21 липня Alibaba оголосила на X про випуск останнього оновлення свого LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. Ця модель з відкритим кодом, поширювана під ліцензією Apache 2.0, містить 235 мільярдів параметрів і є серйозним конкурентом для DeepSeek‑V3, Claude Opus 4 від Anthropic, GPT-4o від OpenAI або Kimi 2, запущеної нещодавно китайським стартапом Moonshot, яка у чотири рази більша.
Alibaba Cloud зазначила у своєму повідомленні:
"Після обговорення з громадськістю та роздумів над питанням, ми вирішили відмовитися від режиму гібридного мислення. З цього часу ми будемо тренувати моделі Instruct та Thinking окремо, щоб досягти найкращої можливої якості".
Qwen3-235B-A22B-Instruct-2507 є немислячою моделлю (non-thinking), тобто вона не здійснює складних ланцюгових розмірковувань, а надає перевагу швидкості та релевантності при виконанні інструкцій.
Завдяки цій стратегічній орієнтації, Qwen 3 не лише прогресує у виконанні інструкцій, а й демонструє покращення в логічному мисленні, детальному розумінні спеціалізованих сфер, обробці рідковживаних мов, а також у математиці, науках, програмуванні та взаємодії з цифровими інструментами.
У відкритих завданнях, що включають судження, тональність або творення, вона краще відповідає очікуванням користувачів, забезпечуючи більш корисні відповіді та стиль генерації, що є більш природним.
Її контекстуальне вікно, збільшене до 256 000 токенів, було збільшено вісім разів, що дозволяє обробляти великі документи.
Архітектура, орієнтована на гнучкість та ефективність
Модель базується на архітектурі Mixture-of-Experts (MoE), що містить 128 спеціалізованих експертів, з яких 8 обираються залежно від запиту: з її 235 мільярдів параметрів лише 22 мільярди активуються за запитом.
Вона спирається на 94 шари глибини, оптимізовану схему GQA (Grouped Query Attention): 64 голови для запиту (Q) та 4 для ключів/значень.
Продуктивність Qwen3‑235B‑A22B‑Instruct‑2507
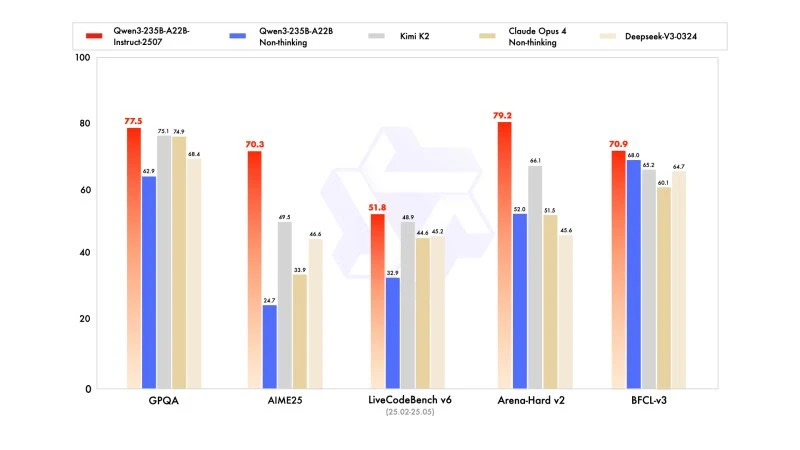
Нова версія демонструє конкурентоспроможні, а іноді й вищі результати, ніж моделі від провідних конкурентів, зокрема у математиці, кодуванні та логічному мисленні.
У загальних знаннях вона отримала 83,0 балів на MMLU-Pro (проти 75,2 для попередньої версії) та 93,1 на MMLU-Redux, наближаючись до рівня Claude Opus 4 (94,2).
У просунутому мисленні вона досягла дуже високого результату в математичному моделюванні: 70,3 на AIME (American Invitational Mathematics Examination) 2025, перевершивши результати 46,6 від DeepSeek-V3-0324 і 26,7 від GPT-4o-0327 OpenAI.
У кодуванні її результат 87,9 на MultiPL‑E ставить її позаду Claude (88,5), але перед GPT-4o і DeepSeek. На LiveCodeBench v6 вона досягає 51,8, що є найкращим результатом, виміряним на цьому бенчмарку.
Квантифікована версія у FP8: оптимізація без компромісів
Одночасно з Qwen3-235B-A22B-Instruct-2507, Alibaba випустила її квантифіковану версію у FP8. Цей стиснутий цифровий формат значно зменшує потреби в пам'яті та прискорює інференцію, що дозволяє моделі працювати в середовищах з обмеженими ресурсами, без значних втрат продуктивності.