
TLDR : الشركة الناشئة الصينية DeepSeek قامت بتحديث نموذجها R1، مما حسن أداءه في الاستنتاج، المنطق، الرياضيات والبرمجة. هذا التحديث، الذي يقلل الأخطاء ويحسن التكامل التطبيقي، يسمح لـ R1 بالتنافس مع نماذج رائدة مثل o3 من Open AI وGemini 2.5 Pro من Google.
المحتوى
بينما كانت التكهنات تدور حول الإطلاق القادم لـ DeepSeek R2، أعلنت الشركة الناشئة الصينية في 28 مايو عن تحديث نموذجها R1. تم تسمية النسخة الجديدة DeepSeek-R1-0528، وهي تعزز قدرات R1 في مجالات رئيسية مثل التفكير المنطقي، الرياضيات، والبرمجة. الآن، تقترب أداءات هذا النموذج open source المنشور بموجب ترخيص MIT من أداءات النماذج الرئيسية مثل o3 من Open AI وGemini 2.5 Pro من Google.
تحسينات كبيرة في إدارة المهام المعقدة للتفكير
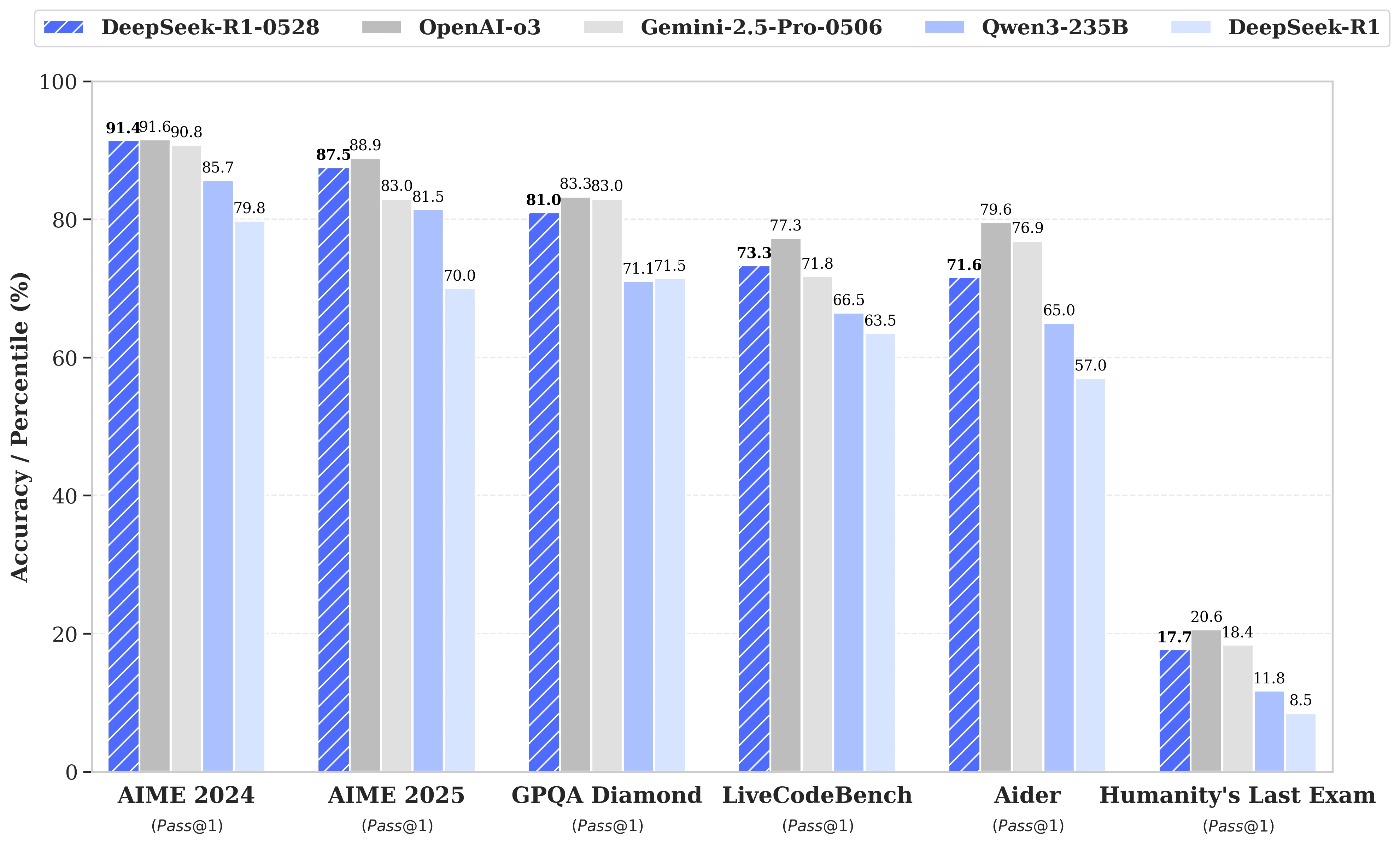
يعتمد التحديث على استغلال أكثر فعالية لموارد الحوسبة المتاحة، مقترنة بسلسلة من التحسينات الخوارزمية التي تم تنفيذها بعد التدريب. هذه التعديلات تؤدي إلى زيادة العمق في التفكير أثناء عملية الاستنتاج: بينما كانت النسخة السابقة تستهلك في المتوسط 12,000 رمز لكل سؤال في اختبارات AIME، يستخدم DeepSeek-R1-0528 الآن ما يقرب من 23,000، مع تحسن ملحوظ في الدقة، من 70% إلى 87.5% في إصدار 2025 من الاختبار.
- في الرياضيات، تصل الدرجات المسجلة إلى 91.4% (AIME 2024) و79.4% (HMMT 2025)، تقترب أو تتجاوز أداءات بعض النماذج المغلقة مثل o3 أو Gemini 2.5 Pro;
- في البرمجة، يتقدم مؤشر LiveCodeBench بحوالي 10 نقاط (من 63.5 إلى 73.3%)، وتزيد تقييمات SWE Verified من 49.2% إلى 57.6% في النجاح;
- في التفكير العام، يشهد اختبار GPQA-Diamant ارتفاعًا في درجة النموذج من 71.5% إلى 81.0%، بينما بالنسبة للمعيار "آخر اختبار للبشرية"، تضاعفت النسبة أكثر من الضعف، من 8.5% إلى 17.7%.
تقليل الأخطاء وتحسين التكامل التطبيقي
من بين التطورات البارزة التي جلبها هذا التحديث، نلاحظ تخفيضًا كبيرًا في معدل الهلوسة، وهو تحدٍ حاسم لموثوقية LLMs. من خلال تقليل تكرار الردود غير الدقيقة من الناحية الواقعية، يكتسب DeepSeek-R1-0528 مزيدًا من المتانة، خاصة في السياقات التي تتطلب الدقة.
يقدم التحديث أيضًا ميزات موجهة للاستخدام في بيئة منظمة، مثل التوليد المباشر للمخرجات بتنسيق JSON ودعم موسع لاستدعاء الدوال. هذه التقدمات التقنية تبسط تكامل النموذج في سير العمل الآلي، الوكلاء البرمجيين أو الأنظمة الخلفية، دون الحاجة إلى معالجة وسيطة ثقيلة.
اهتمام متزايد بالتقطير
بالتوازي، بدأ فريق DeepSeek في عملية تقطير سلاسل التفكير نحو نماذج أخف، للمطورين أو الباحثين الذين يمتلكون معدات محدودة. تم استخدام DeepSeek-R1-0528 الذي يحتوي على 685 مليار معلمة، لتدريب Qwen3 8B Base بعد ذلك.
النموذج الناتج، DeepSeek-R1-0528-Qwen3-8B، يتمكن من معادلة نماذج open source أكبر بكثير في بعض المعايير. بدرجة 86.0% في AIME 2024، يتجاوز ليس فقط درجة Qwen3 8B بأكثر من 10.0% ولكنه يعادل أداءات Qwen3-235B-thinking.
نهج يثير التساؤلات حول جدوى النماذج الضخمة المستقبلية، مقابل نسخ أكثر اقتصادًا ولكن مدربة بشكل أفضل على التفكير.
"نعتقد أن سلسلة التفكير لـ DeepSeek-R1-0528 ستكون ذات أهمية كبيرة سواء للبحث الأكاديمي حول نماذج التفكير أو للتطوير الصناعي الذي يركز على النماذج الصغيرة الحجم".