
Kısa : Çinli girişim DeepSeek, R1 modelini güncelleyerek mantık, matematik ve programlama alanlarındaki performansını artırdı. Bu güncelleme, hataları azaltarak ve uygulama entegrasyonunu geliştirerek R1'in, Open AI'nin o3 ve Google'ın Gemini 2.5 Pro gibi amiral gemisi modelleriyle rekabet etmesini sağlıyor.
İçindekiler
Spekülasyonlar DeepSeek R2'nin bir sonraki lansmanı etrafında dönerken, nihayetinde Çinli girişim, 28 Mayıs'ta R1 modelinin bir güncellemesini duyurdu. DeepSeek-R1-0528 olarak adlandırılan bu versiyon, R1'in mantık, matematik ve programlama gibi kilit alanlardaki yeteneklerini güçlendiriyor. Artık, MIT lisansı altında yayınlanan bu açık kaynak modeli, Open AI'nin o3 ve Google'ın Gemini 2.5 Pro gibi amiral gemisi modellerine daha da yaklaşıyor.
Karmaşık akıl yürütme görevlerinin yönetiminde önemli iyileştirmeler
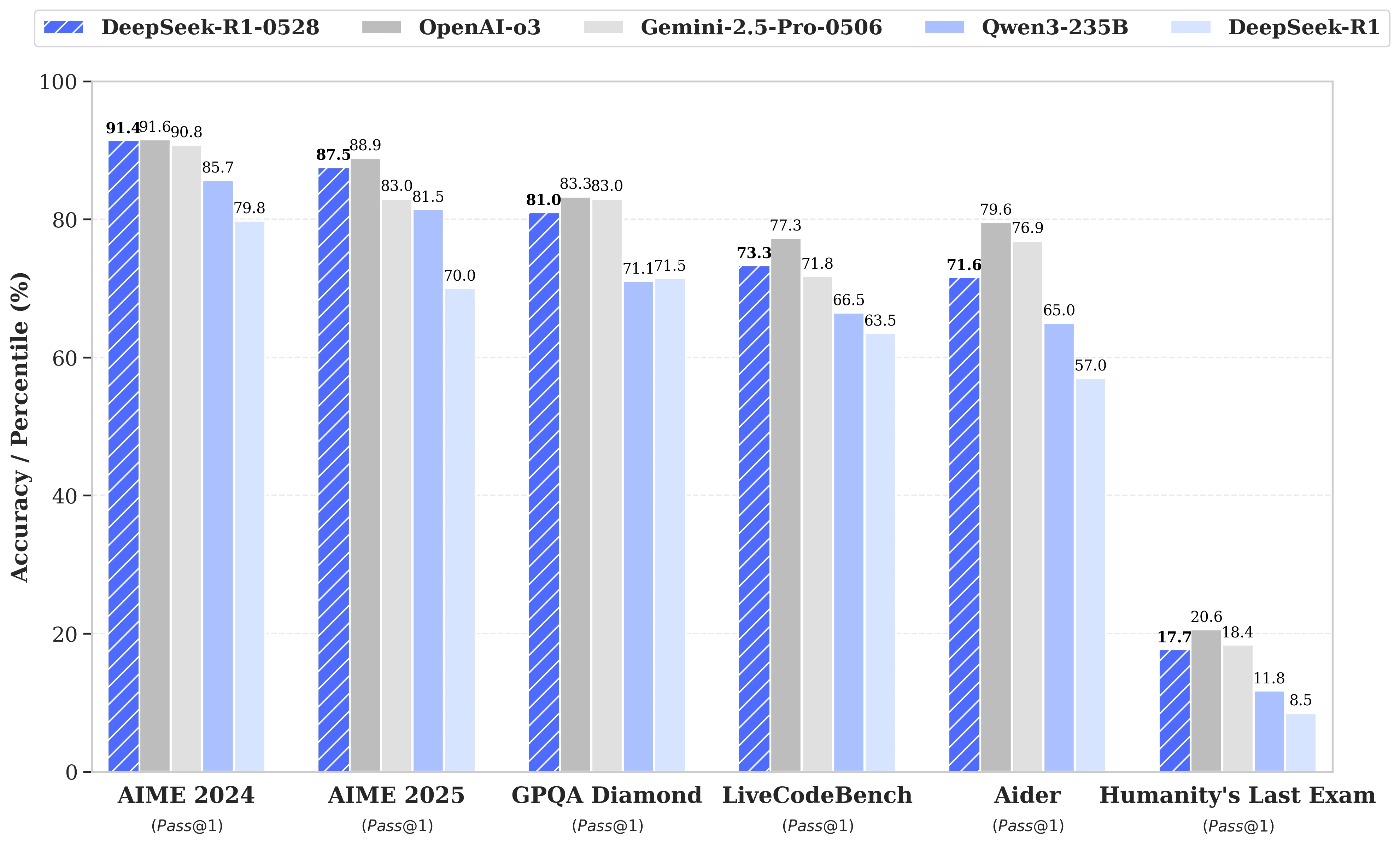
Güncelleme, mevcut hesaplama kaynaklarının daha etkili bir şekilde kullanılmasına dayanıyor ve eğitim sonrası uygulanan bir dizi algoritmik optimizasyon ile birleştiriliyor. Bu ayarlamalar, akıl yürütme sırasında derinlemesine bir düşünce artışı sağlıyor: önceki versiyon AIME testlerinde soru başına ortalama 12.000 jeton tüketirken, DeepSeek-R1-0528 şimdi yaklaşık 23.000 jeton kullanıyor ve 2025 testinde doğrulukta %70'ten %87,5'e kayda değer bir ilerleme sağlıyor.
- Matematikte, kaydedilen skorlar, AIME 2024'te %91,4 ve HMMT 2025'te %79,4'e ulaşıyor; bu, bazı kapalı modellerin performanslarıyla eşitleniyor veya onları aşıyor;
- Programlamada, LiveCodeBench endeksi neredeyse 10 puan (63,5'ten 73,3'e) artıyor ve SWE Doğrulama değerlendirmesi %49,2'den %57,6 başarıya yükseliyor;
- Genel akıl yürütmede, GPQA-Diamant testi, modelin puanını %71,5'ten %81,0'e yükseltiyor ve "İnsanoğlunun Son Sınavı" benchmark'ı için puanı %8,5'ten %17,7'ye iki katından fazla çıkıyor.
Hataların azaltılması ve daha iyi uygulama entegrasyonu
Bu güncellemenin getirdiği önemli değişiklikler arasında, LLM'lerin güvenilirliği için kritik bir konu olan halüsinasyon oranının belirgin bir şekilde azaltılması yer alıyor. Yanıtların gerçekte yanlış olma sıklığını azaltarak, DeepSeek-R1-0528, özellikle doğruluğun vazgeçilmez olduğu bağlamlarda, sağlamlık kazanıyor.
Güncelleme ayrıca yapılandırılmış ortamda kullanım için doğrudan JSON formatında çıktı oluşturma ve genişletilmiş fonksiyon çağrısı desteği gibi özellikler de sunuyor. Bu teknik ilerlemeler, modeli otomatikleştirilmiş iş akışlarına, yazılım ajanlarına veya arka uç sistemlerine entegre etmeyi, ağır ara işlemler gerektirmeden basitleştiriyor.
Distilasyona artan bir dikkat
Paralel olarak, DeepSeek ekibi, daha hafif modeller için düşünce zincirlerinin distilasyonuna yönelik bir süreç başlattı ve bu, sınırlı donanıma sahip geliştiriciler veya araştırmacılar için yapılmıştır. 685 milyar parametreye sahip DeepSeek-R1-0528, Qwen3 8B Base'i post-eğitmek için kullanıldı.
Sonuçta ortaya çıkan model, DeepSeek-R1-0528-Qwen3-8B, bazı benchmarklarda çok daha büyük açık kaynak modellerle eşitlenen bir performans sergiliyor. AIME 2024'te %86,0'lık bir puanla, sadece Qwen3 8B'nin puanını %10,0'dan fazla geçmekle kalmıyor, aynı zamanda Qwen3-235B-thinking'in performansına da eşitleniyor.
Bu yaklaşım, daha iyi düşünme yeteneği ile eğitilen daha az kaynak tüketen versiyonlar karşısında, büyük modellerin gelecekteki sürdürülebilirliğini sorgulatıyor.
DeepSeek şunu belirtiyor:
"DeepSeek-R1-0528'in düşünce zincirinin, hem akademik araştırmalarda akıl yürütme modelleri üzerine hem de küçük ölçekli modellere odaklanan endüstriyel geliştirme için önemli bir rol oynayacağını düşünüyoruz."