
Em resumo : Mistral AI lança Voxtral, modelos de áudio open source que competem com soluções de líderes como OpenAI, apresentando funcionalidades avançadas e acessibilidade via API.
Índice
Na última terça-feira, Mistral AI anunciou o lançamento do Voxtral, sua primeira família de modelos de áudio open source. Projetados para usos profissionais, esses modelos de compreensão da fala marcam a entrada do unicórnio francês no segmento estratégico da inteligência vocal, um domínio até agora dominado por atores como OpenAI, Meta e Google.
A linha Voxtral é dividida em dois modelos principais: Voxtral Small (24 bilhões de parâmetros) e Voxtral Mini (3 bilhões de parâmetros), cada um destinado a ambientes distintos. O modelo Small se posiciona para casos de uso complexos e implantação em nuvem em grande escala, enquanto a versão Mini visa implantações embarcadas ou com recursos limitados. A Mistral AI também oferece o Voxtral Mini Transcribe, uma versão otimizada apenas para transcrição de voz, com uma relação custo-benefício superior à de modelos como Whisper.
Funcionalidades que vão além da transcrição
O Voxtral se propõe como uma alternativa aos sistemas ASR (reconhecimento automático de fala) pouco confiáveis e às APIs fechadas e proprietárias caras.
Projetado para lidar com contextos de áudio longos, ele pode gerenciar até 30 minutos de transcrição ou 40 minutos de compreensão, graças a uma janela de 32.000 tokens.
Baseando-se na arquitetura do modelo linguístico Mistral Small 3.1, ele pode responder a consultas orais, gerar resumos a partir de arquivos de áudio ou transformar uma intenção expressa oralmente em chamada de API ou em fluxo backend. O modelo suporta as línguas mais usadas, incluindo inglês, espanhol, árabe, francês, português, hindi, alemão, neerlandês e italiano.
Desempenho de ponta
De acordo com as primeiras avaliações comunicadas pela Mistral, o Voxtral Small supera o modelo de referência Whisper v3, bem como Gemini 2.5 Flash e GPT-4o Mini Transcribe da Open AI em várias métricas de transcrição automática, enquanto mantém um consumo de recursos controlado.
No FLEURS (abaixo), o Voxtral Small apresenta desempenho de ponta em todas as línguas testadas, com precisão superior ao Whisper.
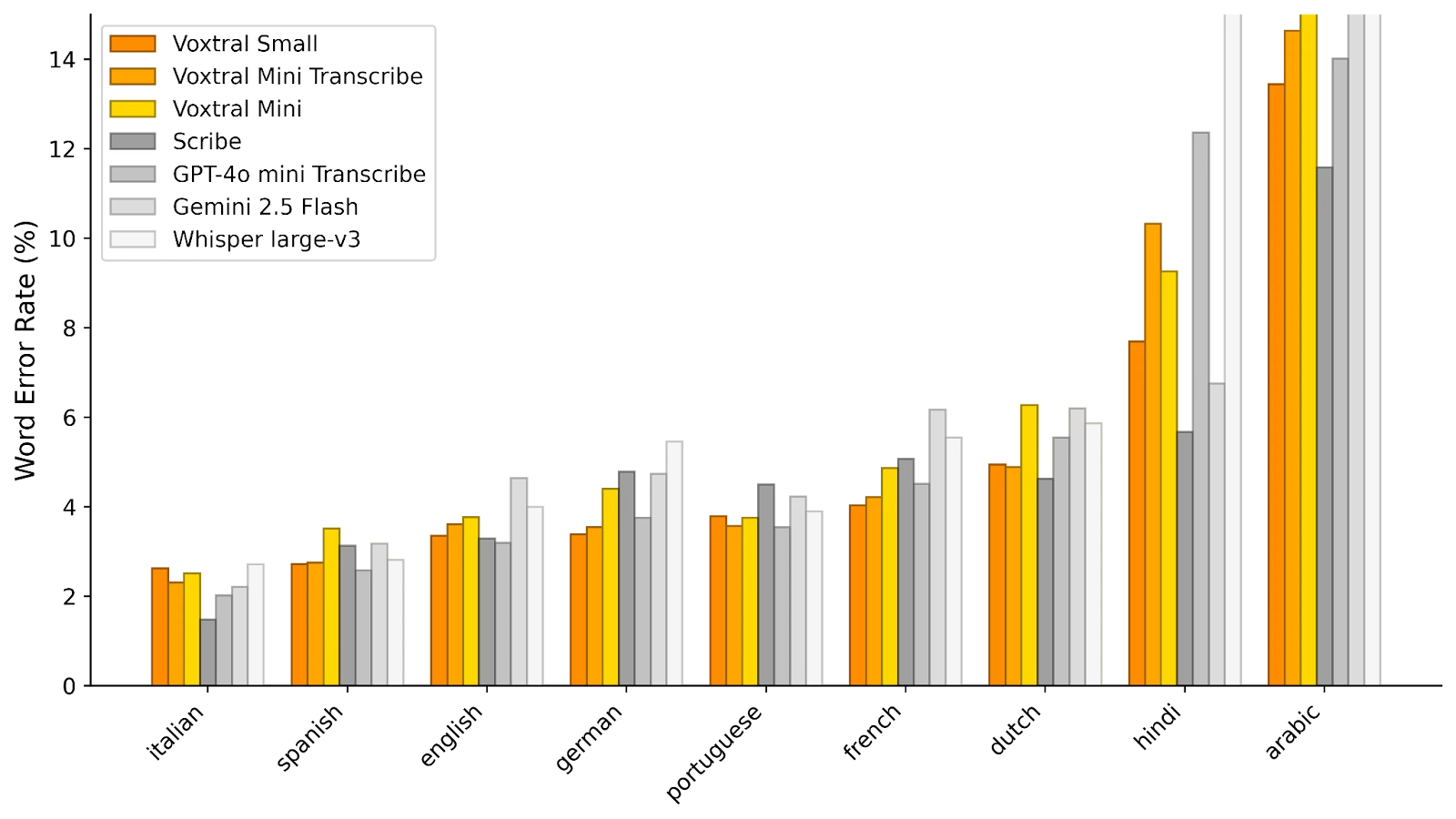
© Mistral AI
Nas tarefas de tradução de voz, o Voxtral Small é competitivo com o GPT-4o Mini e Gemini.
Disponibilidade
Os dois modelos, distribuídos sob a licença Apache 2.0, estão disponíveis para download no Hugging Face. O Voxtral também está acessível via API a partir de $0,001/minuto para aqueles que desejam integrá-lo em seu aplicativo, representando menos da metade do custo das ofertas concorrentes, e em breve enriquecerá o assistente de conversação da Mistral AI, Le Chat.
Para contextos empresariais específicos, as empresas podem optar por implantações privadas e seguras, especialmente nos domínios jurídicos ou médicos.
A Mistral AI planeja adicionar novas funcionalidades nos próximos meses, como segmentação de áudio, diarização (identificação de diferentes falantes) ou detecção de emoções.
Uma dinâmica de mercado em expansão
Este lançamento ocorre em um momento em que as soluções de transcrição e análise de áudio estão em alta demanda, com uma aceleração dos casos de uso em suporte ao cliente, análise de interações, documentação automatizada ou assistência vocal. O Voxtral se insere em um espaço já ocupado por iniciativas como Whisper (OpenAI, MIT), SeamlessM4T (Meta, não comercial), ou frameworks como NVIDIA NeMo ou ESPnet.
Mas poucos deles oferecem, até o momento, acesso livre, compreensão semântica integrada e capacidade de acionar ações a partir da voz, em uma única solução.
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale