
În scurt : Start-up-ul chinez DeepSeek a actualizat modelul său R1, îmbunătățindu-i performanțele în raționament, logică, matematică și programare. Această actualizare, care reduce erorile și îmbunătățește integrarea aplicativă, permite modelului R1 să concureze cu modele de top precum o3 de la Open AI și Gemini 2.5 Pro de la Google.
Sumar
În timp ce speculațiile erau în plină expansiune în jurul următoarei lansări a DeepSeek R2, a fost în cele din urmă o actualizare a modelului R1 pe care start-up-ul chinez cu același nume a anunțat-o pe 28 mai. Numită DeepSeek-R1-0528, această versiune consolidează capacitățile R1 în domenii-cheie precum raționamentul, logica, matematica și programarea. Acum, performanțele acestui model open source, publicat sub licență MIT, se apropie de cele ale modelelor principale o3 de la Open AI și Gemini 2.5 Pro de la Google.
Îmbunătățiri semnificative în gestionarea sarcinilor complexe de raționament
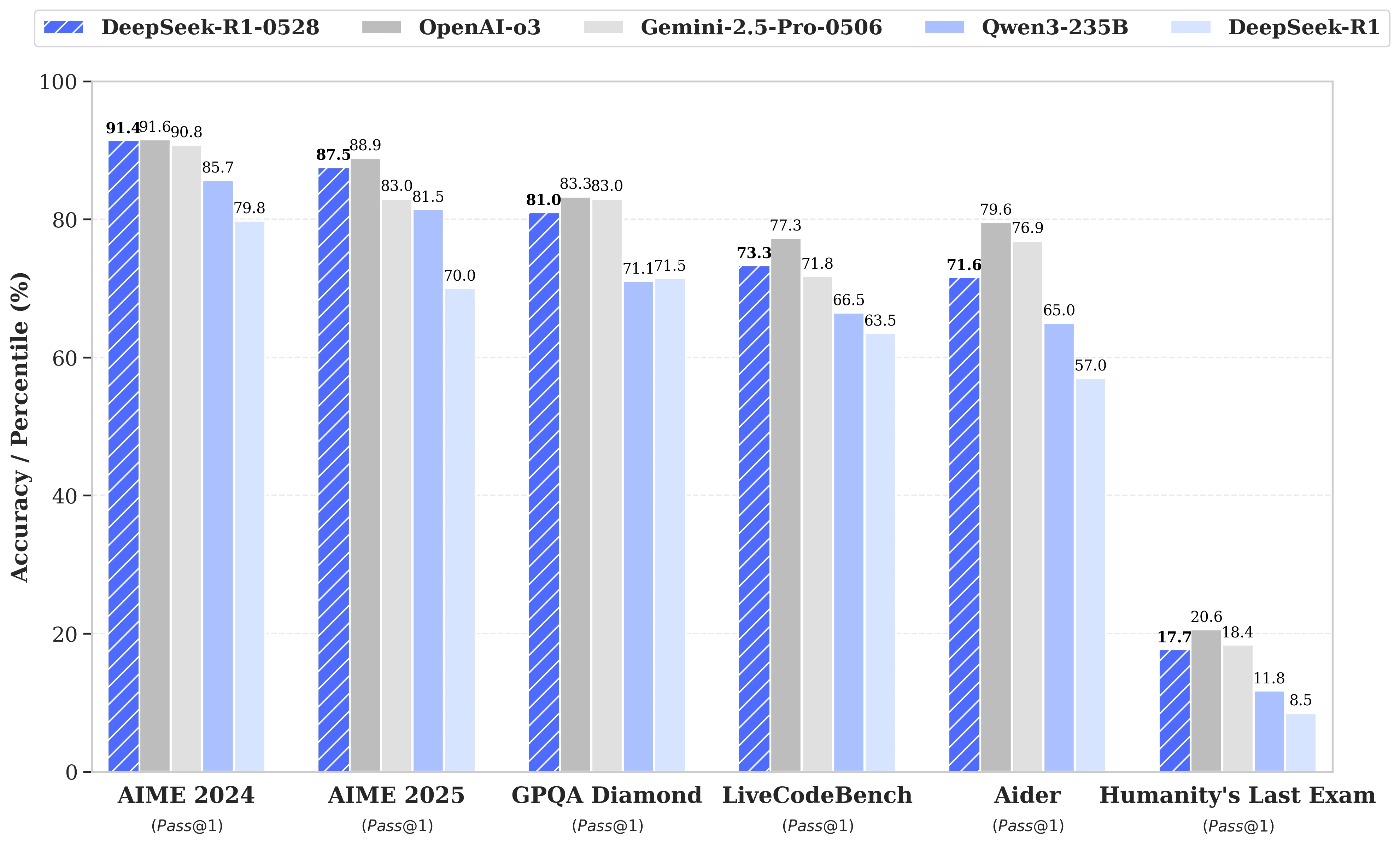
Actualizarea se bazează pe o exploatare mai eficientă a resurselor de calcul disponibile, combinată cu o serie de optimizări algoritmice implementate în post-formare. Aceste ajustări se traduc printr-o adâncime de reflecție sporită în timpul raționamentului: în timp ce versiunea precedentă consuma în medie 12.000 de tokenuri pe întrebare în testele AIME, DeepSeek-R1-0528 folosește acum aproape 23.000, cu o progresie notabilă a preciziei, de la 70% la 87,5% în ediția 2025 a testului.
- În matematică, scorurile înregistrate ajung la 91,4% (AIME 2024) și 79,4% (HMMT 2025), apropiindu-se sau depășind performanțele unor modele închise precum o3 sau Gemini 2.5 Pro;
- În programare, indicele LiveCodeBench progresează cu aproape 10 puncte (de la 63,5 la 73,3%), iar evaluarea SWE Verified crește de la 49,2% la 57,6% succes;
- În raționament general, testul GPQA-Diamant vede scorul modelului crescând de la 71,5% la 81,0%, în timp ce pentru benchmark-ul „Ultimul examen al umanității”, a mai mult decât dublat, crescând de la 8,5% la 17,7%.
Reducerea erorilor și integrare aplicativă îmbunătățită
Printre evoluțiile notabile aduse de această actualizare, se observă o reducere semnificativă a ratei de halucinație, o provocare critică pentru fiabilitatea LLM-urilor. Prin diminuarea frecvenței răspunsurilor factual inexacte, DeepSeek-R1-0528 câștigă în robustețe, în special în contexte unde precizia este esențială.
Actualizarea introduce de asemenea funcționalități orientate către utilizarea în medii structurate, inclusiv generarea directă de ieșiri în format JSON și suport extins pentru apelurile de funcții. Aceste avansuri tehnice simplifică integrarea modelului în fluxuri de lucru automatizate, agenți software sau sisteme back-end, fără a necesita procese intermediare complexe.
O atenție sporită acordată distilării
În paralel, echipa DeepSeek a inițiat un demers de distilare a lanțurilor de gândire către modele mai ușoare, pentru dezvoltatori sau cercetători care dispun de hardware limitat. DeepSeek-R1-0528, care cuprinde 685 de miliarde de parametri, a fost astfel utilizat pentru post-antrenarea Qwen3 8B Base.
Modelul rezultat, DeepSeek-R1-0528-Qwen3-8B, reușește să egaleze modele open source mult mai voluminoase pe unele benchmark-uri. Cu un scor de 86,0% pe AIME 2024, depășește nu doar Qwen3 8B cu peste 10,0% dar egalează performanțele Qwen3-235B-thinking.
O abordare care ridică întrebări despre viabilitatea viitoare a modelelor masive, în fața unor versiuni mai economicoase dar mai bine antrenate în raționament.
DeepSeek afirmă:
„Considerăm că lanțul de gândire al DeepSeek-R1-0528 va avea o importanță semnificativă atât pentru cercetarea academică asupra modelelor de raționament, cât și pentru dezvoltarea industrială axată pe modelele la scară mică”.