
Em resumo : A start-up chinesa DeepSeek atualizou seu modelo R1, melhorando seu desempenho em raciocínio, lógica, matemática e programação. Esta atualização, que reduz erros e melhora a integração aplicativa, permite que o R1 rivalize com modelos principais como o o3 da Open AI e Gemini 2.5 Pro do Google.
Índice
Enquanto as especulações estavam em alta sobre o próximo lançamento do DeepSeek R2, foi finalmente uma atualização do modelo R1 que a start-up chinesa homônima anunciou no último dia 28 de maio. Batizada de DeepSeek-R1-0528, esta versão fortalece as capacidades do R1 em áreas-chave como raciocínio, lógica, matemática e programação. Agora, o desempenho deste modelo open source publicado sob licença MIT aproxima-se dos modelos principais o3 da Open AI e Gemini 2.5 Pro do Google.
Melhorias significativas na gestão de tarefas complexas de raciocínio
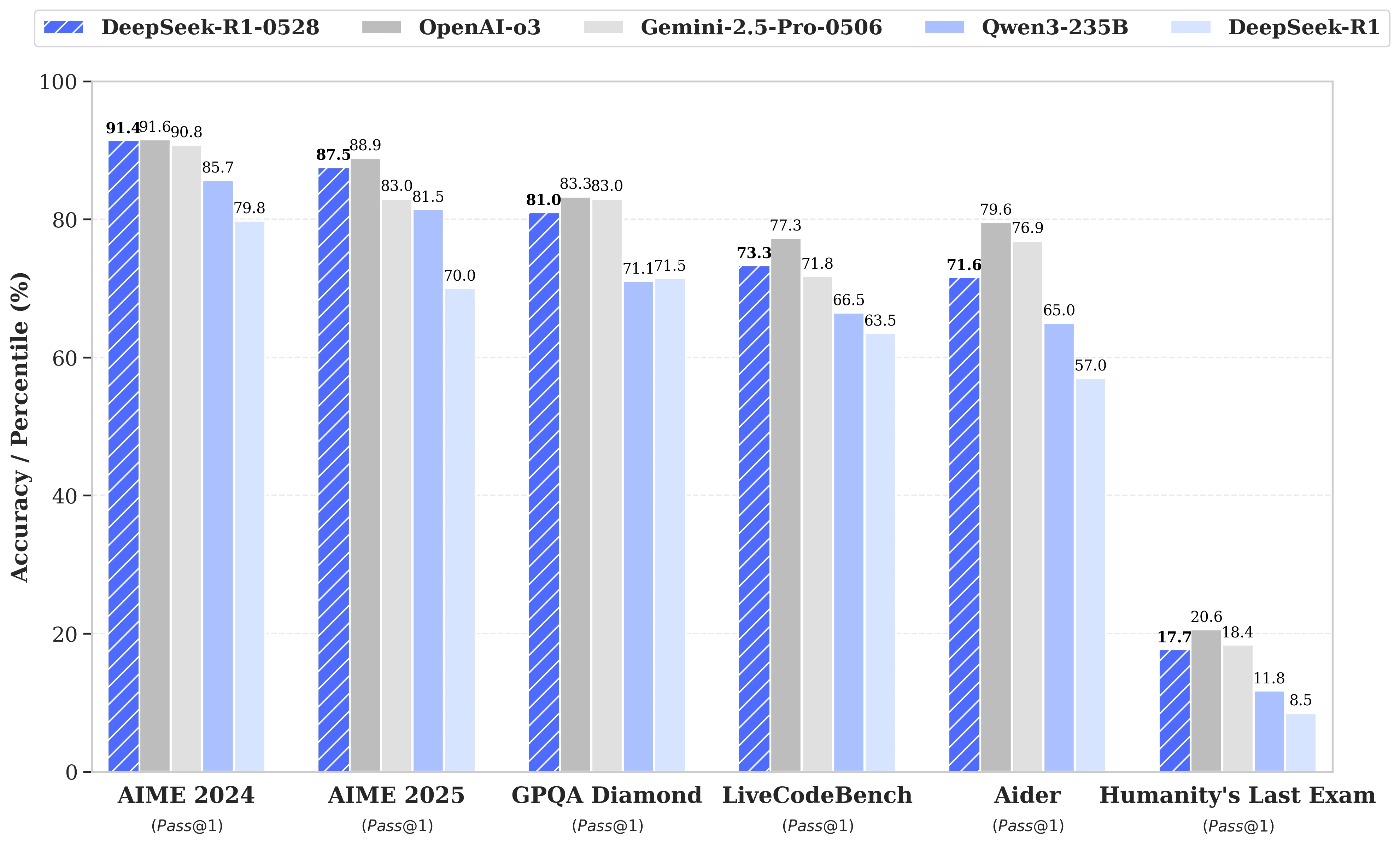
A atualização baseia-se em uma exploração mais eficaz dos recursos de computação disponíveis, combinada com uma série de otimizações algorítmicas implementadas em pós-treinamento. Esses ajustes resultam em uma profundidade de reflexão aumentada durante o raciocínio: enquanto a versão anterior consumia em média 12.000 tokens por questão nos testes AIME, o DeepSeek-R1-0528 agora utiliza cerca de 23.000, com um notável progresso na precisão, de 70% para 87,5% na edição de 2025 do teste.
- Em matemática, as pontuações registradas alcançam 91,4% (AIME 2024) e 79,4% (HMMT 2025), quase ou superando o desempenho de alguns modelos fechados como o o3 ou o Gemini 2.5 Pro;
- Em programação, o índice LiveCodeBench avança cerca de 10 pontos (de 63,5 para 73,3%), e a avaliação SWE Verified sobe de 49,2% para 57,6% de sucesso;
- Em raciocínio geral, o teste GPQA-Diamant vê a pontuação do modelo passar de 71,5% para 81,0%, enquanto para o benchmark "Último exame da humanidade", ele mais que dobrou, passando de 8,5% para 17,7%.
Redução de erros e melhor integração aplicativa
Entre as evoluções notáveis trazidas por esta atualização, observa-se uma redução sensível na taxa de alucinação, um desafio crítico para a confiabilidade dos LLMs. Ao diminuir a frequência de respostas factualmente imprecisas, o DeepSeek-R1-0528 ganha em robustez, especialmente nos contextos onde a precisão é indispensável.
A atualização também introduz funcionalidades orientadas para o uso em ambientes estruturados, incluindo a geração direta de saídas no formato JSON e o suporte ampliado para chamadas de funções. Esses avanços técnicos simplificam a integração do modelo em fluxos de trabalho automatizados, agentes de software ou sistemas back-end, sem a necessidade de pesados processamentos intermediários.
Uma atenção crescente à destilação
Paralelamente, a equipe do DeepSeek iniciou uma abordagem de destilação das cadeias de pensamento para modelos mais leves, para desenvolvedores ou pesquisadores com hardware limitado. O DeepSeek-R1-0528, que conta com 685 B (bilhões) de parâmetros, foi usado para pós-treinar o Qwen3 8B Base.
O modelo resultante, DeepSeek-R1-0528-Qwen3-8B, consegue igualar modelos open source muito mais volumosos em alguns benchmarks. Com uma pontuação de 86,0% no AIME 2024, ele supera não apenas o Qwen3 8B em mais de 10,0% e mas iguala o desempenho do Qwen3-235B-thinking.
Uma abordagem que questiona a viabilidade futura dos modelos massivos, face a versões mais frugais mas melhor treinadas para raciocinar.
DeepSeek afirma :
"Acreditamos que a cadeia de pensamento do DeepSeek-R1-0528 terá uma importância significativa tanto para a pesquisa acadêmica sobre modelos de raciocínio quanto para o desenvolvimento industrial focado em modelos de pequena escala".