Os agentes MLE (Machine Learning Engineering agent), baseados em grandes modelos de linguagem (LLMs), abriram novas perspectivas no desenvolvimento de modelos de aprendizado de máquina ao automatizar total ou parcialmente o processo. No entanto, as soluções existentes muitas vezes enfrentam limites de exploração ou falta de diversidade metodológica. Os pesquisadores do Google respondem a esses desafios com MLE-STAR, um agente que combina pesquisa na web direcionada, refinamento granular de blocos de código e estratégia de montagem adaptativa.
Concretamente, um agente MLE começa com uma descrição de tarefa (por exemplo, "predizer vendas a partir de dados tabulares") e conjuntos de dados fornecidos, então:
- Analisa o problema e escolhe uma abordagem adequada;
- Gera código (frequentemente em Python, com bibliotecas ML comuns ou especializadas);
- Testa, avalia e refina a solução, às vezes em várias iterações.
Esses agentes se baseiam em duas competências chave dos LLMs:
- O raciocínio algorítmico (identificar os métodos relevantes para um problema dado);
- A geração de código executável (scripts completos de preparação de dados, treinamento e avaliação).
Seu objetivo é reduzir a carga de trabalho humano ao automatizar etapas tediosas como a engenharia de características, ajuste de hiperparâmetros ou seleção de modelos.
MLE-STAR: uma otimização direcionada e iterativa
De acordo com o Google Research, os MLE existentes enfrentam dois grandes obstáculos. Primeiro, sua forte dependência dos conhecimentos internos dos LLMs os leva a privilegiar métodos genéricos e bem estabelecidos, como a biblioteca scikit-learn para dados tabulares, em detrimento de abordagens mais especializadas e potencialmente mais eficazes.
Em seguida, sua estratégia de exploração muitas vezes se baseia em uma reescrita completa do código a cada iteração. Esse funcionamento os impede de concentrar esforços em componentes específicos do pipeline, por exemplo, testar sistematicamente diferentes opções de engenharia de características, antes de passar para outras etapas.
Em seguida, sua estratégia de exploração muitas vezes se baseia em uma reescrita completa do código a cada iteração. Esse funcionamento os impede de concentrar esforços em componentes específicos do pipeline, por exemplo, testar sistematicamente diferentes opções de engenharia de características, antes de passar para outras etapas.
Para superar esses limites, os pesquisadores do Google conceberam o MLE-STAR, um agente que combina três alavancas:
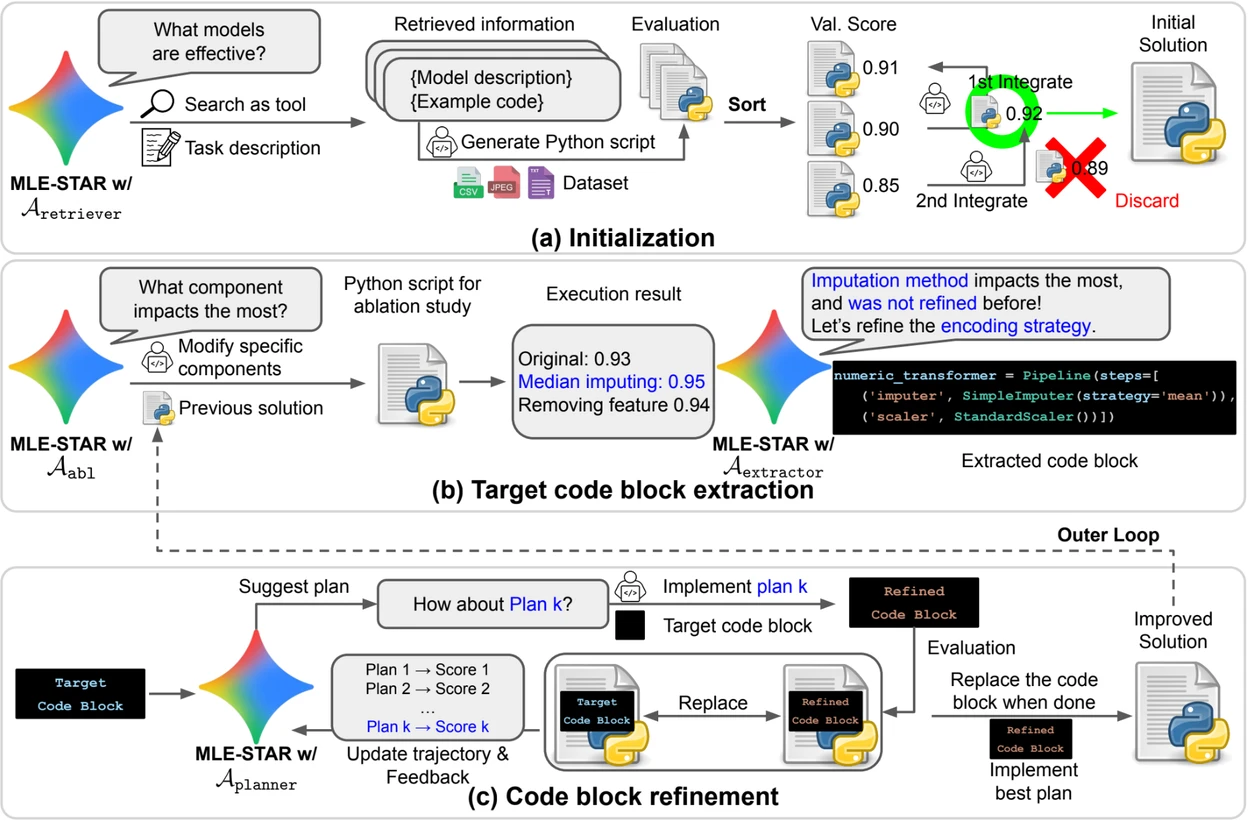
- Pesquisa na web para identificar modelos específicos para a tarefa e constituir uma solução inicial sólida;
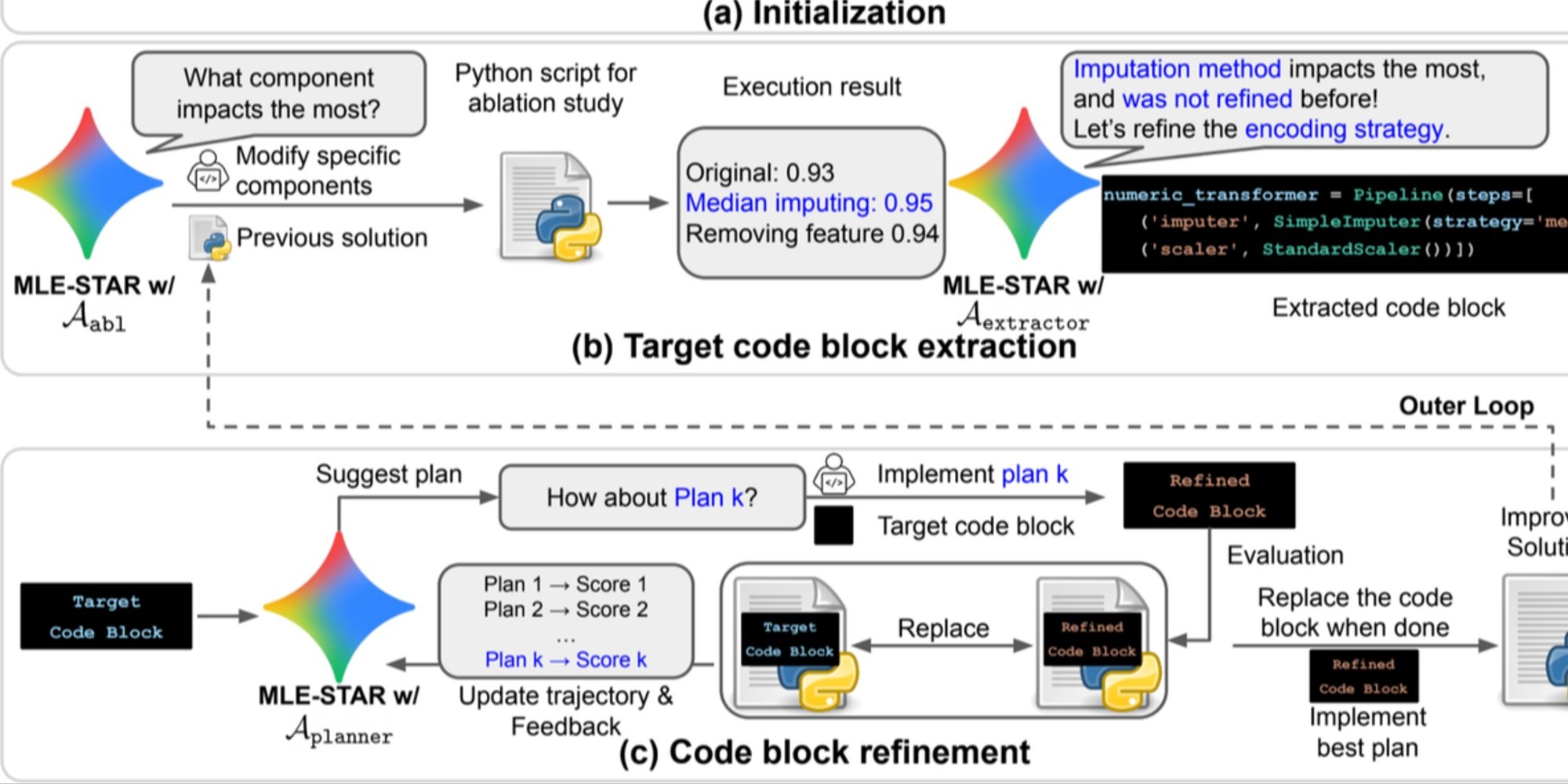
- Refinamento granular por blocos de código, baseando-se em estudos de ablação para identificar as partes com maior impacto sobre o desempenho, e depois otimizando iterativamente;
- Estratégia de montagem adaptativa, capaz de fundir várias soluções candidatas em uma versão melhorada, refinada ao longo das tentativas.
Esse processo iterativo, pesquisa, identificação do bloco crítico, otimização, depois nova iteração, permite ao MLE-STAR concentrar seus esforços onde produzem os maiores ganhos mensuráveis.
Crédito: Google Research.
Visão geral. a) MLE-STAR começa usando a pesquisa na Web para encontrar e incorporar modelos específicos para uma tarefa em uma solução inicial. (b) Para cada etapa de refinamento, realiza um estudo de ablação para determinar o bloco de código com o impacto mais significativo sobre o desempenho. (c) O bloco de código identificado passa então por um refinamento iterativo baseado nos planos sugeridos por LLM, que exploram diversas estratégias usando os feedbacks das experiências anteriores. Esse processo de seleção e refinamento dos blocos de código alvo se repete, onde a solução melhorada de (c) se torna o ponto de partida da próxima etapa de refinamento (b).
Módulos de controle para assegurar a confiabilidade das soluções
Além de sua abordagem iterativa, o MLE-STAR integra três módulos destinados a reforçar a robustez das soluções geradas:
- Um agente de depuração para analisar erros de execução (por exemplo, um traceback Python) e propor correções automáticas;
- Um verificador de fuga de dados para detectar situações onde informações dos dados de teste são usadas erroneamente durante o treinamento, um viés que distorce o desempenho medido;
- Um verificador de uso de dados para garantir que todas as fontes de dados fornecidas sejam exploradas, mesmo quando não se apresentam em formatos padrão como o CSV.
Esses módulos respondem a problemas comuns observados no código gerado por LLMs.
Resultados significativos no Kaggle
Para avaliar a eficácia do MLE-STAR, os pesquisadores o testaram no âmbito do benchmark MLE-Bench-Lite, baseado em competições Kaggle. O protocolo mediu a capacidade de um agente de produzir, a partir de uma simples descrição de tarefa, uma solução completa e competitiva.
Os resultados mostram que o MLE-STAR obtém uma medalha em 63% das competições, das quais 36% em ouro, contra 25,8% a 36,6% para as melhores abordagens anteriores. Esse ganho é atribuído à combinação de vários fatores: a adoção rápida de modelos recentes como EfficientNet ou ViT, a capacidade de integrar modelos não identificados pela pesquisa na web graças a uma intervenção humana pontual, e as correções automáticas feitas pelos verificadores de fugas e uso de dados.
Encontre o artigo científico no arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
O código open source está disponível no GitHub