
TLDR : La start-up cinese DeepSeek ha aggiornato il suo modello R1, migliorando le sue prestazioni nel ragionamento, nella logica, nella matematica e nella programmazione. Questo aggiornamento, che riduce gli errori e migliora l'integrazione applicativa, consente a R1 di competere con modelli di punta come o3 di Open AI e Gemini 2.5 Pro di Google.
Sommario
Mentre le speculazioni si susseguivano sul prossimo lancio di DeepSeek R2, è stato infine un aggiornamento del modello R1 che la start-up cinese omonima ha annunciato lo scorso 28 maggio. Denominata DeepSeek-R1-0528, questa versione potenzia le capacità di R1 in aree chiave come il ragionamento, la logica, la matematica e la programmazione. Ora, le prestazioni di questo modello open source pubblicato sotto licenza MIT si avvicinano a quelle dei modelli di punta o3 di Open AI e Gemini 2.5 Pro di Google.
Miglioramenti significativi nella gestione dei compiti di ragionamento complessi
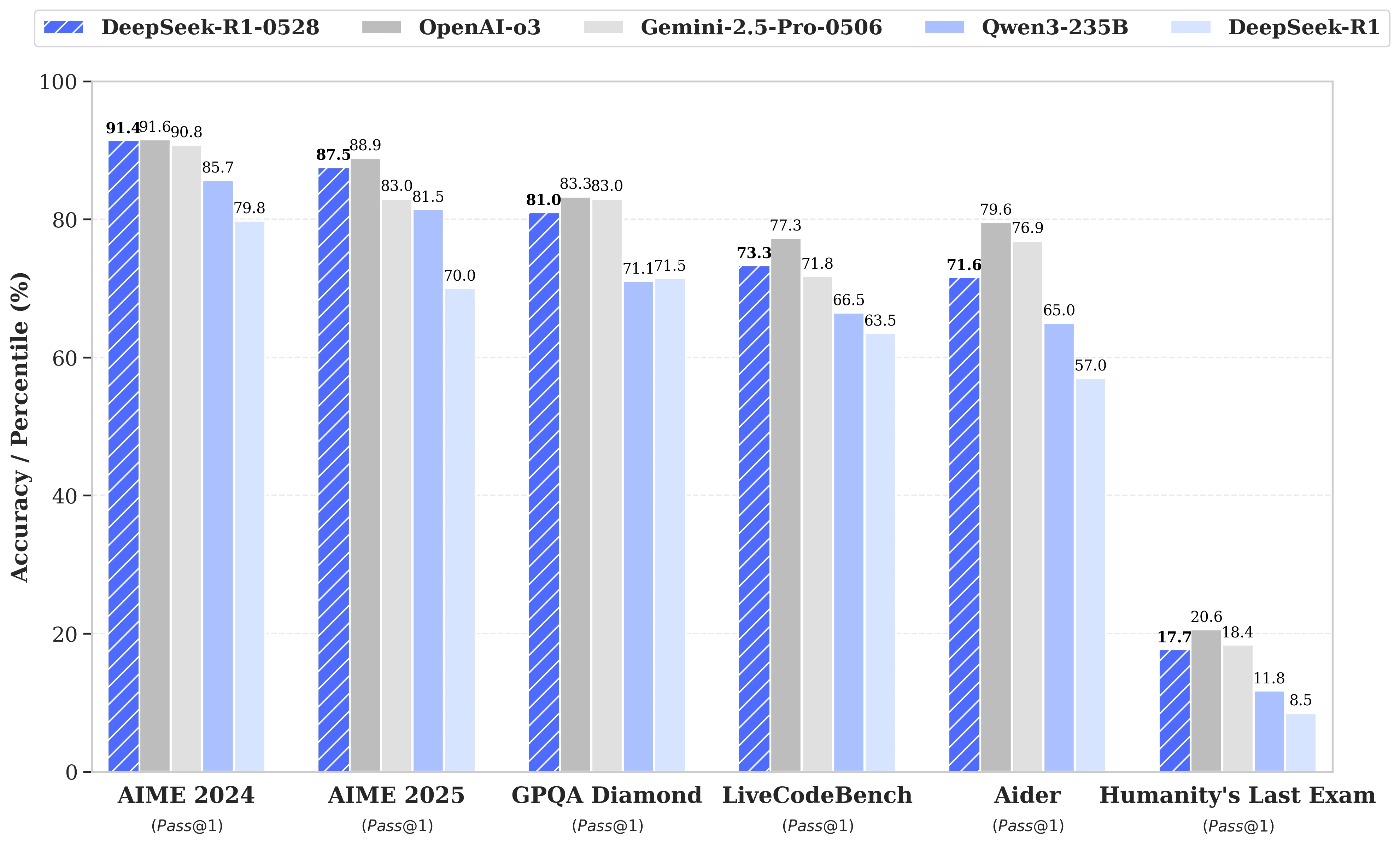
L'aggiornamento si basa su un utilizzo più efficiente delle risorse di calcolo disponibili, combinato con una serie di ottimizzazioni algoritmiche implementate in post-formazione. Questi aggiustamenti si traducono in una maggiore profondità di riflessione durante il ragionamento: mentre la versione precedente consumava in media 12.000 token per domanda nei test AIME, DeepSeek-R1-0528 ne utilizza ora circa 23.000, con un notevole miglioramento della precisione, dal 70% all'87,5% sull'edizione 2025 del test.
- In programmazione, l'indice LiveCodeBench avanza di quasi 10 punti (dal 63,5 al 73,3%), e la valutazione SWE Verified sale dal 49,2% al 57,6% di successo;
- In ragionamento generale, il test GPQA-Diamant vede il punteggio del modello passare dal 71,5% all'81,0%, mentre per il benchmark "Ultimo esame dell'umanità", è più che raddoppiato, passando dall'8,5% al 17,7%.
Riduzione degli errori e migliore integrazione applicativa
Tra le evoluzioni notevoli apportate da questo aggiornamento, si osserva una riduzione sensibile del tasso di allucinazione, una questione critica per l'affidabilità dei LLMs. Riducendo la frequenza delle risposte fattualmente inesatte, DeepSeek-R1-0528 guadagna in robustezza, soprattutto nei contesti in cui la precisione è indispensabile.
L'aggiornamento introduce anche funzionalità orientate all'uso in ambienti strutturati, tra cui la generazione diretta di output in formato JSON e il supporto ampliato per la chiamata di funzioni. Questi progressi tecnici semplificano l'integrazione del modello in flussi di lavoro automatizzati, agenti software o sistemi back-end, senza necessitare di pesanti elaborazioni intermedie.
Una crescente attenzione alla distillazione
Parallelamente, il team di DeepSeek ha avviato un processo di distillazione delle catene di pensiero verso modelli più leggeri, per sviluppatori o ricercatori con hardware limitato. DeepSeek-R1-0528 che conta 685 B (miliardi) parametri, è stato così utilizzato per post-addestrare Qwen3 8B Base.
Il modello risultante, DeepSeek-R1-0528-Qwen3-8B, riesce a eguagliare modelli open source molto più voluminosi su alcuni benchmark. Con un punteggio dell'86,0% su AIME 2024, supera non solo quello di Qwen3 8B di oltre il 10,0% ma eguaglia le prestazioni di Qwen3-235B-thinking.
Un approccio che interroga sulla futura fattibilità dei modelli massicci, di fronte a versioni più frugali ma meglio addestrate a ragionare.
DeepSeek afferma:
"Crediamo che la catena di pensiero di DeepSeek-R1-0528 avrà un'importanza significativa sia per la ricerca accademica sui modelli di ragionamento sia per lo sviluppo industriale focalizzato sui modelli a piccola scala".