TLDR : Googleの研究者たちは、MLE-STARという機械学習エージェントを開発し、ウェブ検索、コード改良、適応的アセンブリを組み合わせてAIモデル作成プロセスを改善しました。MLE-STARはKaggleベンチマークで63%のコンペティションを制し、以前のアプローチを大きく上回る成果を示しています。
目次
大規模言語モデル(LLMs)に基づくMLE(Machine Learning Engineering)エージェントは、機械学習モデル開発において、新しい展望を開き、プロセスの全体または一部を自動化しています。しかし、既存のソリューションは、しばしば探索の限界や方法論の多様性の欠如に直面します。Googleの研究者たちは、MLE-STARというエージェントでこれらの課題に対応し、ターゲットを絞ったウェブ検索、コードブロックの詳細な改良、適応的なアセンブリ戦略を組み合わせています。
具体的には、MLEエージェントはタスクの説明(例えば「表形式データから売上を予測する」)と提供されたデータセットから始まり、次のように進みます:
- 問題を分析し、適切なアプローチを選択;
- コードを生成(しばしばPythonで、一般的または専門的なMLライブラリを使用);
- 解決策をテスト、評価、改良、時には複数のイテレーションを経ます。
これらのエージェントは、LLMの2つの主要な能力に依拠しています:
- アルゴリズムの推論(特定の問題に対して関連する方法を特定);
- 実行可能なコードの生成(データ準備、トレーニング、評価の完全なスクリプト)。
彼らの目標は、特徴エンジニアリング、ハイパーパラメーターの調整、モデル選択のような面倒なステップを自動化することで人間の作業負担を減らすことです。
MLE-STAR:ターゲットを絞った反復的な最適化
Google Researchによれば、既存のMLEは2つの主要な障壁に直面しています。まず、LLMsの内部知識への強い依存は、タブデータに対してscikit-learnライブラリのような一般的で確立された方法を優先し、より専門的で潜在的に優れたアプローチを犠牲にしています。次に、彼らの探索戦略はしばしば、各イテレーションでコードの完全な書き換えに基づいています。この動作は、特徴エンジニアリングの異なるオプションを体系的にテストするなど、パイプラインの特定のコンポーネントに集中することを妨げます。
これらの制限を克服するために、Googleの研究者たちは、次の3つのレバーを組み合わせたMLE-STARを設計しました:
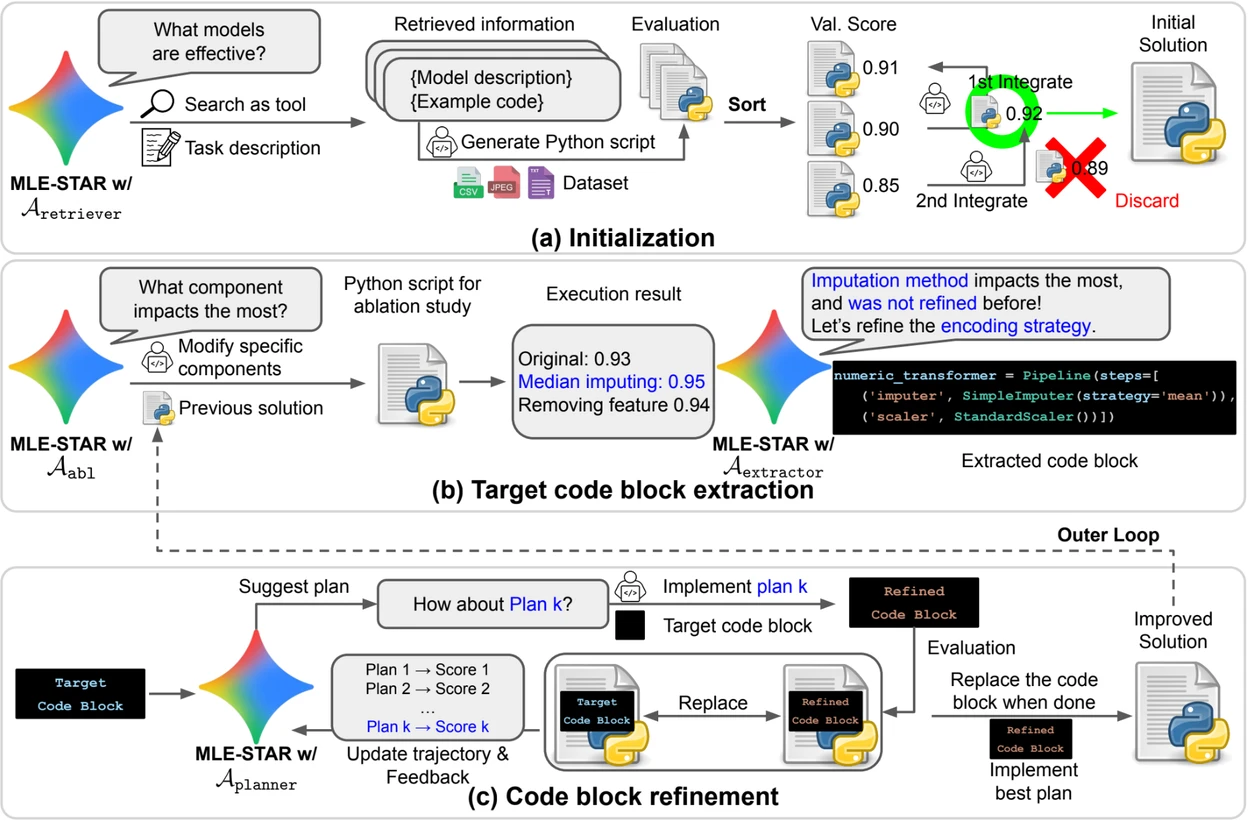
- タスクに特化したモデルを特定し、堅実な初期解決策を構築するためのウェブ検索;
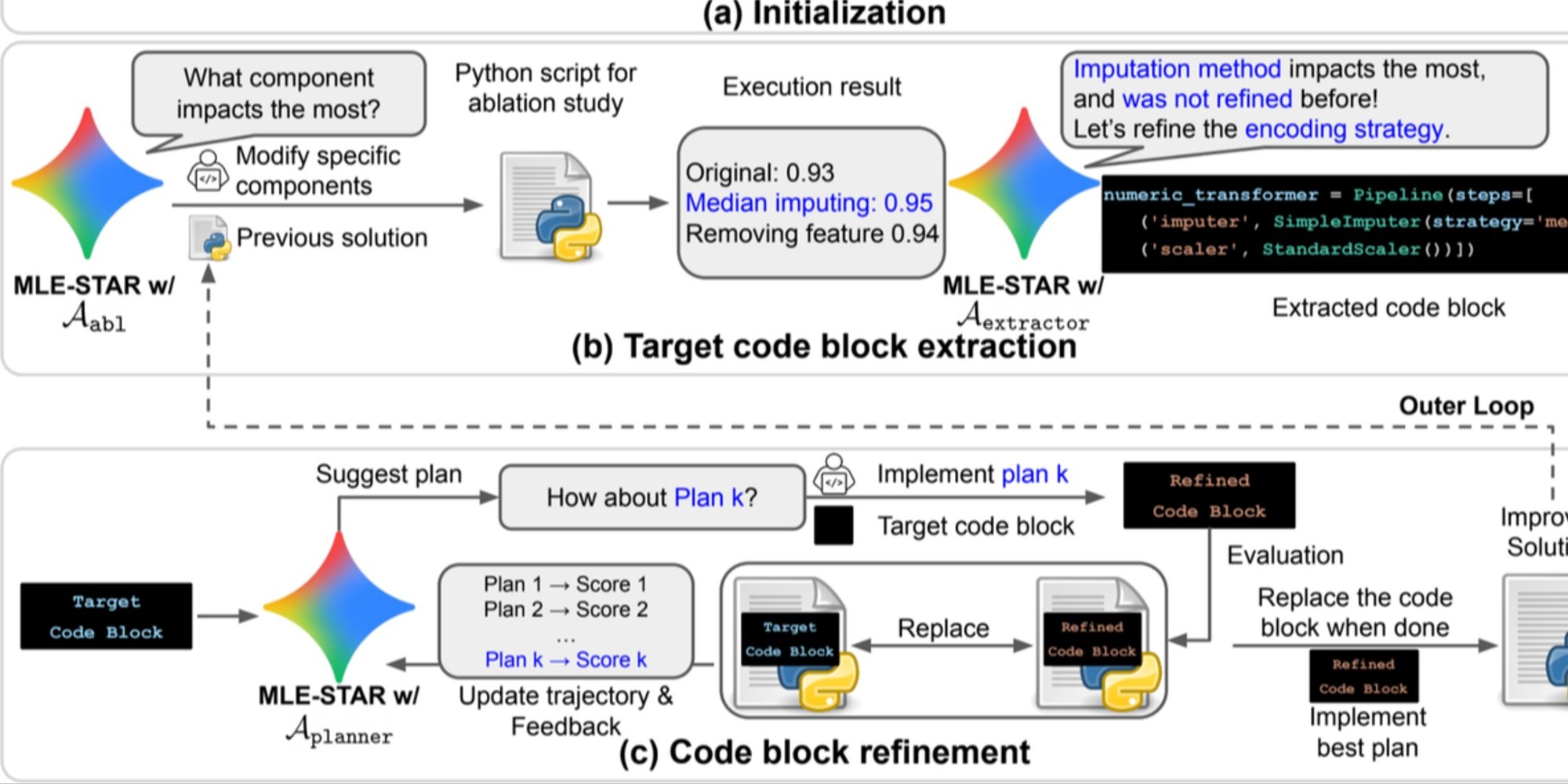
- 影響が大きい部分を特定し、反復的に最適化するためのアブレーションスタディに基づくコードブロックの詳細な改良;
- 複数の候補ソリューションを融合し、試みを通じて洗練された改良版を生み出す適応的なアセンブリ戦略。
この反復的なプロセス、すなわち検索、重要なブロックの特定、最適化、次のイテレーションへの移行により、MLE-STARは測定可能な利益をもたらす部分にその努力を集中させます。
クレジット:Google Research.
概要. a) MLE-STARは、ウェブ検索を使用してタスクに特化したモデルを見つけ、それを初期解決策に組み込むことから始まります。 (b) 各改良ステップのために、アブレーションスタディを実行し、パフォーマンスに最も影響を与えるコードブロックを決定します。 (c) 識別されたコードブロックは、前回の実験からのフィードバックを利用して様々な戦略を探索するLLMによって提案された計画に基づいて反復的に改良されます。このブロック選択と改良のプロセスは繰り返され、(c) の改良された解決策が次の改良ステップ(b) の出発点となります。
信頼性を高めるためのコントロールモジュール
反復的なアプローチを超えて、MLE-STARは生成されたソリューションの堅牢性を強化するために3つのモジュールを統合しています:
- デバッグエージェント が実行エラーを分析し(例えば、Pythonのtraceback)、自動修正を提案します;
- データリーク検出器 が、テストデータからの情報が誤ってトレーニング中に使用される状況を検出し、測定されたパフォーマンスを歪めるバイアスを防ぎます;
- データ使用検証器 が、CSVのような標準フォーマットでない場合でも、提供されたすべてのデータソースが利用されることを保証します。
これらのモジュールは、LLMsによって生成されたコードで観察される一般的な問題に対処します。
Kaggleでの顕著な結果
MLE-STARの有効性を評価するために、研究者たちはKaggleコンペティションに基づくMLE-Bench-Liteベンチマークでそれをテストしました。このプロトコルは、簡単なタスクの説明から完全で競争力のあるソリューションを生産するエージェントの能力を測定しました。
結果は、MLE-STARが63%のコンペティションでメダルを獲得し、そのうち36%が金メダルであることを示していますが、以前の最高のアプローチでは25.8%から36.6%でした。この利得は、EfficientNetやViTのような最近のモデルの迅速な採用、人間の介入を介したウェブ検索で識別されないモデルの統合、そしてデータリークとデータ使用検証器による自動修正の組み合わせに起因します。
arXivで科学論文を見つける : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
コードオープンソースはGitHubで利用可能です。