Alibaba kündigte am 21. Juli auf X die Veröffentlichung des neuesten Updates seines LLM Qwen 3 an: Qwen3-235B-A22B-Instruct-2507. Das Open-Source-Modell, das unter der Apache 2.0-Lizenz vertrieben wird, verfügt über 235 Milliarden Parameter und präsentiert sich als ernstzunehmender Konkurrent zu DeepSeek‑V3, Claude Opus 4 von Anthropic, GPT-4o von OpenAI oder Kimi 2, das kürzlich vom chinesischen Start-up Moonshot gestartet wurde, viermal so groß.
Alibaba Cloud erläutert in seinem Beitrag:
"Nach Diskussionen mit der Community und Überlegungen haben wir uns entschieden, den hybriden Denkmodus aufzugeben. Wir werden die Instruct- und Thinking-Modelle nun separat trainieren, um die bestmögliche Qualität zu erzielen."
Qwen3-235B-A22B-Instruct-2507 ist ein nicht-denkendes Modell, das heißt, es führt keine komplexen Kettenüberlegungen durch, sondern legt Wert auf Schnelligkeit und Relevanz bei der Ausführung von Anweisungen.
Dank dieser strategischen Ausrichtung macht Qwen 3 nicht nur Fortschritte beim Befolgen von Anweisungen, sondern zeigt auch Verbesserungen im logischen Denken, im feinen Verständnis spezialisierter Bereiche, in der Verarbeitung seltener Sprachen sowie in Mathematik, Wissenschaft, Programmierung und Interaktion mit digitalen Werkzeugen.
Bei offenen Aufgaben, die Urteilskraft, Tonalität oder Kreativität erfordern, passt es sich besser an die Erwartungen der Nutzer an, mit nützlicheren Antworten und einem natürlicheren Generierungsstil.
Sein Kontextfenster, das auf 256.000 Tokens erweitert wurde, ist nun achtmal größer, was es ihm ermöglicht, umfangreiche Dokumente zu verarbeiten.
Eine Architektur, die auf Flexibilität und Effizienz ausgerichtet ist
Das Modell basiert auf einer Mixture-of-Experts (MoE)-Architektur mit 128 spezialisierten Experten, von denen 8 je nach Anfrage ausgewählt werden: Von seinen 235 Milliarden Parametern werden pro Anfrage nur 22 Milliarden aktiviert.
Es stützt sich auf 94 Tiefenschichten, ein optimiertes GQA (Grouped Query Attention)-Schema: 64 Köpfe für die Anfrage (Q) und 4 für Schlüssel/Werte.
Leistungen von Qwen3-235B-A22B-Instruct-2507
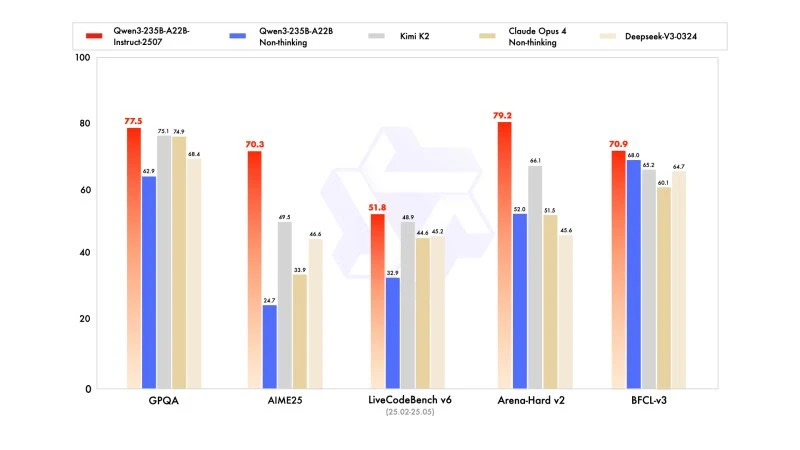
Die neue Version zeigt wettbewerbsfähige, wenn nicht sogar überlegene Ergebnisse gegenüber den Modellen der führenden Konkurrenten, insbesondere in Mathematik, Codierung und logischem Denken.
In Allgemeinwissen erzielte es 83,0 Punkte auf MMLU-Pro (gegenüber 75,2 der vorherigen Version) und 93,1 auf MMLU-Redux und nähert sich dem Niveau von Claude Opus 4 (94,2).
Im fortgeschrittenen Denken erreichte es in der mathematischen Modellierung einen sehr hohen Score: 70,3 auf der AIME (American Invitational Mathematics Examination) 2025, was die Scores von 46,6 von DeepSeek-V3-0324 und 26,7 von GPT-4o-0327 von OpenAI übertrifft.
In der Codierung liegt sein Score von 87,9 auf MultiPL-E hinter Claude (88,5), aber vor GPT-4o und DeepSeek. Auf LiveCodeBench v6 erreicht es 51,8, die beste gemessene Leistung bei diesem Benchmark.
Quantisierte Version in FP8: Optimierung ohne Kompromisse
Gleichzeitig mit Qwen3-235B-A22B-Instruct-2507 hat Alibaba seine quantisierte Version in FP8 veröffentlicht. Dieses komprimierte digitale Format reduziert drastisch den Speicherbedarf und beschleunigt die Inferenz, sodass das Modell in ressourcenbeschränkten Umgebungen arbeiten kann, ohne signifikante Leistungseinbußen in Kauf zu nehmen.