may emerge in the very near term after this paper is released, so we encourage our readers to continue to learn about the latest practices on a regular basis.
Translated from Comment adopter une démarche green AI en entreprise ? La boîte à outils d’Impact AI








