
TLDR : 중국 스타트업 DeepSeek는 R1 모델을 업데이트하여 추론, 논리, 수학 및 프로그래밍에서의 성능을 개선했습니다. 이 업데이트는 오류를 감소시키고 애플리케이션 통합을 개선하여, R1이 Open AI의 o3 및 Google의 Gemini 2.5 Pro와 같은 주력 모델과 경쟁할 수 있도록 합니다.
목록
DeepSeek R2의 다음 출시를 둘러싼 추측이 무성한 가운데, 중국의 동명 스타트업은 결국 지난 5월 28일 R1 모델의 업데이트를 발표했습니다. DeepSeek-R1-0528로 명명된 이 버전은 R1의 추론, 논리, 수학 및 프로그래밍과 같은 핵심 분야에서의 역량을 강화합니다. 이제 MIT 라이선스로 공개된 이 오픈 소스 모델의 성능은 Open AI의 o3 및 Google의 Gemini 2.5 Pro와 같은 주력 모델에 근접합니다.
복잡한 추론 작업 관리에서의 상당한 개선
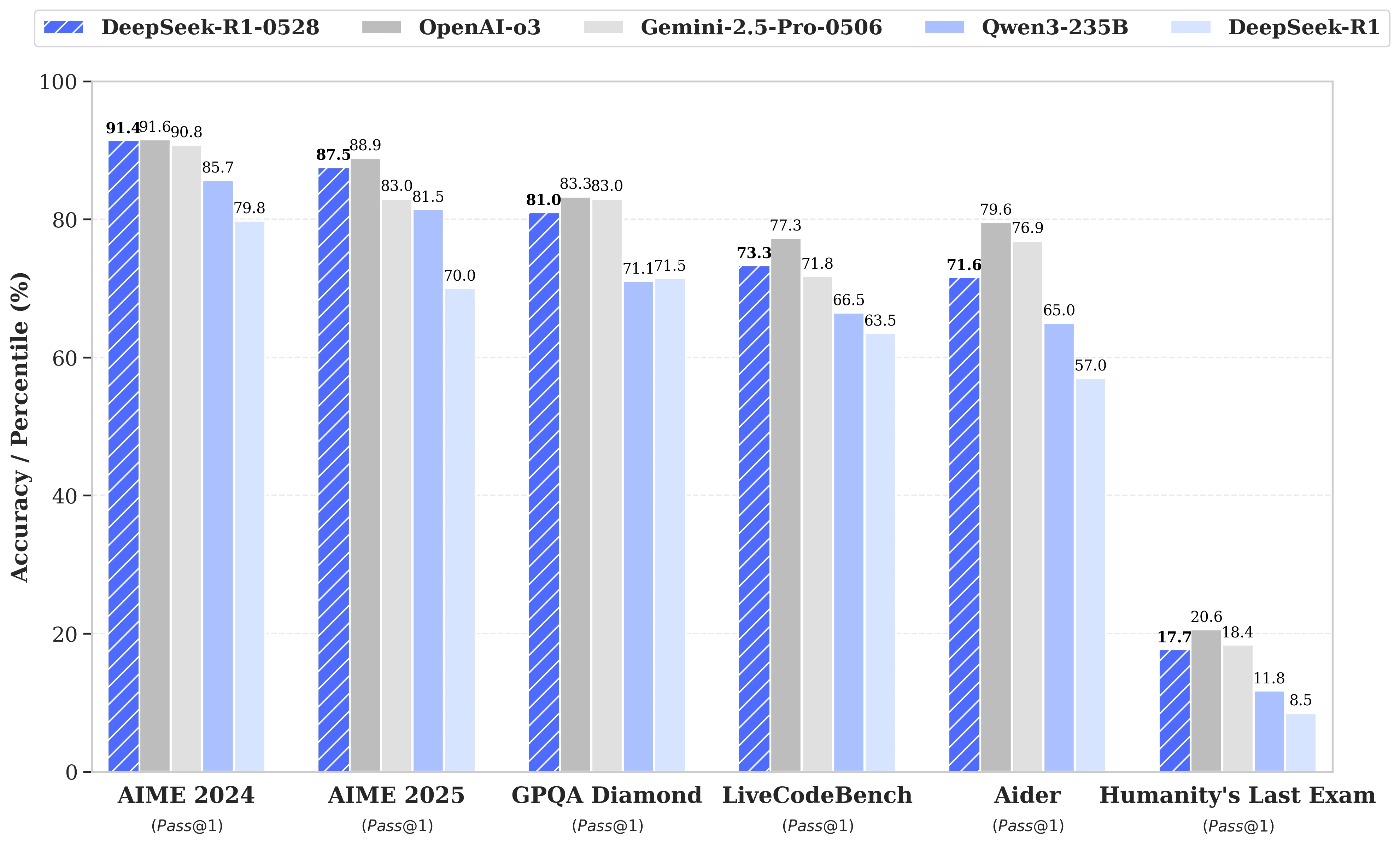
업데이트는 사용 가능한 계산 자원의 보다 효율적인 활용과 포스트 트레이닝에서 구현된 일련의 알고리즘 최적화에 기반합니다. 이러한 조정은 추론 시 더 깊은 사고를 가능하게 하며, 이전 버전이 AIME 테스트에서 질문당 평균 12,000개의 토큰을 소모하던 것에 비해, DeepSeek-R1-0528은 이제 약 23,000개의 토큰을 사용하며, 2025년 테스트에서 정확도가 70%에서 87.5%로 눈에 띄게 향상되었습니다.
- 수학에서는 AIME 2024에서 91.4%, HMMT 2025에서 79.4%의 점수를 기록하며, o3나 Gemini 2.5 Pro와 같은 일부 폐쇄형 모델의 성능을 넘기거나 근접했습니다;
- 프로그래밍에서는 LiveCodeBench 지수가 63.5%에서 73.3%로 약 10포인트 상승하였고, SWE Verified 평가는 49.2%에서 57.6%로 성공률이 올랐습니다;
- 일반 추론에서는 GPQA-Diamant 테스트에서 모델의 점수가 71.5%에서 81.0%로 올랐고, "인류의 마지막 시험" 벤치마크에서는 8.5%에서 17.7%로 두 배 이상 증가했습니다.
오류 감소 및 애플리케이션 통합 개선
이번 업데이트로 인한 주목할 만한 발전 중 하나는 환각율의 현저한 감소로, LLM의 신뢰성에 있어 중요한 문제입니다. 사실적으로 부정확한 응답의 빈도를 줄임으로써 DeepSeek-R1-0528은 특히 정확도가 필수적인 상황에서 강력성을 확보합니다.
업데이트는 또한 구조적 환경에서의 사용을 위한 기능을 도입하였으며, 특히 JSON 형식의 출력 생성과 함수 호출 지원을 확대했습니다. 이러한 기술적 진보는 모델을 자동화된 워크플로, 소프트웨어 에이전트 또는 백엔드 시스템에 통합하는 것을 쉽게 하며, 무거운 중간 처리를 필요로 하지 않습니다.
증류에 대한 증가하는 관심
동시에, DeepSeek의 팀은 제한된 하드웨어를 가진 개발자나 연구자들을 위해 더 가벼운 모델로 사고의 사슬을 증류하는 방법에 착수하였습니다. DeepSeek-R1-0528은 685 B(십억)개의 매개변수를 갖추고 있으며, Qwen3 8B Base를 후속 훈련하는 데 사용되었습니다.
결과 모델인 DeepSeek-R1-0528-Qwen3-8B는 일부 벤치마크에서 훨씬 더 부피가 큰 오픈 소스 모델과 동등한 성능을 발휘합니다. AIME 2024에서 86.0%의 점수를 기록하며, 이는 Qwen3 8B보다 10.0% 이상 높고, Qwen3-235B-thinking의 성능과 동등합니다.
이 접근 방식은 더 적은 자원을 소모하면서도 더 잘 훈련된 추론 모델이 대형 모델의 미래 가능성에 대해 의문을 제기합니다.
DeepSeek는 이렇게 말합니다:
"DeepSeek-R1-0528의 사고의 사슬은 추론 모델에 대한 학술 연구와 소규모 모델에 초점을 맞춘 산업 개발 모두에 있어 중요한 의미를 가질 것이라고 생각합니다."