În scurt : Cercetătorii de la Google au dezvoltat MLE-STAR, un agent de învățare automată care îmbunătățește procesul de creare a modelelor de IA prin combinarea căutării web țintite, rafinării codului și asamblării adaptative. MLE-STAR și-a demonstrat eficacitatea câștigând 63% din competițiile din benchmark-ul MLE-Bench-Lite bazat pe Kaggle, depășind cu mult abordările anterioare.
Sumar
Agenții MLE (Machine Learning Engineering agent), bazați pe modele mari de limbaj (LLMs), au deschis noi perspective în dezvoltarea modelelor de învățare automată prin automatizarea întregului sau a unei părți a procesului. Cu toate acestea, soluțiile existente se confruntă adesea cu limite de explorare sau cu o lipsă de diversitate metodologică. Cercetătorii de la Google răspund acestor provocări cu MLE-STAR, un agent care combină căutarea web țintită, rafinarea granulară a blocurilor de cod și o strategie de asamblare adaptativă.
Concret, un agent MLE pornește de la o descriere a sarcinii (de exemplu, „prezice vânzările din datele tabelare”) și seturi de date furnizate, apoi:
- Analizează problema și alege o abordare adecvată;
- Generează cod (adesea în Python, cu biblioteci ML comune sau specializate);
- Testează, evaluează și rafinează soluția, uneori în mai multe iterații.
Acești agenți se bazează pe două competențe cheie ale LLM:
- Raționament algoritmic (identificarea metodelor relevante pentru o problemă dată);
- Generarea de cod executabil (scripturi complete de pregătire a datelor, antrenare și evaluare).
Obiectivul lor este de a reduce volumul de muncă umană prin automatizarea etapelor plictisitoare, cum ar fi ingineria caracteristicilor, ajustarea hiperparametrilor sau selecția modelelor.
MLE-STAR: o optimizare țintită și iterativă
Conform Google Research, agenții MLE existenți se confruntă cu două obstacole majore. În primul rând, dependența lor puternică de cunoștințele interne ale LLM-urilor îi determină să favorizeze metode generice și bine stabilite, cum ar fi biblioteca scikit-learn pentru date tabelare, în detrimentul abordărilor mai specializate și potențial mai performante. Apoi, strategia lor de explorare se bazează adesea pe o rescriere completă a codului la fiecare iterație. Acest mod de funcționare îi împiedică să-și concentreze eforturile asupra componentelor specifice ale fluxului, de exemplu, testarea sistematică a diferitelor opțiuni de inginerie a caracteristicilor, înainte de a trece la alte etape.
Pentru a depăși aceste limite, cercetătorii de la Google au conceput MLE-STAR, un agent care combină trei pârghii:
- Căutare web pentru a identifica modele specifice sarcinii și a construi o soluție inițială solidă;
- Rafinare granulară prin blocuri de cod, bazându-se pe studii de ablație pentru a identifica părțile cu cel mai mare impact asupra performanței, apoi optimizându-le iterativ;
- Strategie de asamblare adaptativă, capabilă să fuzioneze mai multe soluții candidate într-o versiune îmbunătățită, rafinată pe parcursul încercărilor.
Acest proces iterativ, căutare, identificare a blocului critic, optimizare, apoi nouă iterație, permite lui MLE-STAR să-și concentreze eforturile acolo unde produc cele mai mari câștiguri măsurabile.
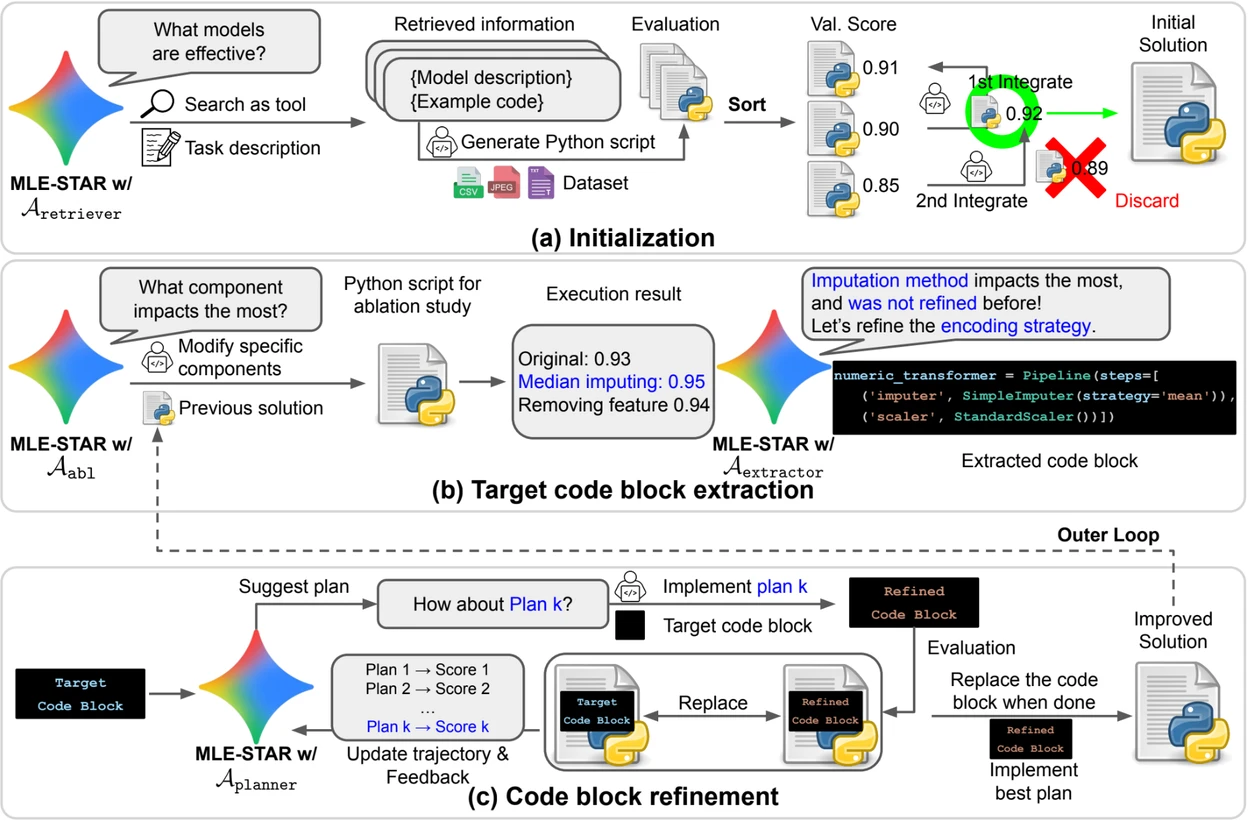
Credit: Google Research.
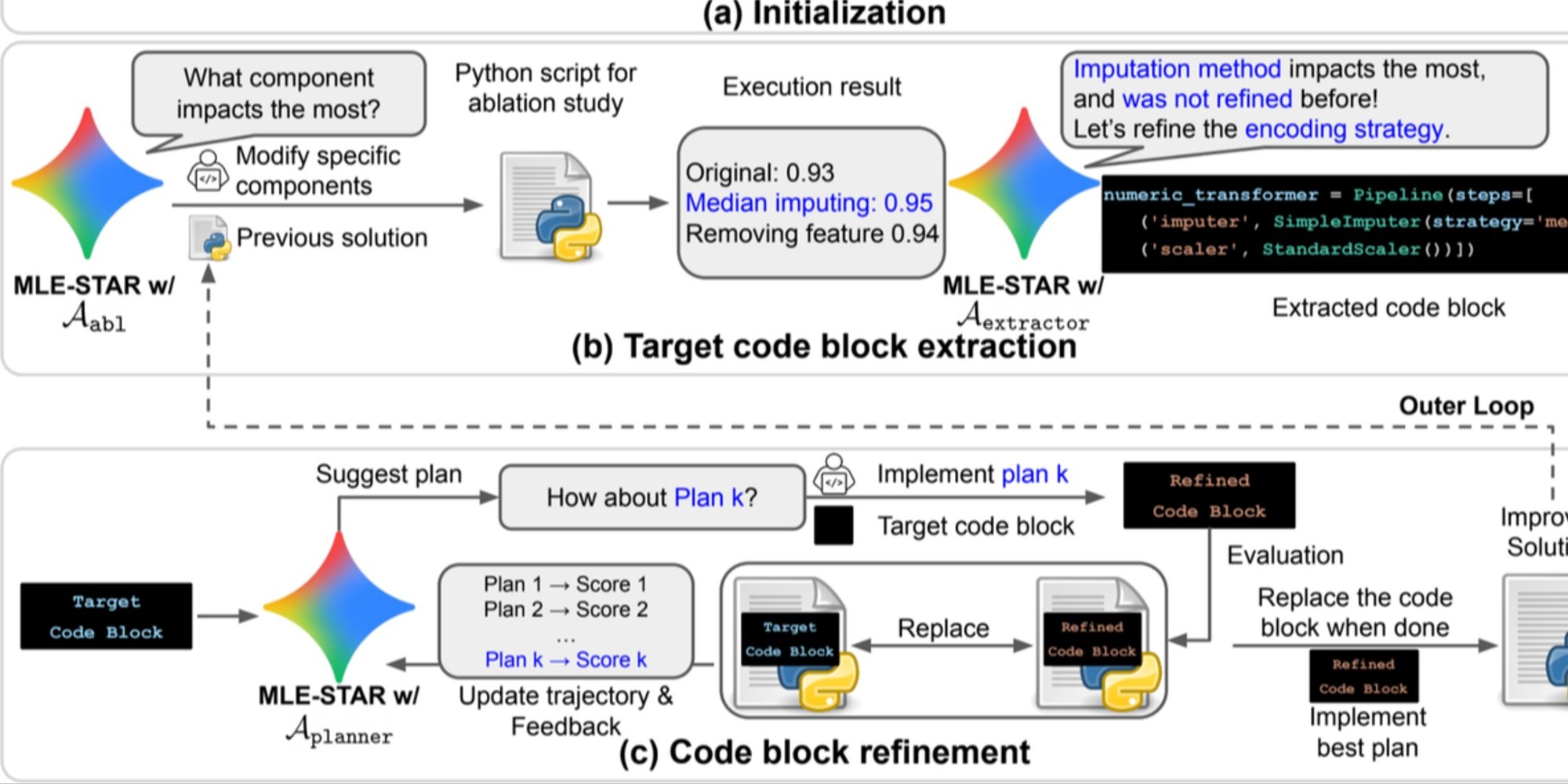
Previzualizare. a) MLE-STAR începe prin utilizarea căutării pe web pentru a găsi și încorpora modele specifice unei sarcini într-o soluție inițială. (b) Pentru fiecare etapă de rafinare, efectuează un studiu de ablație pentru a determina blocul de cod cu cel mai semnificativ impact asupra performanței. (c) Blocul de cod identificat este apoi supus unei rafinări iterative pe baza planurilor sugerate de LLM, care explorează diverse strategii folosind feedback-ul din experiențele anterioare. Acest proces de selecție și rafinare a blocurilor de cod țintă se repetă, unde soluția îmbunătățită de la (c) devine punctul de plecare pentru următoarea etapă de rafinare (b).
Module de control pentru a asigura fiabilitatea soluțiilor
Dincolo de abordarea sa iterativă, MLE-STAR integrează trei module destinate să consolideze robustețea soluțiilor generate:
- Un agent de depanare pentru a analiza erorile de execuție (de exemplu, o traceback Python) și a propune corecții automate;
- Un verificator de scurgeri de date pentru a detecta situațiile în care informații din datele de testare sunt utilizate în mod greșit în timpul antrenamentului, un bias care distorsionează performanțele măsurate;
- Un verificator de utilizare a datelor pentru a asigura că toate sursele de date furnizate sunt exploatate, chiar și atunci când nu sunt prezentate în formate standard, cum ar fi CSV.
Aceste module răspund unor probleme comune observate în codul generat de LLM-uri.
Rezultate semnificative pe Kaggle
Pentru a evalua eficacitatea MLE-STAR, cercetătorii l-au testat în cadrul benchmark-ului MLE-Bench-Lite, bazat pe competiții Kaggle. Protocolul măsura capacitatea unui agent de a produce, dintr-o simplă descriere a sarcinii, o soluție completă și competitivă.
Rezultatele arată că MLE-STAR obține o medalie în 63% din competiții, dintre care 36% de aur, comparativ cu 25,8% la 36,6% pentru cele mai bune abordări anterioare. Acest câștig este atribuit combinației mai multor factori: adoptarea rapidă a modelelor recente, cum ar fi EfficientNet sau ViT, capacitatea de a integra modele neidentificate prin căutarea web datorită intervenției umane ocazionale și corecțiile automate aduse de verificatorii de scurgeri și utilizare a datelor.
Găsiți lucrarea științifică pe arXiv : „MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement” (https://www.arxiv.org/abs/2506.15692).
Codul open source este disponibil pe GitHub