
TLDR : Mistral AIがVoxtralを発表し、音声モデル分野に参入。Voxtralは、プロフェッショナル向けの音声理解モデルで、OpenAIやMetaのような大手に対抗するものです。
目次
先週の火曜日、Mistral AIは、初のオープンソース音声モデルファミリーであるVoxtralの発売を発表しました。プロフェッショナルな用途向けに設計されたこれらの音声理解モデルは、OpenAI、Meta、Googleといった企業が支配していた戦略的な音声インテリジェンス分野へのフランスのユニコーン企業の参入を示しています。
Voxtralシリーズは、主に2つのモデルで構成されています。Voxtral Small(240億パラメータ)とVoxtral Mini(30億パラメータ)で、それぞれ異なる環境を対象としています。Smallモデルは複雑なケースや大規模なクラウド展開に、Miniバージョンは組み込みやリソースが限られた展開に最適化されています。Mistral AIはまた、音声トランスクリプション専用に最適化されたVoxtral Mini Transcribeも提供しており、Whisperのようなモデルと比較して優れたコストパフォーマンスを実現しています。
トランスクリプションを超える機能
Voxtralは、信頼性の低いASR(自動音声認識)システムや高価なクローズドAPIの代替を目指しています。
長時間の音声コンテキストを処理するよう設計されており、32,000トークンのウィンドウで最大30分のトランスクリプションまたは40分の理解を管理できます。
Mistral Small 3.1言語モデルのアーキテクチャに基づいており、音声によるリクエストに応答し、音声ファイルから要約を生成したり、音声で表現された意図をAPI呼び出しやバックエンドフローに変換したりすることが可能です。モデルは、英語、スペイン語、アラビア語、フランス語、ポルトガル語、ヒンディー語、ドイツ語、オランダ語、イタリア語など、広く使われている言語をサポートしています。
最先端のパフォーマンス
Mistralによる初期評価によれば、Voxtral SmallはWhisper v3だけでなく、Gemini 2.5 FlashやOpenAIのGPT-4o Mini Transcribeを複数の自動トランスクリプションメトリクスで上回り、リソース消費を抑えています。
FLEURS(下記参照)では、Voxtral Smallはテストされたすべての言語で最先端のパフォーマンスを示し、Whisperを上回る精度を誇ります。
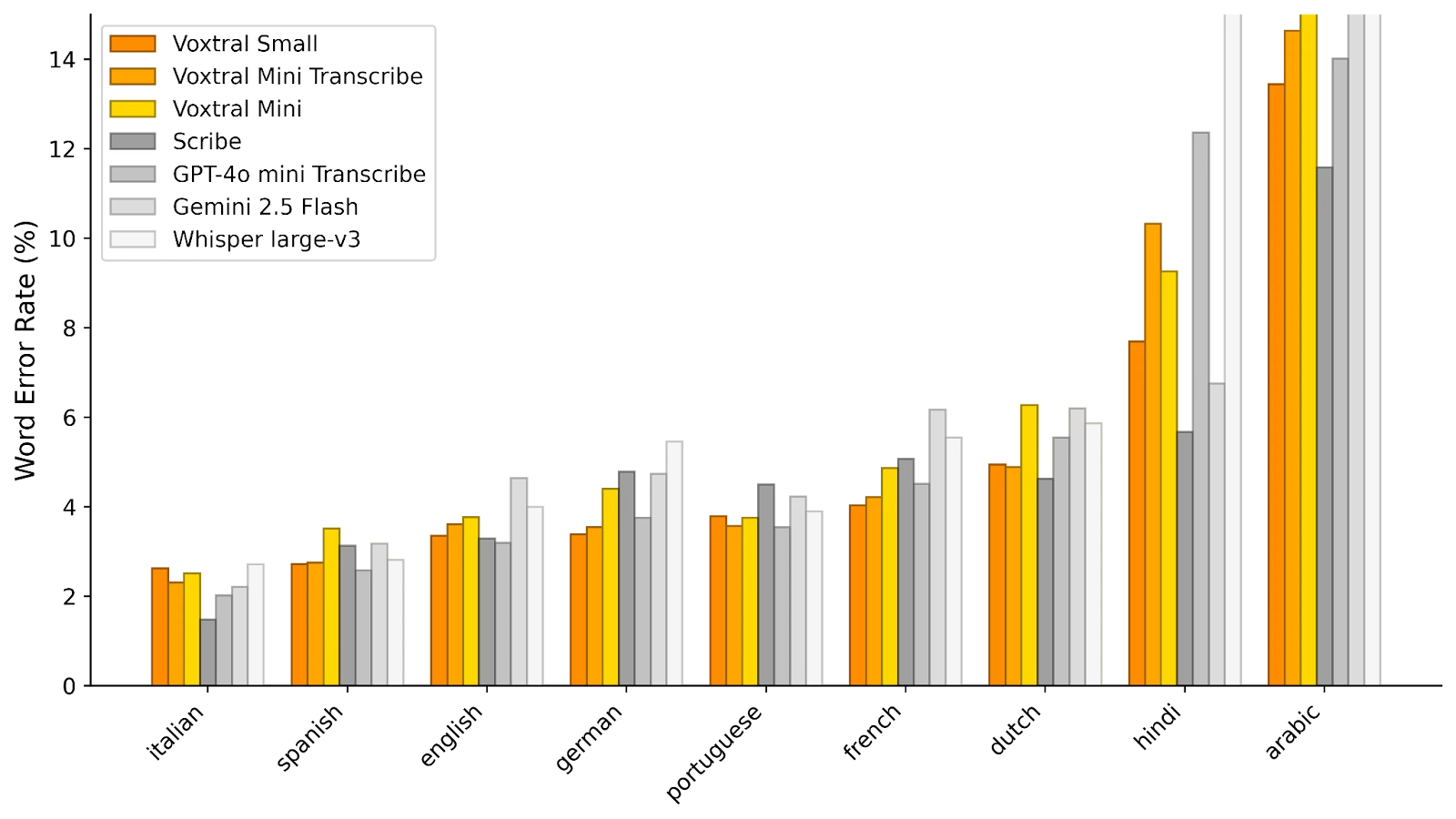
© Mistral AI
音声翻訳タスクにおいても、Voxtral SmallはGPT-4o MiniやGeminiと競合します。
利用可能性
Apache 2.0ライセンスの下で配布されている2つのモデルは、Hugging Faceでダウンロード可能です。Voxtralはまた、アプリケーションに統合したい場合、APIを介して1分あたり0.001ドルから利用可能で、競合他社のオファーの半額以下です。Mistral AIの会話型アシスタント、Le Chatに間もなく追加される予定です。
特定のビジネスコンテキストに合わせて、企業は法務や医療の分野でプライベートで安全な展開を選択することができます。
Mistral AIは、今後数ヶ月でオーディオセグメンテーション、ダイアリゼーション(異なる話者の識別)、感情検出などの新機能を追加する予定です。
拡大する市場のダイナミクス
このリリースは、顧客サポート、インタラクション分析、自動ドキュメント化、音声アシスタンスなどのユースケースが加速し、トランスクリプションと音声分析ソリューションの需要が高まっている中で行われました。Voxtralは、Whisper(OpenAI、MIT)、SeamlessM4T(Meta、非商用)、NVIDIA NeMoやESPnetのようなフレームワークがすでに占めている空間に参入します。
しかし、現時点で、多くの企業が提供するのは、自由なアクセス、統合されたセマンティック理解、音声からのアクション実行能力を一つのソリューションで提供することです。
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale