
У короткому : Китайський стартап DeepSeek оновив свою модель R1, покращивши її продуктивність у міркуванні, логіці, математиці та програмуванні. Це оновлення, яке зменшує помилки та покращує інтеграцію додатків, дозволяє R1 конкурувати з флагманськими моделями, такими як o3 від Open AI та Gemini 2.5 Pro від Google.
Зміст
Хоча спекуляції навколо наступного запуску DeepSeek R2 були в розпалі, зрештою китайський стартап оголосив 28 травня про оновлення моделі R1. Назване DeepSeek-R1-0528, це оновлення підсилює можливості R1 в ключових областях, таких як міркування, логіка, математика та програмування. Тепер продуктивність цієї моделі з відкритим кодом, опублікованої під ліцензією MIT, наближається до флагманських моделей, як-от o3 від Open AI та Gemini 2.5 Pro від Google.
Значні вдосконалення в управлінні складними завданнями міркування
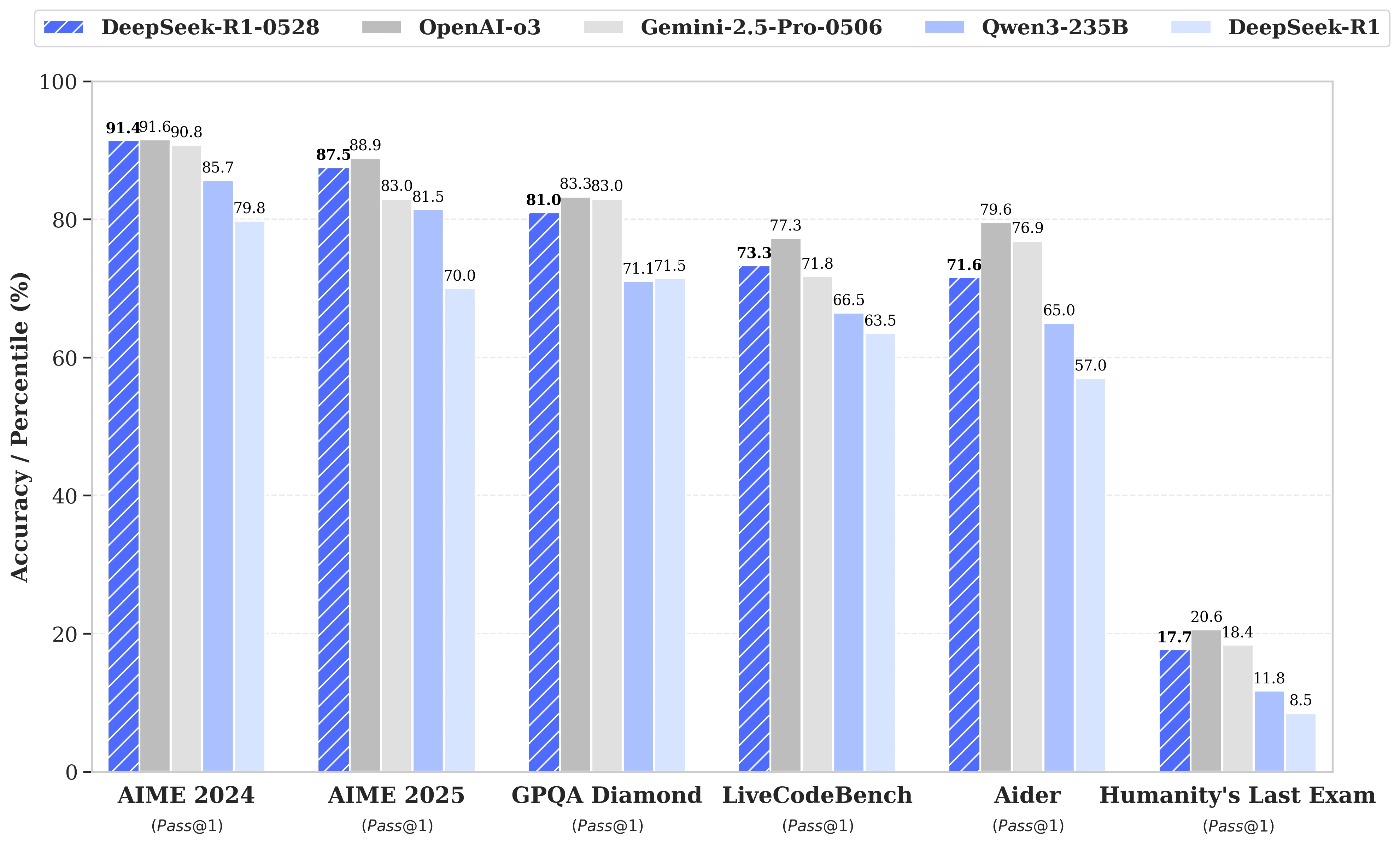
Оновлення базується на більш ефективному використанні доступних обчислювальних ресурсів, у поєднанні з серією алгоритмічних оптимізацій, реалізованих після навчання. Ці зміни призводять до підвищення глибини рефлексії під час міркування: тоді як попередня версія в середньому споживала 12 000 токенів на питання в тестах AIME, DeepSeek-R1-0528 тепер використовує близько 23 000, з помітним покращенням точності з 70 % до 87,5 % на виданні тесту 2025 року.
- У математиці зареєстровані бали досягають 91,4 % (AIME 2024) і 79,4 % (HMMT 2025), досягаючи або перевершуючи продуктивність деяких закритих моделей, таких як o3 або Gemini 2.5 Pro;
- У програмуванні індекс LiveCodeBench підвищився майже на 10 пунктів (з 63,5 до 73,3 %), а оцінка SWE Verified зросла з 49,2 % до 57,6 % успіху;
- У загальному міркуванні тест GPQA-Diamant демонструє, що бал моделі зріс з 71,5 % до 81,0 %, тоді як для еталону "Останній іспит людства" він більше ніж подвоївся, з 8,5 % до 17,7 %.
Зменшення помилок та краща інтеграція додатків
Серед значних змін, що приніс цей апдейт, варто відзначити суттєве зменшення рівня галюцинацій, критичний аспект для надійності LLMs. Зменшуючи частоту фактично неточних відповідей, DeepSeek-R1-0528 стає більш стійким, особливо в контекстах, де точність є необхідною.
Оновлення також вводить функції, орієнтовані на використання в структурованому середовищі, зокрема, пряму генерацію виходів у форматі JSON та розширену підтримку виклику функцій. Ці технічні вдосконалення спрощують інтеграцію моделі в автоматизовані робочі процеси, програмні агенти або бекенд-системи, без необхідності в складній проміжній обробці.
Зростаюча увага до дистиляції
Паралельно, команда DeepSeek розпочала процес дистиляції ланцюгів мислення до легших моделей для розробників або дослідників з обмеженим обладнанням. DeepSeek-R1-0528, що має 685 B (мільярдів) параметрів, був використаний для пост-тренування Qwen3 8B Base.
Отримана модель, DeepSeek-R1-0528-Qwen3-8B, змогла зрівнятися з набагато більшими моделями з відкритим кодом на деяких еталонах. З результатом 86,0 % на AIME 2024, вона перевершує Qwen3 8B більш ніж на 10,0 % і зрівнюється з продуктивністю Qwen3-235B-thinking.
Цей підхід ставить під питання майбутню життєздатність масивних моделей у порівнянні з більш ощадливими, але краще навченими міркувати версіями.
DeepSeek стверджує:
"Ми вважаємо, що ланцюг мислення DeepSeek-R1-0528 буде мати значний вплив як для академічних досліджень моделей міркування, так і для промислового розвитку, орієнтованого на моделі малого масштабу".