У короткому : Дослідники Google розробили MLE-STAR, агент машинного навчання, що покращує процес створення моделей ШІ через цільовий веб-пошук, вдосконалення коду та адаптивне складання. MLE-STAR перевершив попередні підходи, вигравши 63% змагань у бенчмарку MLE-Bench-Lite на основі Kaggle.
Зміст
Агенти MLE (Machine Learning Engineering agent), засновані на великих мовних моделях (LLM), відкрили нові перспективи у розробці моделей машинного навчання, автоматизуючи весь або частину процесу. Однак існуючі рішення часто стикаються з обмеженнями дослідження або браком методологічної різноманітності. Дослідники Google відповідають на ці виклики з MLE-STAR, агентом, який поєднує цільовий веб-пошук, детальне вдосконалення блоків коду та адаптивну стратегію складання.
Конкретно, агент MLE починає з опису завдання (наприклад, "прогнозування продажів на основі табличних даних") та наданих наборів даних, потім:
- Аналізує проблему та обирає відповідний підхід;
- Генерує код (часто на Python, з використанням загальних або спеціалізованих ML-бібліотек);
- Тестує, оцінює та вдосконалює рішення, іноді в кілька ітерацій.
Ці агенти спираються на дві ключові навички LLM:
- Алгоритмічне мислення (визначення відповідних методів для конкретної проблеми);
- Генерація виконуваного коду (повні скрипти для підготовки даних, навчання та оцінки).
Їх мета - зменшення навантаження на людину, автоматизуючи трудомісткі етапи як інженерія характеристик, налаштування гіперпараметрів або вибір моделей.
MLE-STAR: цілеспрямована та ітеративна оптимізація
Згідно з Google Research, існуючі MLE стикаються з двома основними перешкодами. По-перше, їхня сильна залежність від внутрішніх знань LLM змушує їх віддавати перевагу загальним і добре встановленим методам, таким як бібліотека scikit-learn для табличних даних, на шкоду більш спеціалізованим і потенційно більш продуктивним підходам.
По-друге, їхня стратегія дослідження часто базується на повній переписці коду на кожній ітерації. Це заважає їм зосередити свої зусилля на специфічних компонентах конвеєра, наприклад, систематично тестувати різні варіанти інженерії характеристик, перш ніж переходити до інших етапів.
По-друге, їхня стратегія дослідження часто базується на повній переписці коду на кожній ітерації. Це заважає їм зосередити свої зусилля на специфічних компонентах конвеєра, наприклад, систематично тестувати різні варіанти інженерії характеристик, перш ніж переходити до інших етапів.
Щоб подолати ці обмеження, дослідники Google розробили MLE-STAR, агент, який поєднує три важелі:
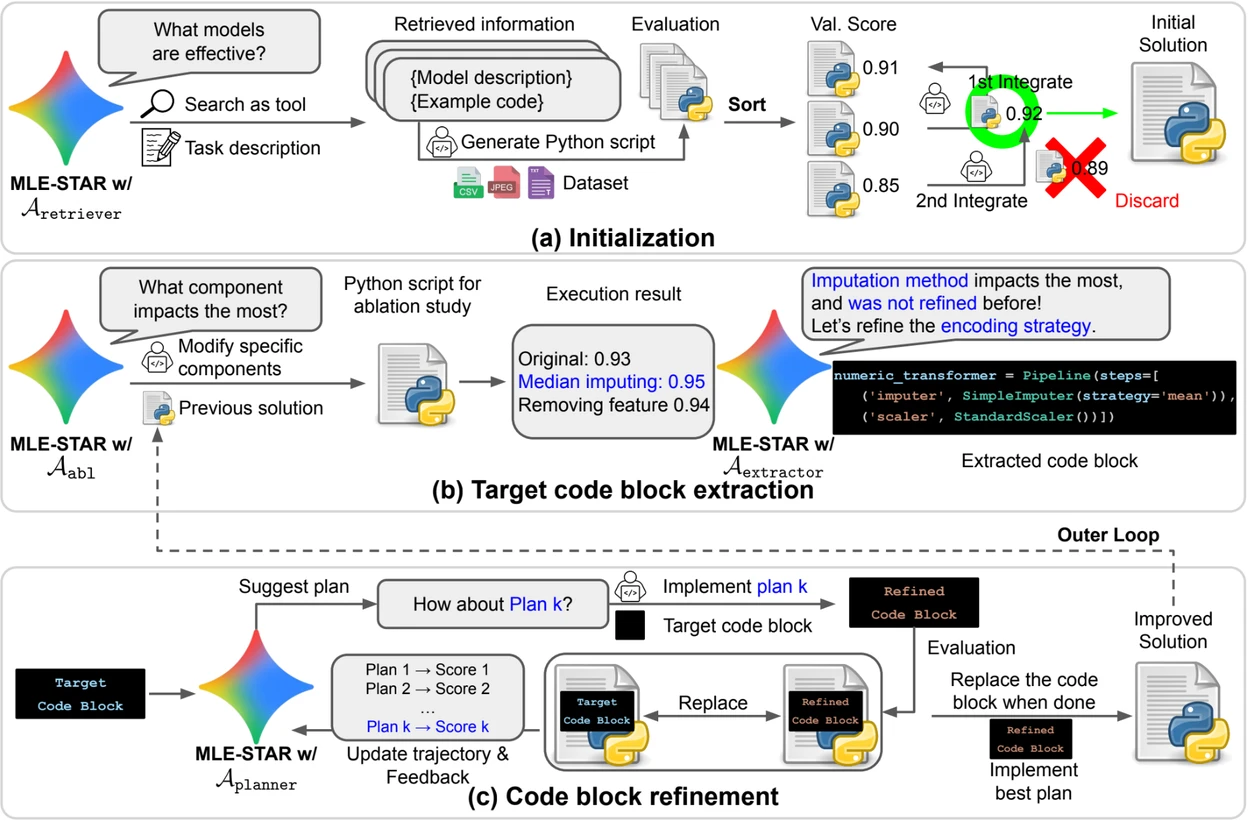
- Веб-пошук для виявлення специфічних для завдання моделей і формування потужного початкового рішення;
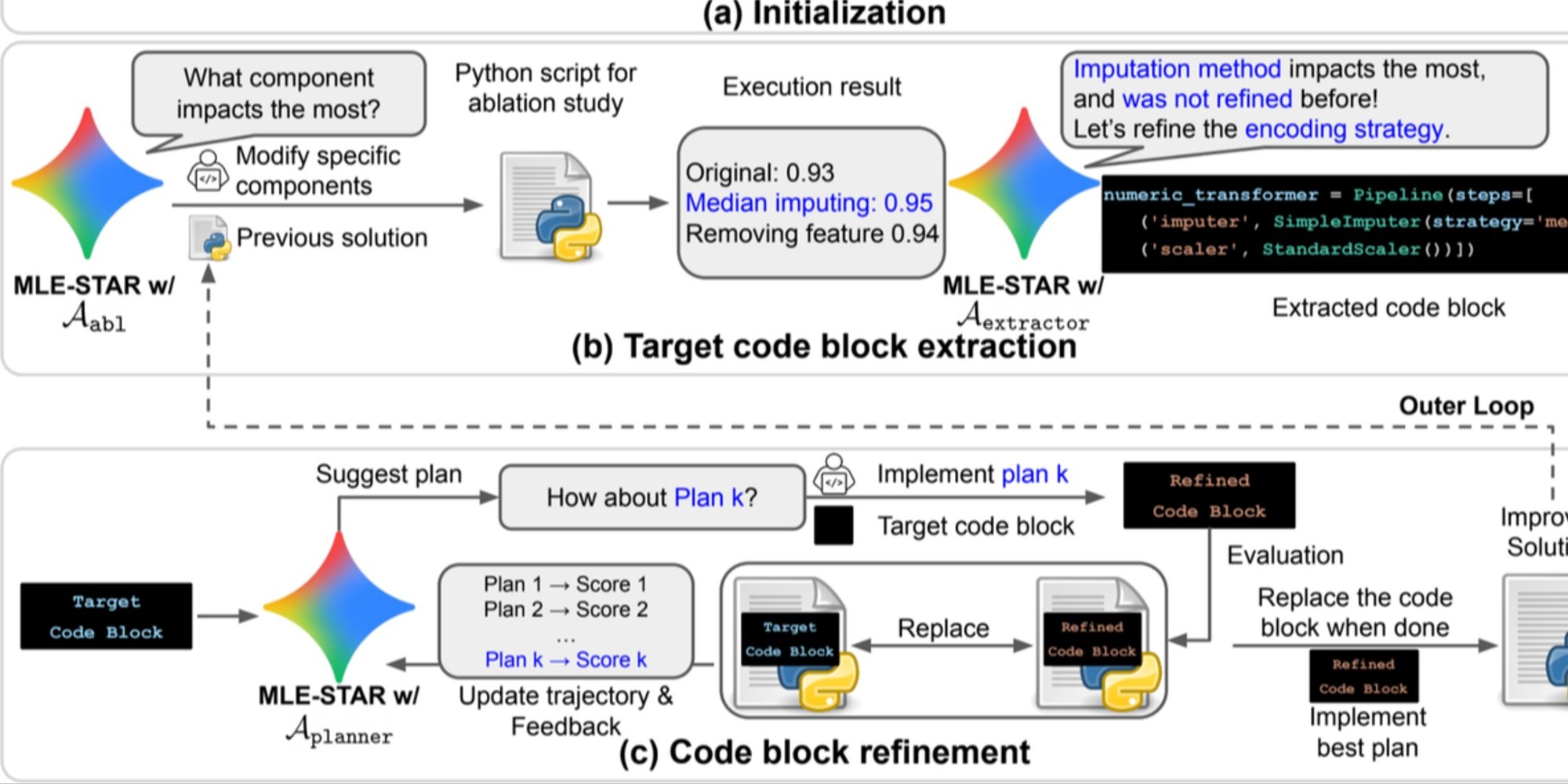
- Детальне вдосконалення за блоками коду, спираючись на дослідження абляції для виявлення частин, які мають найбільший вплив на продуктивність, і потім ітеративно їх оптимізуючи;
- Адаптивна стратегія складання, здатна об'єднувати кілька кандидатних рішень у покращену версію, вдосконалену з кожною спробою.
Цей ітеративний процес, пошук, ідентифікація критичного блоку, оптимізація, а потім нова ітерація, дозволяє MLE-STAR зосередити свої зусилля там, де вони приносять найбільшу вимірювану вигоду.
Кредит: Google Research.
Огляд. a) MLE-STAR починає з використання веб-пошуку для знаходження та інтеграції специфічних для завдання моделей у початкове рішення. (b) Для кожного етапу вдосконалення він проводить дослідження абляції, щоб визначити блок коду, що має найбільший вплив на продуктивність. (c) Ідентифікований блок коду потім піддається ітеративному вдосконаленню на основі планів, запропонованих LLM, які досліджують різні стратегії, використовуючи відгуки з попередніх експериментів. Цей процес вибору та вдосконалення цільових блоків коду повторюється, де покращене рішення з (c) стає відправною точкою для наступного етапу вдосконалення (b).
Модулі контролю для підвищення надійності рішень
Крім ітеративного підходу, MLE-STAR інтегрує три модулі, призначені для зміцнення надійності згенерованих рішень:
- Агент налагодження для аналізу помилок виконання (наприклад, traceback Python) і пропонування автоматичних виправлень;
- Перевірка витоку даних для виявлення ситуацій, коли інформація з тестових даних неправильно використовується під час навчання, що спотворює вимірювану продуктивність;
- Перевірка використання даних для забезпечення використання всіх наданих джерел даних, навіть коли вони не представлені у стандартних форматах, таких як CSV.
Ці модулі відповідають на загальні проблеми, які спостерігаються в коді, згенерованому LLM.
Значущі результати на Kaggle
Щоб оцінити ефективність MLE-STAR, дослідники протестували його в рамках бенчмарку MLE-Bench-Lite, заснованого на змаганнях Kaggle. Протокол вимірював здатність агента генерувати, з простої опису завдання, повне та конкурентоспроможне рішення.
Результати показують, що MLE-STAR отримав медаль у 63% змагань, з них 36% золота, на противагу 25,8% до 36,6% для попередніх підходів. Це покращення пояснюється поєднанням кількох факторів: швидким прийняттям нових моделей, таких як EfficientNet або ViT, здатністю інтегрувати не виявлені веб-пошуком моделі завдяки точковому людському втручанню, і автоматичними виправленнями, внесеними перевіряючими витоки та використання даних.
Знайти наукову статтю на arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
Код відкритий код доступний на GitHub