Alibaba ha annunciato il 21 luglio scorso su X la pubblicazione dell'ultimo aggiornamento del suo LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. Il modello open source, distribuito sotto licenza Apache 2.0, conta 235 miliardi di parametri e si presenta come un serio concorrente per DeepSeek-V3, Claude Opus 4 di Anthropic, GPT-4o di OpenAI o Kimi 2 lanciato recentemente dalla start-up cinese Moonshot, quattro volte più grande.
Alibaba Cloud precisa nel suo post:
"Dopo aver discusso con la comunità e riflettuto sulla questione, abbiamo deciso di abbandonare la modalità di pensiero ibrido. Addestreremo d'ora in poi i modelli Instruct e Thinking separatamente per ottenere la migliore qualità possibile".
Qwen3-235B-A22B-Instruct-2507 è un modello non-riflessivo (non-thinking), cioè non opera un ragionamento complesso in catena ma privilegia la rapidità e la pertinenza nell'esecuzione delle istruzioni.
Grazie a questa orientazione strategica, Qwen 3 non si limita a progredire nel seguire istruzioni ma mostra anche avanzamenti in ragionamento logico, comprensione fine di ambiti specializzati, trattamento di lingue poco comuni, nonché in matematica, scienze, programmazione e interazione con strumenti digitali.
Nelle attività aperte, che implicano giudizio, tono o creazione, si adatta meglio alle aspettative degli utenti, con risposte più utili e uno stile di generazione più naturale.
La sua finestra contestuale, portata a 256.000 token, è stata moltiplicata per otto, permettendogli di gestire documenti voluminosi.
Un'architettura orientata a flessibilità ed efficienza
Il modello si basa su un'architettura Mixture-of-Experts (MoE) che conta 128 esperti specializzati, di cui 8 sono selezionati in base alla domanda: dei suoi 235 miliardi di parametri, solo 22 miliardi sono così attivati per richiesta.
Si appoggia su 94 livelli di profondità, uno schema GQA (Grouped Query Attention) ottimizzato: 64 teste per la query (Q) e 4 per le chiavi/valori.
Prestazioni di Qwen3-235B-A22B-Instruct-2507
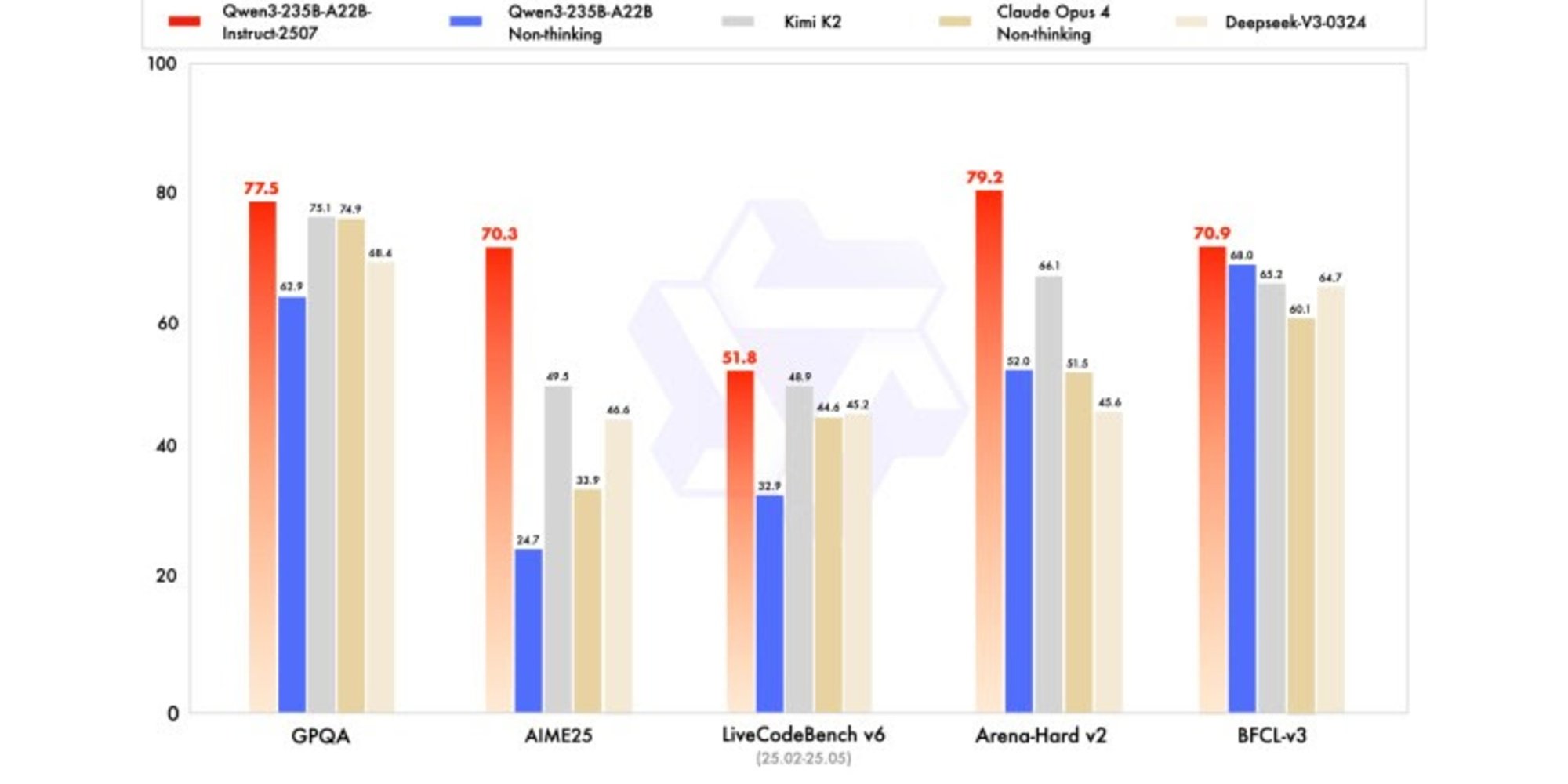
La nuova versione mostra risultati competitivi, se non superiori, ai modelli dei leader concorrenti, in particolare in matematica, codifica e ragionamento logico.
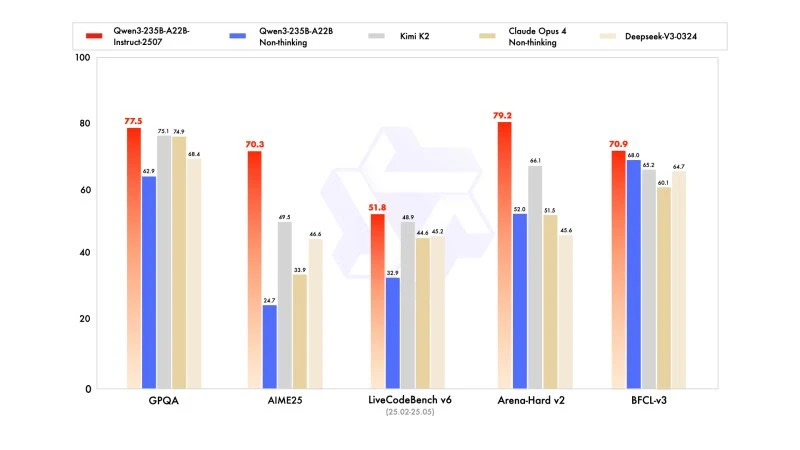
In conoscenze generali, ha ottenuto un punteggio di 83,0 su MMLU-Pro (contro 75,2 della versione precedente) e 93,1 su MMLU-Redux, avvicinandosi al livello di Claude Opus 4 (94,2).
In ragionamento avanzato, ha raggiunto un punteggio molto elevato nella modellazione matematica: 70,3 su AIME (American Invitational Mathematics Examination) 2025, superando i punteggi di 46,6 di DeepSeek-V3-0324 e di 26,7 di GPT-4o-0327 di OpenAI.
In codifica, il suo punteggio di 87,9 su MultiPL-E, lo posiziona dietro Claude (88,5), ma davanti a GPT-4o e DeepSeek. Su LiveCodeBench v6, raggiunge 51,8, ovvero la migliore performance misurata su questo benchmark.
Versione quantificata in FP8: ottimizzazione senza compromessi
Parallelamente a Qwen3-235B-A22B-Instruct-2507, Alibaba ha pubblicato la sua versione quantificata in FP8. Questo formato numerico compresso riduce drasticamente le esigenze di memoria e accelera l'inferenza, permettendo al modello di funzionare in ambienti dove le risorse sono limitate, senza comportare perdite significative di prestazioni.