
TLDR : 中国のスタートアップDeepSeekがR1モデルをアップデートし、推論、論理、数学、プログラミングの性能を向上させました。このアップデートにより、R1はOpen AIのo3やGoogleのGemini 2.5 Proといった主要モデルと競争できるようになります。
目次
DeepSeek R2の次期リリースに関する憶測が広がる中、中国のスタートアップであるDeepSeekは、5月28日にR1モデルのアップデートを発表しました。このバージョンはDeepSeek-R1-0528と命名され、推論、論理、数学、プログラミングといった重要な分野でのR1の能力を強化しています。MITライセンスの下で公開されているこのオープンソースモデルの性能は、Open AIのo3やGoogleのGemini 2.5 Proといった主要モデルに近づいています。
複雑な推論タスクの管理における著しい改善
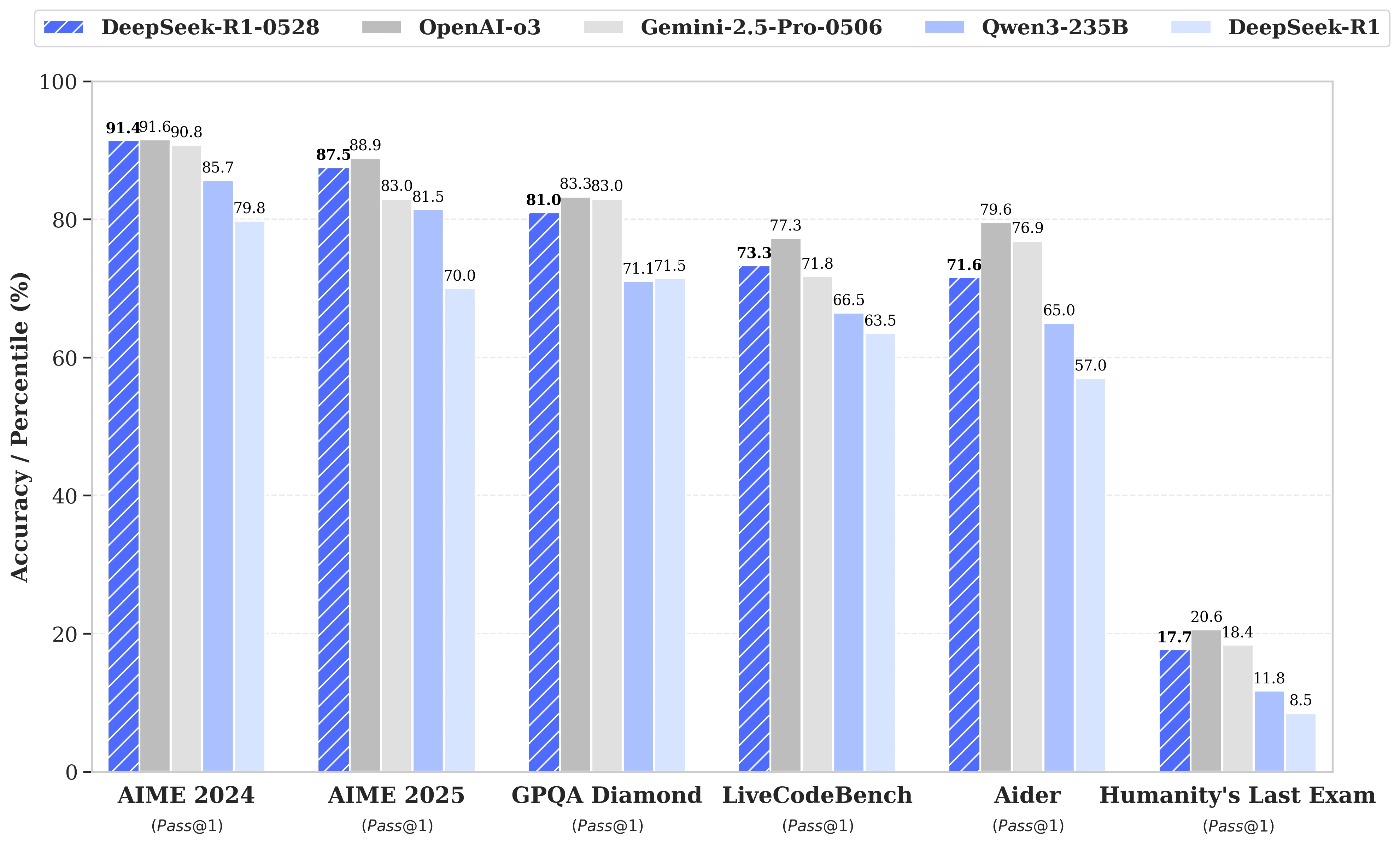
このアップデートは、利用可能な計算リソースのより効率的な活用と、ポストトレーニングで実行された一連のアルゴリズム最適化に基づいています。これらの調整により、推論時の思考の深さが増し、以前のバージョンがAIMEテストで質問1つあたり平均12,000トークンを消費していたのに対し、DeepSeek-R1-0528は約23,000トークンを使用し、2025年版テストでの精度が70%から87.5%に向上しました。
- 数学では、記録されたスコアは91.4%(AIME 2024)および79.4%(HMMT 2025)に達し、o3やGemini 2.5 Proなどの一部のクローズドモデルの性能に匹敵または超えています;
- プログラミングでは、LiveCodeBenchの指数が63.5%から73.3%に約10ポイント上昇し、SWE Verifiedの評価は49.2%から57.6%に向上しました;
- 一般的な推論では、GPQA-Diamantテストのスコアが71.5%から81.0%に上昇し、「人類の最後の試験」ベンチマークでは8.5%から17.7%に二倍以上になりました。
エラーの削減とアプリケーション統合の改善
このアップデートで導入された注目すべき進歩の中には、幻覚率の顕著な低下があります。これは、LLMの信頼性にとって重要な課題です。事実に基づかない回答の頻度を減らすことで、DeepSeek-R1-0528は特に精度が必須のコンテキストでの堅牢性が向上しています。
アップデートはまた、構造化された環境での使用を目的とした機能を導入し、JSON形式での直接出力生成や関数呼び出しのサポート拡大が含まれています。これらの技術的進歩により、重い中間処理を必要とせずに、モデルを自動化されたワークフロー、ソフトウェアエージェント、バックエンドシステムに統合することが容易になります。
蒸留への注目の高まり
同時に、DeepSeekのチームは、限られた機材を持つ開発者や研究者向けに、思考の連鎖をより軽量なモデルに蒸留するアプローチを開始しました。DeepSeek-R1-0528は685B(十億)パラメータを持ち、Qwen3 8B Baseのポストトレーニングに使用されました。
その結果得られたモデル、DeepSeek-R1-0528-Qwen3-8Bは、いくつかのベンチマークで遥かに大きなオープンソースモデルに匹敵することに成功しました。AIME 2024でのスコアは86.0%で、Qwen3 8Bのスコアを10.0%以上上回り、Qwen3-235B-thinkingの性能に匹敵します。
このアプローチは、大規模モデルの将来的な存続可能性に疑問を投げかけ、より効率的で訓練された推論を持つバージョンに対抗するものです。
DeepSeekは次のように述べています:
「DeepSeek-R1-0528の思考の連鎖は、推論モデルに関する学術研究と、小規模モデルに焦点を当てた産業開発の両方において重要な意義を持つと考えています。」