Alibaba는 지난 7월 21일 X를 통해 LLM Qwen 3의 최신 업데이트인 Qwen3-235B-A22B-Instruct-2507을 발표했습니다. 이 오픈 소스 모델은 Apache 2.0 라이선스 하에 배포되며, 2350억 개의 매개변수를 포함하여 DeepSeek‑V3, Anthropic의 Claude Opus 4, OpenAI의 GPT-4o, 최근 중국 스타트업 Moonshot에서 출시한 Kimi 2에 비해 네 배 더 큰 모델로서 강력한 경쟁자로 자리매김하고 있습니다.
Alibaba Cloud는 게시물에서 다음과 같이 밝혔습니다:
"커뮤니티와의 논의 및 심사숙고 끝에, 우리는 하이브리드 사고 모드를 포기하기로 결정했습니다. 이제부터 Instruct 모델과 Thinking 모델을 각각 별도로 훈련하여 가능한 최고의 품질을 추구할 것입니다."
Qwen3-235B-A22B-Instruct-2507은 비사고(non-thinking) 모델로, 복잡한 연쇄적 추론을 수행하지 않고 명령 실행에서 속도와 적합성을 중시합니다.
이 전략적 방향 덕분에 Qwen 3는 명령 수행에서의 발전을 넘어 논리적 추론, 전문 분야에 대한 세밀한 이해, 드문 언어 처리, 수학, 과학, 프로그래밍 및 디지털 도구와의 상호작용에서도 진전을 보입니다.
개방형 작업에서, 판단, 톤 또는 창작을 포함하는 경우, 사용자 기대에 더 잘 부합하고 더 유용한 응답과 자연스러운 생성 스타일을 제공합니다.
컨텍스트 창은 256,000 토큰으로 8배 증가하여 대용량 문서를 처리할 수 있게 되었습니다.
유연성과 효율성을 지향하는 아키텍처
모델은 128명의 전문 전문가로 구성된 Mixture-of-Experts (MoE) 아키텍처를 기반으로 하며, 요청에 따라 8명이 선택됩니다: 2350억 개의 매개변수 중 220억 개만이 요청에 의해 활성화됩니다.
94층의 깊이, 최적화된 GQA (Grouped Query Attention) 체계를 기반으로 하며, 쿼리(Q)를 위해 64개의 헤드와 키/값을 위해 4개의 헤드를 사용합니다.
Qwen3‑235B‑A22B‑Instruct‑2507의 성능
새로운 버전은 수학, 코딩 및 논리적 추론에서 경쟁 모델보다 높은 성능을 보여줍니다.
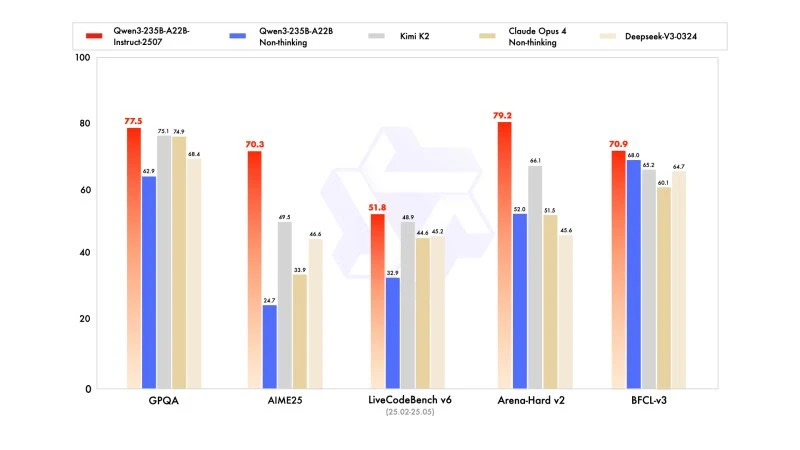
일반 지식에서는 MMLU-Pro에서 83.0점 (이전 버전의 75.2점) 및 MMLU-Redux에서 93.1점을 획득하여 Claude Opus 4 (94.2점) 수준에 근접했습니다.
고급 추론에서는 수학 모델링에서 높은 점수를 기록했으며: AIME (American Invitational Mathematics Examination) 2025에서 70.3점을 기록하여 DeepSeek-V3-0324의 46.6점과 OpenAI의 GPT-4o-0327의 26.7점을 넘어섰습니다.
코딩에서는 MultiPL-E에서 87.9점을 기록하여 Claude (88.5) 뒤에, 그러나 GPT-4o 및 DeepSeek보다 앞서 있습니다. LiveCodeBench v6에서는 51.8점을 기록하여 이 벤치마크에서 측정된 최고의 성능을 보여주었습니다.
FP8로 양자화된 버전: 타협 없는 최적화
Qwen3-235B-A22B-Instruct-2507과 함께, Alibaba는 FP8로 양자화된 버전을 발표했습니다. 이 압축된 디지털 형식은 메모리 요구 사항을 크게 줄이고 추론 속도를 가속화하여, 리소스가 제한된 환경에서도 모델을 실행할 수 있게 하면서도 성능 손실을 초래하지 않습니다.