TLDR : Google의 연구원들이 MLE-STAR라는 머신러닝 에이전트를 개발하여, 웹 검색, 코드 개선 및 적응형 조립을 통해 AI 모델 생성 프로세스를 향상시켰습니다. 이 에이전트는 Kaggle을 기반으로 한 MLE-Bench-Lite 벤치마크에서 63%의 대회에서 우승하여 이전 접근법을 크게 능가했습니다.
목록
대형 언어 모델(LLMs)을 기반으로 한 MLE(Machine Learning Engineering agent) 에이전트는 머신러닝 모델 개발에서 전체 또는 일부 프로세스를 자동화하여 새로운 가능성을 열어주었습니다. 하지만 기존 솔루션은 탐색 한계나 방법론적 다양성 부족에 자주 부딪힙니다. Google의 연구원들은 MLE-STAR라는 에이전트를 통해 이러한 도전에 대응하고 있으며, 이는 웹 검색, 코드 블록의 세분화된 개선 및 적응형 조립 전략을 결합합니다.
구체적으로, MLE 에이전트는 작업 설명(예: "테이블형 데이터를 기반으로 매출 예측")과 제공된 데이터 세트를 시작점으로 사용하여 다음을 수행합니다:
- 문제를 분석하고 적절한 접근법을 선택합니다;
- 코드를 생성합니다(주로 Python을 사용하며, 일반 또는 전문화된 ML 라이브러리를 사용);
- 해결책을 테스트하고 평가하며, 필요에 따라 여러 번 개선합니다.
이 에이전트는 LLM의 두 가지 주요 역량에 의존합니다:
- 알고리즘적 추론(주어진 문제에 대한 적절한 방법 식별);
- 실행 가능한 코드 생성(데이터 준비, 교육 및 평가에 대한 완전한 스크립트).
이들의 목표는 피처 엔지니어링, 하이퍼파라미터 조정 또는 모델 선택과 같은 지루한 단계를 자동화하여 인간의 작업 부담을 줄이는 것입니다.
MLE-STAR: 목표 지향적이고 반복적인 최적화
Google Research에 따르면 기존 MLE는 두 가지 주요 장애물에 직면합니다. 첫 번째로, LLM의 내부 지식에 대한 강한 의존성으로 인해, 일반적이고 잘 확립된 방법(예: 테이블형 데이터에 대한 scikit-learn 라이브러리)을 우선시하게 되며, 이는 더 전문적이고 잠재적으로 더 성능이 좋은 접근법을 소외시킵니다.
두 번째로, 탐색 전략이 각 반복에서 코드의 완전한 재작성을 기반으로 하므로, 파이프라인의 특정 구성 요소에 집중할 수 없습니다. 예를 들어, 피처 엔지니어링의 다양한 옵션을 체계적으로 테스트하여 다른 단계로 넘어가기 전에 이들을 탐색할 수 있습니다.
두 번째로, 탐색 전략이 각 반복에서 코드의 완전한 재작성을 기반으로 하므로, 파이프라인의 특정 구성 요소에 집중할 수 없습니다. 예를 들어, 피처 엔지니어링의 다양한 옵션을 체계적으로 테스트하여 다른 단계로 넘어가기 전에 이들을 탐색할 수 있습니다.
이러한 한계를 극복하기 위해, Google 연구원들은 MLE-STAR라는 에이전트를 설계했으며, 이는 세 가지 레버를 결합합니다:
- 웹 검색을 통해 작업에 특화된 모델을 식별하고 강력한 초기 솔루션을 구성합니다;
- 코드 블록별 세분화된 개선을 통해, 성능에 가장 큰 영향을 미치는 부분을 식별하고 이를 반복적으로 최적화합니다;
- 적응형 조립 전략을 통해 여러 후보 솔루션을 하나의 개선된 버전으로 통합하며, 시도할수록 더 정교해집니다.
이 반복적인 프로세스, 즉 검색, 중요 블록 식별, 최적화, 그리고 새로운 반복은 MLE-STAR가 가장 측정 가능한 이득을 제공하는 부분에 노력을 집중하게 합니다.
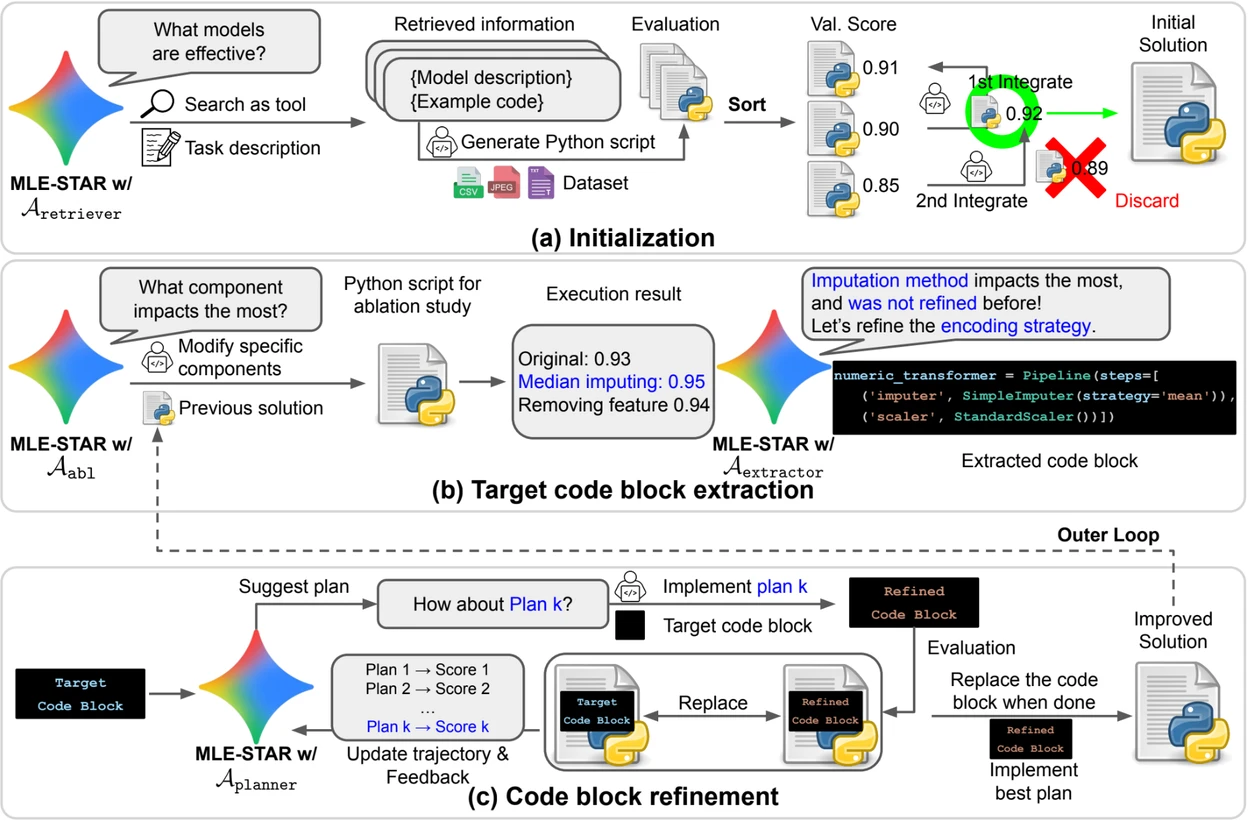
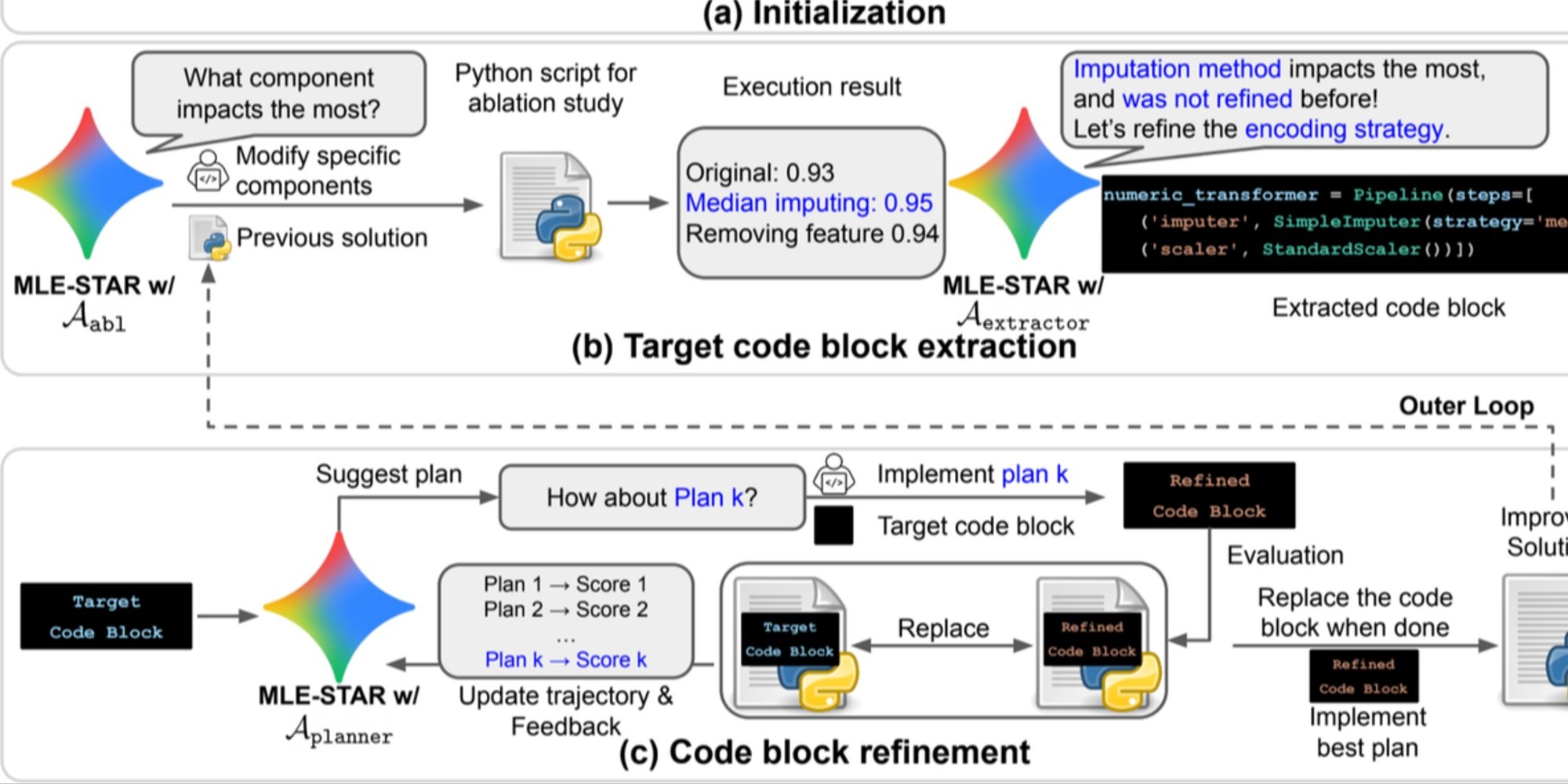
크레딧: Google Research.
개요. a) MLE-STAR는 웹 검색을 사용하여 특정 작업에 맞는 모델을 찾아 초기 솔루션에 통합합니다. (b) 각 개선 단계에서, 성능에 가장 큰 영향을 미치는 코드 블록을 결정하기 위해 절단 연구를 수행합니다. (c) 식별된 코드 블록은 이전 실험의 피드백을 사용하여 다양한 전략을 탐색하는 LLM이 제안한 계획을 기반으로 반복적으로 개선됩니다. 이 코드 블록 선택 및 개선 프로세스는 반복되며, (c)의 개선된 솔루션은 다음 개선 단계의 출발점이 됩니다(b).
솔루션의 신뢰성을 강화하기 위한 제어 모듈
반복적인 접근 외에도, MLE-STAR는 생성된 솔루션의 견고성을 강화하기 위한 세 가지 모듈을 통합합니다:
- 디버깅 에이전트는 실행 오류(예: Python traceback)를 분석하고 자동 수정 제안을 제공합니다;
- 데이터 누출 검증기는 테스트 데이터에서 발생한 정보가 잘못되어 훈련 시 사용되는 상황을 탐지하여 측정된 성능을 왜곡하는 편향을 방지합니다;
- 데이터 사용 검증기는 제공된 모든 데이터 소스를 활용하고, CSV와 같은 표준 형식이 아닌 경우에도 이를 보장합니다.
이 모듈들은 LLM이 생성한 코드에서 관찰된 일반적인 문제에 대응합니다.
Kaggle에서의 의미 있는 결과
MLE-STAR의 효과를 평가하기 위해, 연구원들은 이를 Kaggle 경연 대회를 기반으로 한 MLE-Bench-Lite 벤치마크에서 테스트했습니다. 이 프로토콜은 간단한 작업 설명에서 시작하여 완전하고 경쟁력 있는 솔루션을 생산하는 능력을 측정했습니다.
결과는 MLE-STAR가 경연 대회의 63%에서 메달을 획득하며, 이 중 36%는 금메달을 획득했음을 보여줍니다. 이는 이전 최고의 접근법이 25.8%에서 36.6%인 것과 비교됩니다. 이 이득은 EfficientNet 또는 ViT와 같은 최신 모델의 빠른 채택, 웹 검색으로 식별되지 않은 모델을 인간의 일시적인 개입을 통해 통합하는 능력, 그리고 데이터 누출 및 사용 검증기가 제공하는 자동 수정의 결합 덕분입니다.
arXiv에서 과학 논문을 확인하세요 : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
오픈 소스 코드는 GitHub에서 이용할 수 있습니다