TLDR : I ricercatori di Google hanno sviluppato MLE-STAR, un agente di apprendimento automatico che migliora il processo di creazione di modelli IA combinando ricerca web mirata, raffinamento del codice e assemblaggio adattativo. MLE-STAR ha dimostrato la sua efficacia vincendo il 63% delle competizioni nel benchmark MLE-Bench-Lite basato su Kaggle, superando di gran lunga gli approcci precedenti.
Sommario
Gli agenti MLE (Machine Learning Engineering agent), basati su grandi modelli di linguaggio (LLM), hanno aperto nuove prospettive nello sviluppo dei modelli di apprendimento automatico automatizzando tutto o parte del processo. Tuttavia, le soluzioni esistenti spesso si scontrano con limiti di esplorazione o con una mancanza di diversità metodologica. I ricercatori di Google rispondono a queste sfide con MLE-STAR, un agente che combina ricerca web mirata, raffinamento granulare dei blocchi di codice e strategia di assemblaggio adattativa.
Concretamente, un agente MLE parte da una descrizione del compito (ad esempio, "predire le vendite da dati tabulari") e dai set di dati forniti, quindi:
- Analizza il problema e sceglie un approccio adeguato;
- Genera codice (spesso in Python, con librerie ML comuni o specializzate);
- Testa, valuta e affina la soluzione, a volte in diverse iterazioni.
Questi agenti si basano su due competenze chiave dei LLM:
- Il ragionamento algoritmico (identificare i metodi pertinenti per un dato problema);
- La generazione di codice eseguibile (script completi per la preparazione dei dati, l'addestramento e la valutazione).
Il loro obiettivo è ridurre il carico di lavoro umano automatizzando passaggi noiosi come l'ingegneria delle caratteristiche, la regolazione degli iperparametri o la selezione dei modelli.
MLE-STAR: un'ottimizzazione mirata e iterativa
Secondo Google Research, gli MLE esistenti si scontrano con due ostacoli principali. Innanzitutto, la loro forte dipendenza dalle conoscenze interne dei LLM li spinge a privilegiare metodi generici e ben stabiliti, come la libreria scikit-learn per i dati tabulari, a scapito di approcci più specializzati e potenzialmente più performanti.
Inoltre, la loro strategia di esplorazione si basa spesso su una riscrittura completa del codice a ogni iterazione. Questo funzionamento impedisce loro di concentrare i loro sforzi su componenti specifici della pipeline, ad esempio, testare in modo sistematico diverse opzioni di ingegneria delle caratteristiche, prima di passare ad altri passaggi.
Inoltre, la loro strategia di esplorazione si basa spesso su una riscrittura completa del codice a ogni iterazione. Questo funzionamento impedisce loro di concentrare i loro sforzi su componenti specifici della pipeline, ad esempio, testare in modo sistematico diverse opzioni di ingegneria delle caratteristiche, prima di passare ad altri passaggi.
Per superare questi limiti, i ricercatori di Google hanno concepito MLE-STAR, un agente che combina tre leve:
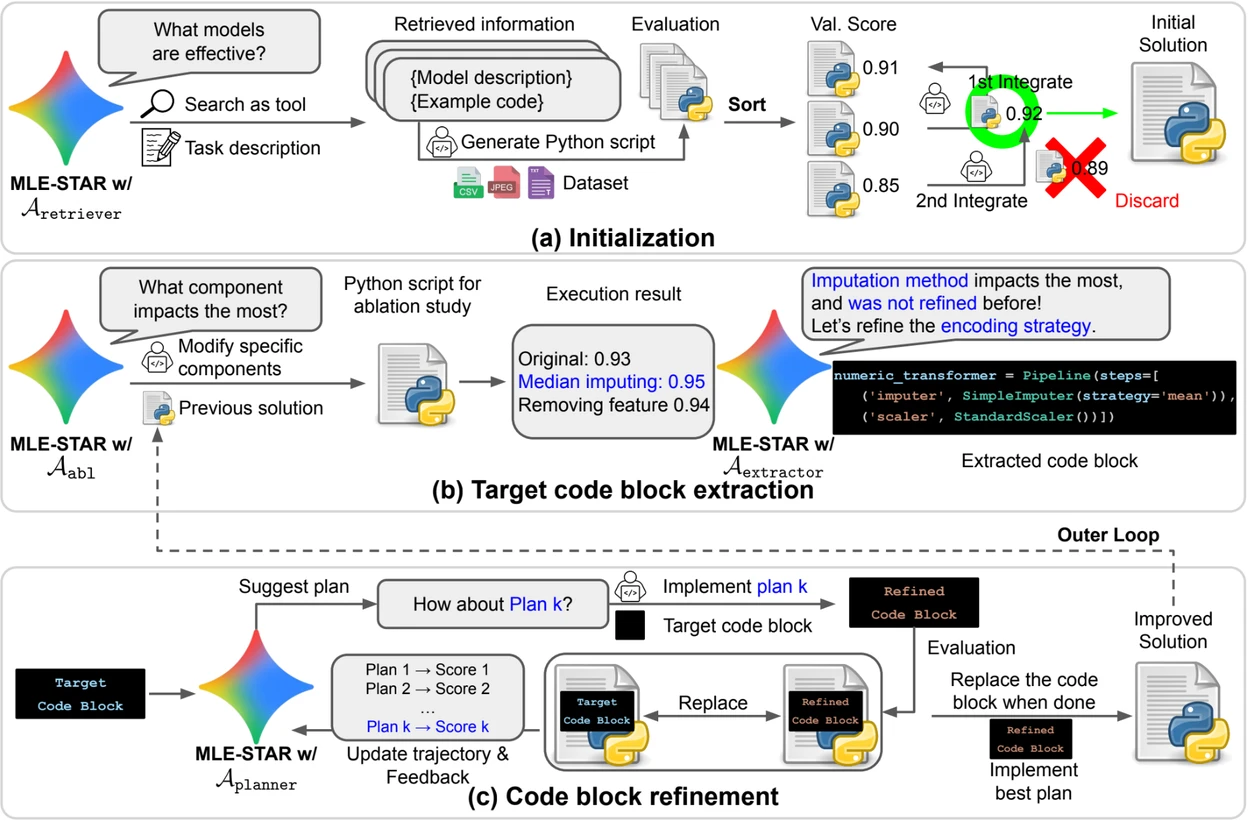
- Ricerca web per identificare modelli specifici per il compito e costituire una soluzione iniziale solida;
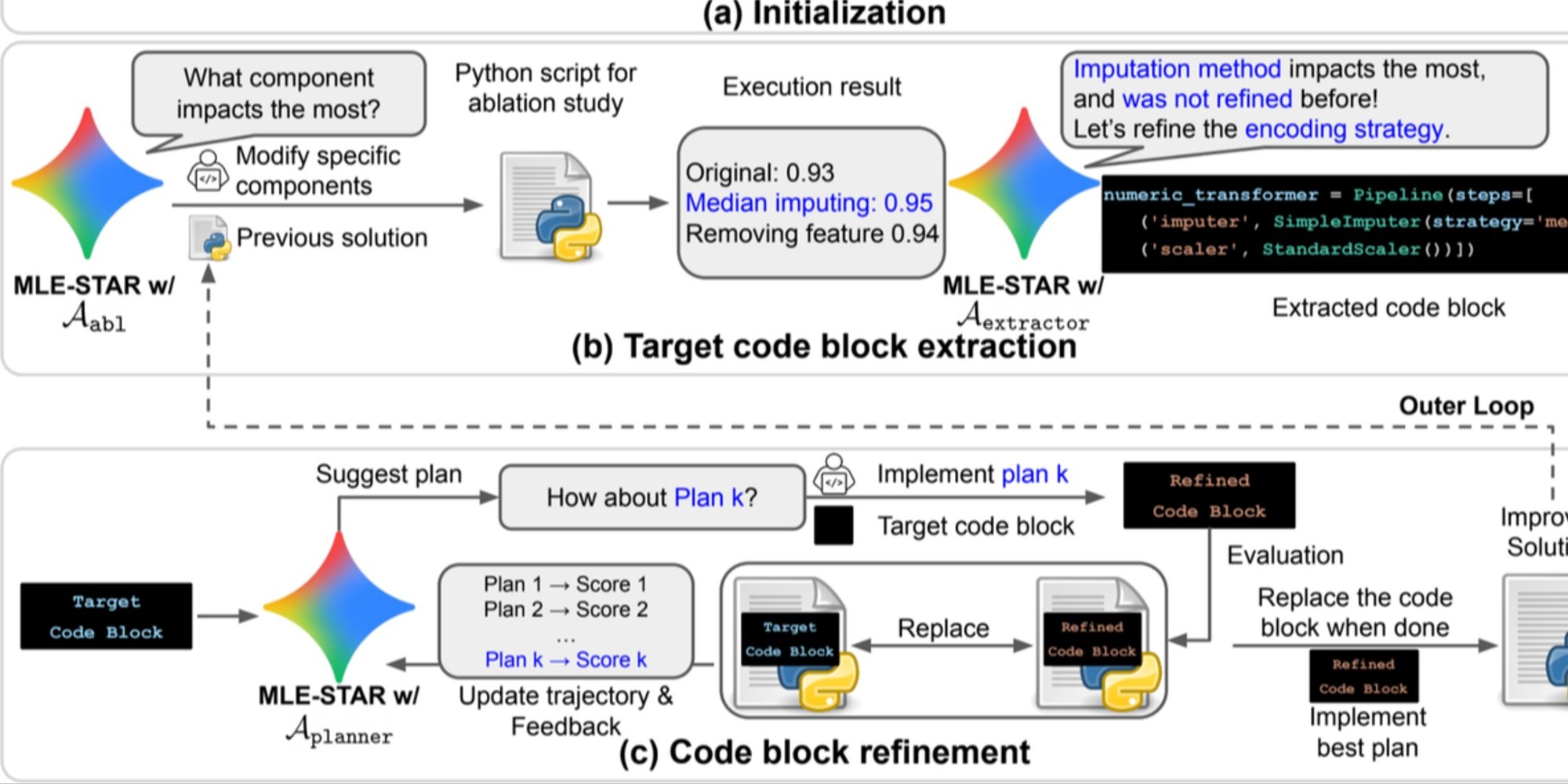
- Raffinamento granulare per blocchi di codice, basandosi su studi di ablazione per individuare le parti con il maggiore impatto sulle prestazioni, quindi ottimizzandole iterativamente;
- Strategia di assemblaggio adattativa, capace di fondere più soluzioni candidate in una versione migliorata, affinata nel corso dei tentativi.
Questo processo iterativo, ricerca, identificazione del blocco critico, ottimizzazione, quindi nuova iterazione, permette a MLE-STAR di concentrare i suoi sforzi là dove producono i maggiori guadagni misurabili.
Credito: Google Research.
Panoramica. a) MLE-STAR inizia utilizzando la ricerca sul Web per trovare e incorporare modelli specifici per un compito in una soluzione iniziale. (b) Per ogni fase di raffinamento, esegue uno studio di ablazione per determinare il blocco di codice con l'impatto più significativo sulle prestazioni. (c) Il blocco di codice identificato subisce quindi un raffinamento iterativo basato sui piani suggeriti dai LLM, che esplorano varie strategie utilizzando i feedback delle esperienze precedenti. Questo processo di selezione e raffinamento dei blocchi di codice mirati si ripete, dove la soluzione migliorata di (c) diventa il punto di partenza per la fase di raffinamento successiva (b).
Moduli di controllo per garantire soluzioni affidabili
Oltre al suo approccio iterativo, MLE-STAR integra tre moduli destinati a rafforzare la robustezza delle soluzioni generate:
- Un agente di debugging per analizzare gli errori di esecuzione (ad esempio, un traceback Python) e proporre correzioni automatiche;
- Un verificatore di fuga di dati per rilevare le situazioni in cui informazioni dai dati di test sono utilizzate erroneamente durante l'addestramento, un bias che falsifica le prestazioni misurate;
- Un verificatore di utilizzo dei dati per garantire che tutte le fonti di dati fornite siano utilizzate, anche quando non si presentano in formati standard come il CSV.
Questi moduli rispondono a problemi comuni osservati nel codice generato dai LLM.
Risultati significativi su Kaggle
Per valutare l'efficacia di MLE-STAR, i ricercatori l'hanno testato nel contesto del benchmark MLE-Bench-Lite, basato su competizioni Kaggle. Il protocollo misurava la capacità di un agente di produrre, a partire da una semplice descrizione del compito, una soluzione completa e competitiva.
I risultati mostrano che MLE-STAR ottiene una medaglia nel 63% delle competizioni, di cui il 36% d'oro, contro il 25,8% al 36,6% per i migliori approcci precedenti. Questo guadagno è attribuito alla combinazione di diversi fattori: l'adozione rapida di modelli recenti come EfficientNet o ViT, la capacità di integrare modelli non identificati dalla ricerca web grazie a un intervento umano puntuale, e le correzioni automatiche apportate dai verificatori di fughe e di utilizzo dei dati.
Trova il documento scientifico su arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
Il codice open source è disponibile su GitHub