Alibaba, 21 Temmuz'da X üzerinde yaptığı duyuruda LLM Qwen 3'ün son güncellemesi olan Qwen3-235B-A22B-Instruct-2507'yi yayınladığını açıkladı. Apache 2.0 lisansı altında dağıtılan açık kaynaklı model, 235 milyar parametreye sahip ve DeepSeek‑V3, Anthropic'in Claude Opus 4, OpenAI'nin GPT-4o veya Çinli start-up Moonshot tarafından yakın zamanda başlatılan Kimi 2 gibi dört kat daha büyük modellerle ciddi bir rakip olarak öne çıkıyor.
Alibaba Cloud, gönderisinde şunları belirtti:
"Toplulukla görüştükten ve konuyu düşündükten sonra, hibrit düşünce modunu bırakmaya karar verdik. Artık Instruct ve Thinking modellerini ayrı ayrı eğiteceğiz, böylece en iyi kaliteyi elde edebiliriz."
Qwen3-235B-A22B-Instruct-2507 non-thinking bir modeldir, yani karmaşık zincirleme akıl yürütme gerçekleştirmez, ancak talimatların yerine getirilmesinde hız ve uygunluğa öncelik verir.
Bu stratejik yönelim sayesinde, Qwen 3 sadece talimatların takibinde ilerlemekle kalmaz, aynı zamanda mantıksal akıl yürütme, uzmanlaşmış alanların ince anlaşılması, nadir dillerin işlenmesi, matematik, bilim, programlama ve dijital araçlarla etkileşimde de ilerlemeler gösterir.
Açık uçlu görevlerde, yargı, ton veya yaratıcılık içerdiğinde, kullanıcı beklentilerine daha iyi uyum sağlar, daha yararlı yanıtlar ve daha doğal bir üretim tarzı sunar.
256.000 token'a çıkarılan bağlam penceresi sekiz kat artırılmış olup, artık büyük belgeleri işleyebilir.
Esneklik ve Verimlilik Odaklı Bir Mimari
Model, 128 uzman içeren Mixture-of-Experts (MoE) mimarisi üzerine kuruludur, bunlardan 8'i talebe bağlı olarak seçilir: 235 milyar parametresinin sadece 22 milyarı bir istekle etkinleştirilir.
94 derinlik katmanına ve optimize edilmiş bir GQA (Grouped Query Attention) şemasına dayanır: sorgu (Q) için 64 baş ve anahtarlar/değerler için 4 baş.
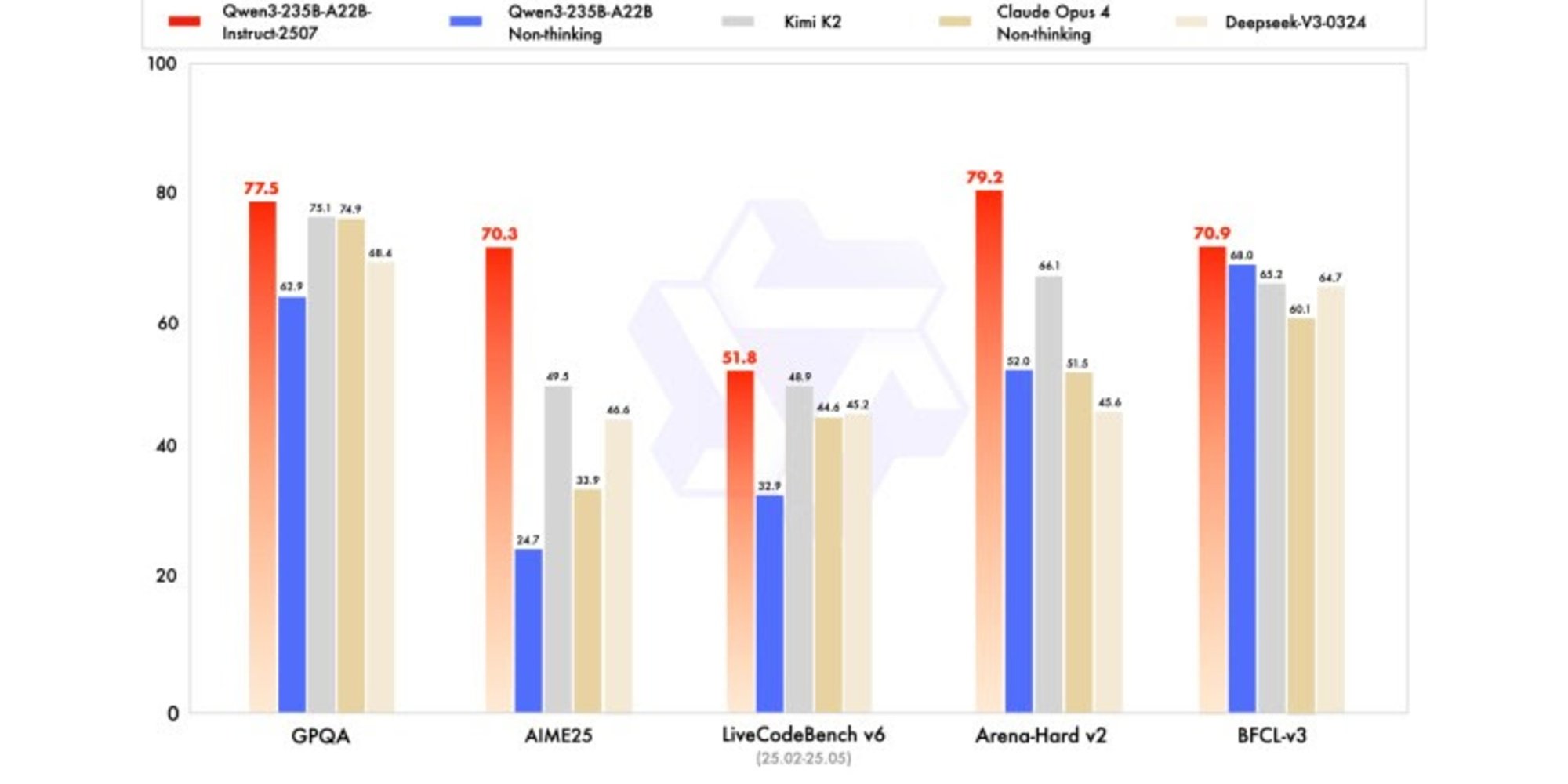
Qwen3‑235B‑A22B‑Instruct‑2507'nin Performansı
Yeni sürüm, lider rakip modellerle karşılaştırıldığında, özellikle matematik, kodlama ve mantıksal akıl yürütme alanlarında rekabetçi, hatta üstün sonuçlar göstermektedir.
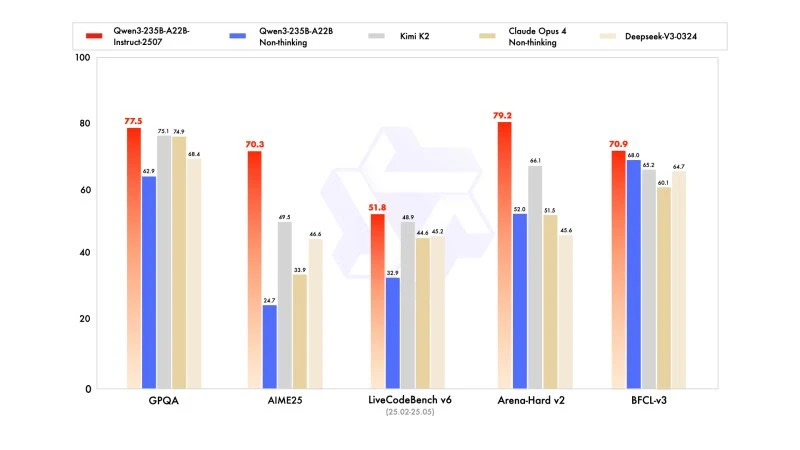
Genel bilgi alanında, MMLU-Pro'da 83,0 puan almış (önceki sürümde 75,2 karşı) ve MMLU-Redux'ta 93,1 puan alarak Claude Opus 4'ün (94,2) seviyesine yaklaşmıştır.
Gelişmiş akıl yürütme konusunda, matematik modellemesinde çok yüksek bir skor elde etmiştir: AIME (American Invitational Mathematics Examination) 2025'te 70,3 puan alarak, DeepSeek-V3-0324'ün 46,6 ve OpenAI'nin GPT-4o-0327'sinin 26,7 puanlarını aşmıştır.
Kodlama konusunda, MultiPL‑E'deki 87,9 puanı ile Claude'un (88,5) arkasında, ancak GPT-4o ve DeepSeek'in önündedir. LiveCodeBench v6'da, bu benchmark'ta ölçülen en iyi performans olan 51,8 puana ulaşmıştır.
FP8'de Nicelenmiş Sürüm: Optimizasyon Tavizsiz
Qwen3-235B-A22B-Instruct-2507 ile eşzamanlı olarak, Alibaba, FP8'de nicelenmiş sürümünü yayınladı. Bu sıkıştırılmış dijital format, bellek ihtiyaçlarını önemli ölçüde azaltır ve çıkarımı hızlandırır, bu da modelin kaynakların sınırlı olduğu ortamlarda çalışmasına olanak tanır, önemli bir performans kaybı olmadan.