TLDR : Die Forscher von Google haben MLE-STAR entwickelt, einen Machine-Learning-Agenten, der den Prozess der Erstellung von KI-Modellen durch gezielte Websuche, Codeverfeinerung und adaptives Zusammenbauen verbessert. MLE-STAR hat seine Effektivität bewiesen, indem es 63 % der Wettbewerbe im auf Kaggle basierenden Benchmark MLE-Bench-Lite gewonnen hat und damit frühere Ansätze deutlich übertrifft.
Inhaltsverzeichnis
MLE-Agenten (Machine Learning Engineering Agent), basierend auf großen Sprachmodellen (LLMs), haben neue Perspektiven in der Entwicklung von Machine-Learning-Modellen eröffnet, indem sie den Prozess teilweise oder vollständig automatisieren. Bestehende Lösungen stoßen jedoch oft auf Grenzen der Exploration oder auf einen Mangel an methodischer Vielfalt. Die Forscher von Google begegnen diesen Herausforderungen mit MLE-STAR, einem Agenten, der gezielte Websuche, granulare Verfeinerung von Codeblöcken und eine adaptive Zusammenbaustrategie kombiniert.
Konkret beginnt ein MLE-Agent mit einer Aufgabenbeschreibung (zum Beispiel, "Vorhersage von Verkäufen anhand tabellarischer Daten") und bereitgestellten Datensätzen, dann:
- Analysiert das Problem und wählt einen geeigneten Ansatz aus;
- Generiert Code (oft in Python, mit gängigen oder spezialisierten ML-Bibliotheken);
- Testet, bewertet und verfeinert die Lösung, manchmal in mehreren Iterationen.
Diese Agenten stützen sich auf zwei Schlüsselkompetenzen der LLMs:
- Algorithmisches Denken (Identifikation der relevanten Methoden für ein gegebenes Problem);
- Erzeugung ausführbaren Codes (komplette Skripte zur Datenaufbereitung, zum Training und zur Bewertung).
Ihr Ziel ist es, die menschliche Arbeitslast zu reduzieren, indem sie mühsame Schritte wie Feature Engineering, Hyperparameter-Tuning oder Modellauswahl automatisieren.
MLE-STAR: Eine gezielte und iterative Optimierung
Laut Google Research stehen bestehende MLEs vor zwei Hauptproblemen. Erstens neigen sie aufgrund ihrer starken Abhängigkeit vom internen Wissen der LLMs dazu, generische und etablierte Methoden zu bevorzugen, wie die Bibliothek scikit-learn für tabellarische Daten, was auf Kosten spezialisierter und potenziell leistungsfähigerer Ansätze geht.
Zweitens basiert ihre Explorationsstrategie oft auf einer vollständigen Neuschreibung des Codes in jeder Iteration. Dieses Vorgehen hindert sie daran, ihre Bemühungen auf spezifische Komponenten der Pipeline zu konzentrieren, zum Beispiel systematisch verschiedene Optionen für das Feature Engineering zu testen, bevor sie zu anderen Schritten übergehen.
Zweitens basiert ihre Explorationsstrategie oft auf einer vollständigen Neuschreibung des Codes in jeder Iteration. Dieses Vorgehen hindert sie daran, ihre Bemühungen auf spezifische Komponenten der Pipeline zu konzentrieren, zum Beispiel systematisch verschiedene Optionen für das Feature Engineering zu testen, bevor sie zu anderen Schritten übergehen.
Um diese Grenzen zu überwinden, haben die Forscher von Google MLE-STAR entwickelt, einen Agenten, der drei Hebel kombiniert:
- Websuche, um aufgabenspezifische Modelle zu identifizieren und eine solide anfängliche Lösung zu erstellen;
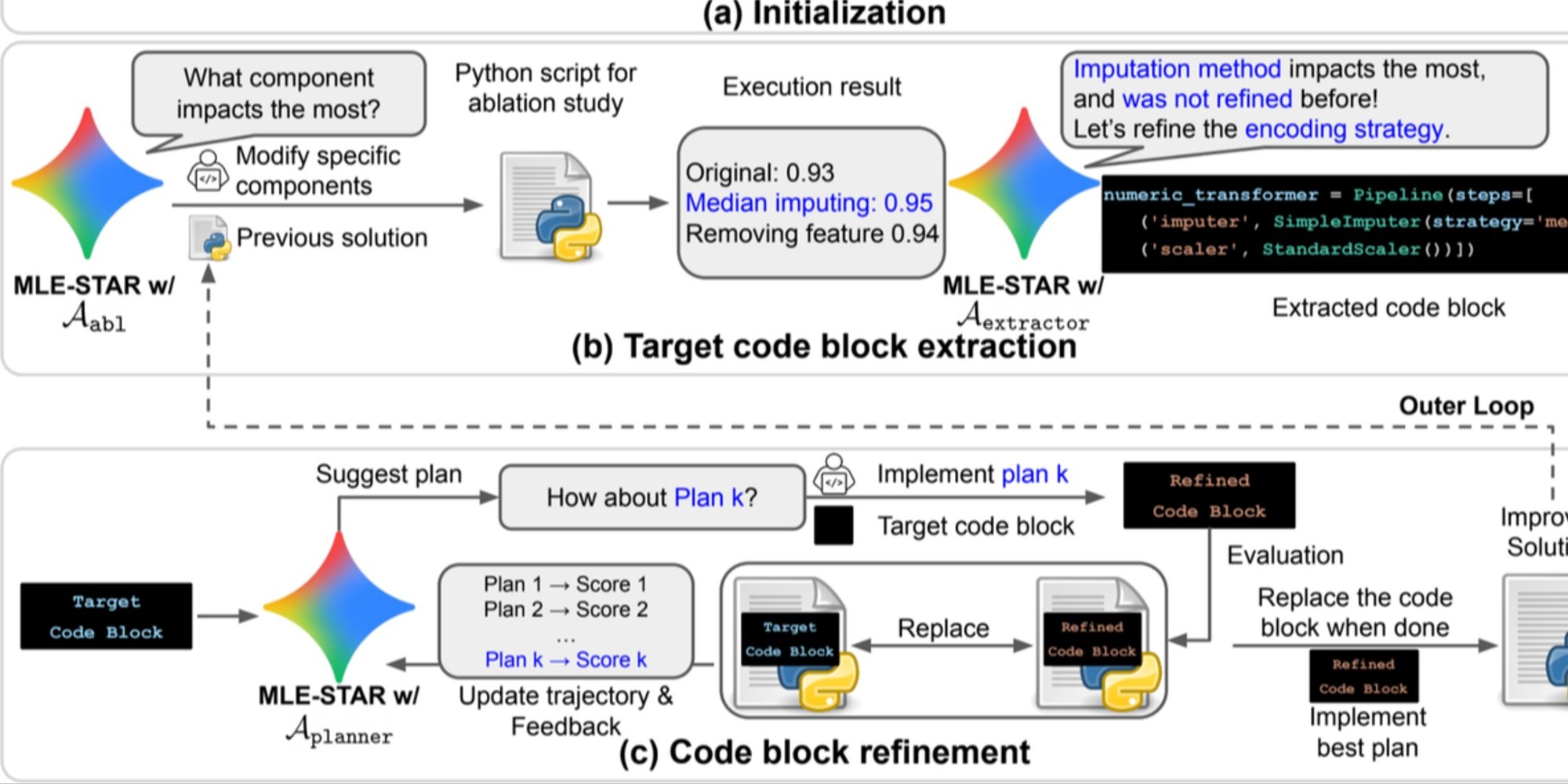
- Granulare Verfeinerung durch Codeblöcke, basierend auf Ablationsstudien, um die Teile mit dem größten Einfluss auf die Leistung zu identifizieren und diese iterativ zu optimieren;
- Adaptive Zusammenbaustrategie, die in der Lage ist, mehrere Kandidatenlösungen zu einer verbesserten Version zu verschmelzen, die im Laufe der Versuche verfeinert wird.
Dieser iterative Prozess - Suche, Identifizierung des kritischen Blocks, Optimierung und dann neue Iteration - ermöglicht es MLE-STAR, seine Bemühungen dort zu konzentrieren, wo sie den größten messbaren Gewinn erzielen.
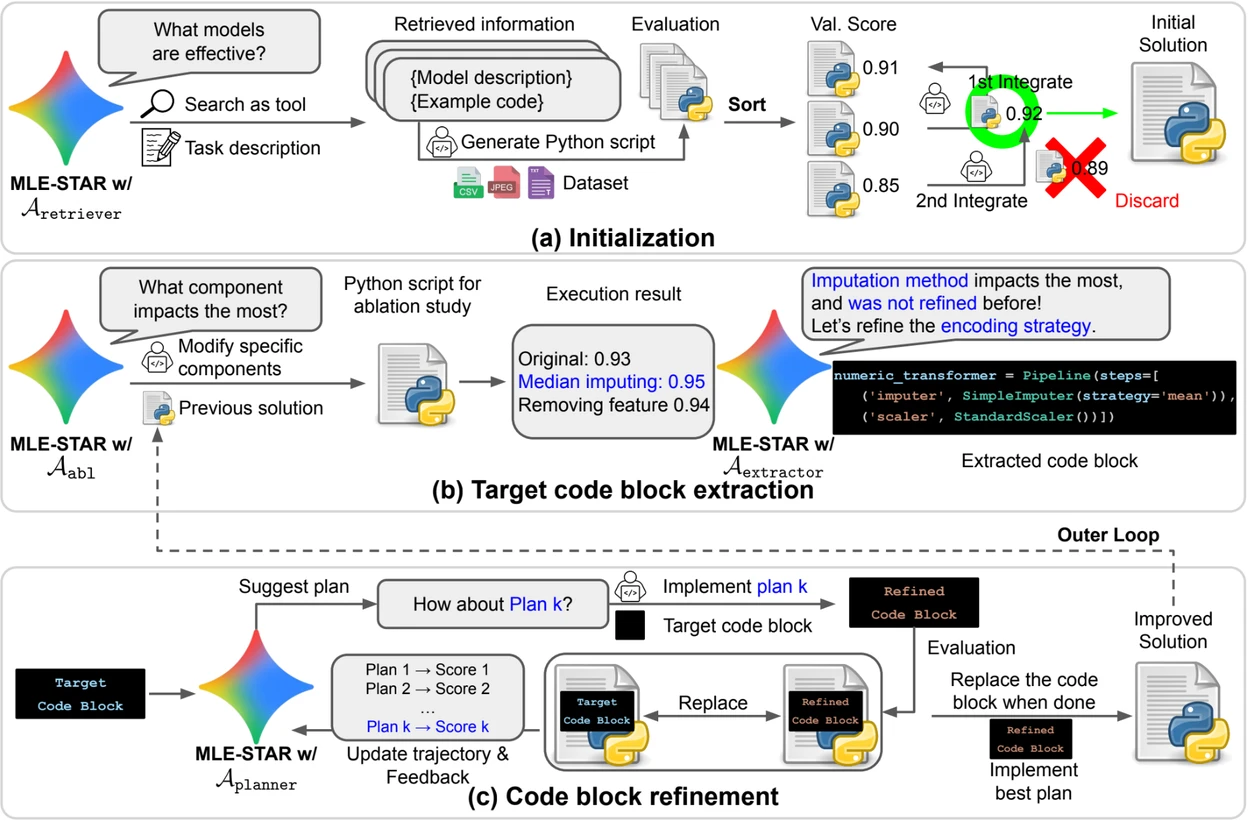
Kredit: Google Research.
Übersicht. a) MLE-STAR beginnt mit der Websuche, um aufgabenspezifische Modelle zu finden und in eine anfängliche Lösung zu integrieren. (b) Für jede Verfeinerungsstufe führt es eine Ablationsstudie durch, um den Codeblock mit dem größten Einfluss auf die Leistung zu bestimmen. (c) Der identifizierte Codeblock wird dann iterativ verfeinert, basierend auf den von LLM vorgeschlagenen Plänen, die verschiedene Strategien mit Feedback aus früheren Experimenten erkunden. Dieser Prozess der Auswahl und Verfeinerung der Ziel-Codeblöcke wiederholt sich, wobei die verbesserte Lösung aus (c) als Ausgangspunkt für die nächste Verfeinerungsstufe (b) dient.
Kontrollmodule zur Sicherstellung der Zuverlässigkeit der Lösungen
Über seinen iterativen Ansatz hinaus integriert MLE-STAR drei Module, die darauf abzielen, die Robustheit der generierten Lösungen zu stärken:
- Ein Debugging-Agent, um Ausführungsfehler (z.B. eine traceback in Python) zu analysieren und automatische Korrekturen vorzuschlagen;
- Ein Datenleckprüfer, um Situationen zu erkennen, in denen Informationen aus den Testdaten fälschlicherweise beim Training verwendet werden, ein Bias, der die gemessene Leistung verfälscht;
- Ein Datenverwendungsprüfer, um sicherzustellen, dass alle bereitgestellten Datenquellen genutzt werden, auch wenn sie nicht im Standardformat wie CSV vorliegen.
Diese Module adressieren häufige Probleme, die im von LLMs generierten Code beobachtet werden.
Bedeutende Ergebnisse auf Kaggle
Um die Effektivität von MLE-STAR zu bewerten, testeten die Forscher es im Rahmen des Benchmarks MLE-Bench-Lite, basierend auf Kaggle-Wettbewerben. Das Protokoll maß die Fähigkeit eines Agenten, aus einer einfachen Aufgabenbeschreibung eine vollständige und wettbewerbsfähige Lösung zu erstellen.
Die Ergebnisse zeigen, dass MLE-STAR in 63 % der Wettbewerbe eine Medaille gewinnt, davon 36 % in Gold, verglichen mit 25,8 % bis 36,6 % für die besten bisherigen Ansätze. Dieser Gewinn wird der Kombination mehrerer Faktoren zugeschrieben: der schnellen Einführung neuer Modelle wie EfficientNet oder ViT, der Fähigkeit, nicht durch die Websuche identifizierte Modelle durch menschliches Eingreifen zu integrieren und den automatischen Korrekturen, die durch die Leck- und Datenverwendungsprüfer vorgenommen werden.
Das wissenschaftliche Papier auf arXiv finden Sie hier : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
DerOpen-Source-Code ist auf GitHub verfügbar.