Alibaba a anunțat pe 21 iulie pe X publicarea ultimei actualizări a LLM-ului său Qwen 3: Qwen3-235B-A22B-Instruct-2507. Modelul open source, distribuit sub licența Apache 2.0, numără 235 de miliarde de parametri și se prezintă ca un concurent serios pentru DeepSeek-V3, Claude Opus 4 de la Anthropic, GPT-4o de la OpenAI sau Kimi 2 lansat recent de start-up-ul chinezesc Moonshot, de patru ori mai mare.
Alibaba Cloud precizează în postarea sa:
„După ce am discutat cu comunitatea și am reflectat asupra întrebării, am decis să renunțăm la modul de gândire hibrid. Vom antrena de acum înainte modelele Instruct și Thinking separat pentru a obține cea mai bună calitate posibilă”.
Qwen3-235B-A22B-Instruct-2507 este un model non-reflexiv (non-thinking), adică nu operează un raționament complex în lanț, ci privilegiază rapiditatea și relevanța în execuția instrucțiunilor.
Datorită acestei orientări strategice, Qwen 3 nu se limitează doar la progresul în urmărirea instrucțiunilor, ci afișează și progrese în raționamentul logic, în înțelegerea fină a domeniilor specializate, în tratarea limbilor mai puțin comune, precum și în matematică, științe, programare și interacțiunea cu instrumentele digitale.
În sarcinile deschise, implicând judecată, tonalitate sau creație, se ajustează mai bine la așteptările utilizatorilor, cu răspunsuri mai utile și un stil de generare mai natural.
Fereastra sa contextuală, crescută la 256.000 de tokeni, a fost multiplicată de opt ori, ceea ce îi permite să proceseze acum documente voluminoase.
O arhitectură orientată spre flexibilitate și eficiență
Modelul se bazează pe o arhitectură Mixture-of-Experts (MoE) cu 128 de experți specializați, din care 8 sunt selectați în funcție de cerere: din cei 235 de miliarde de parametri, doar 22 de miliarde sunt astfel activate per cerere.
Se bazează pe 94 de straturi de adâncime, o schemă GQA (Grouped Query Attention) optimizată: 64 de capete pentru cerere (Q) și 4 pentru chei/valori.
Performanțele lui Qwen3-235B-A22B-Instruct-2507
Noua versiune afișează rezultate competitive, chiar superioare, modelelor liderilor concurenți, în special în matematică, codare și raționament logic.
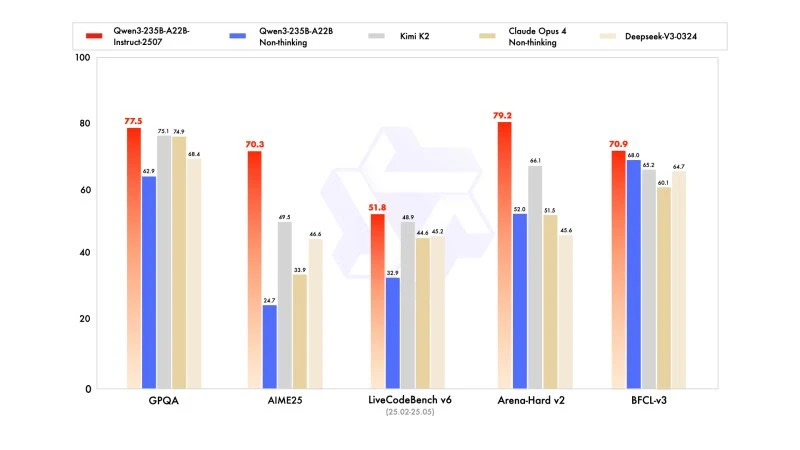
În cunoștințele generale, a obținut un scor de 83,0 pe MMLU-Pro (față de 75,2 pentru versiunea anterioară) și 93,1 pe MMLU-Redux, apropiindu-se de nivelul lui Claude Opus 4 (94,2).
În raționamentul avansat, a atins un scor foarte înalt în modelarea matematică: 70,3 pe AIME (American Invitational Mathematics Examination) 2025, depășind scorurile de 46,6 ale lui DeepSeek-V3-0324 și de 26,7 ale lui GPT-4o-0327 de la OpenAI.
În codare, scorul său de 87,9 pe MultiPL-E îl poziționează în spatele lui Claude (88,5), dar înaintea lui GPT-4o și DeepSeek. Pe LiveCodeBench v6, a atins 51,8, cea mai bună performanță măsurată pe acest benchmark.
Versiunea cuantificată în FP8: optimizare fără compromisuri
În același timp cu Qwen3-235B-A22B-Instruct-2507, Alibaba a publicat versiunea sa cuantificată în FP8. Acest format numeric comprimat reduce drastic nevoile de memorie și accelerează inferența, permițând modelului să funcționeze în medii unde resursele sunt limitate, fără a compromite semnificativ performanța.