A Alibaba anunciou em 21 de julho passado no X a publicação da última atualização do seu LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. O modelo de código aberto, distribuído sob licença Apache 2.0, conta com 235 bilhões de parâmetros e se apresenta como um sério concorrente para DeepSeek-V3, Claude Opus 4 da Anthropic, GPT-4o da OpenAI ou Kimi 2 lançado recentemente pela start-up chinesa Moonshot, quatro vezes maior.
Alibaba Cloud esclarece em seu post:
"Após discutir com a comunidade e refletir sobre a questão, decidimos abandonar o modo de pensamento híbrido. Treinaremos agora os modelos Instruct e Thinking separadamente para obter a melhor qualidade possível".
Qwen3-235B-A22B-Instruct-2507 é um modelo não-pensante (non-thinking), ou seja, ele não realiza raciocínios complexos em cadeia, mas privilegia a rapidez e a pertinência na execução das instruções.
Graças a essa orientação estratégica, Qwen 3 não se limita a progredir no seguimento de instruções, mas também exibe avanços em raciocínio lógico, compreensão fina de domínios especializados, tratamento de línguas pouco comuns, bem como em matemática, ciências, programação e interação com ferramentas digitais.
Nas tarefas abertas, envolvendo julgamento, tonalidade ou criação, ele se ajusta melhor às expectativas do usuário, com respostas mais úteis e um estilo de geração mais natural.
Sua janela contextual, ampliada para 256.000 tokens, foi multiplicada por oito, permitindo agora o tratamento de documentos volumosos.
Uma arquitetura orientada para flexibilidade e eficiência
O modelo se baseia em uma arquitetura Mixture-of-Experts (MoE) contando com 128 especialistas, dos quais 8 são selecionados conforme a demanda: de seus 235 bilhões de parâmetros, apenas 22 bilhões são assim ativados por solicitação.
Ele conta com 94 camadas de profundidade, um esquema GQA (Grouped Query Attention) otimizado: 64 cabeças para a consulta (Q) e 4 para as chaves/valores.
Desempenho do Qwen3‑235B‑A22B‑Instruct‑2507
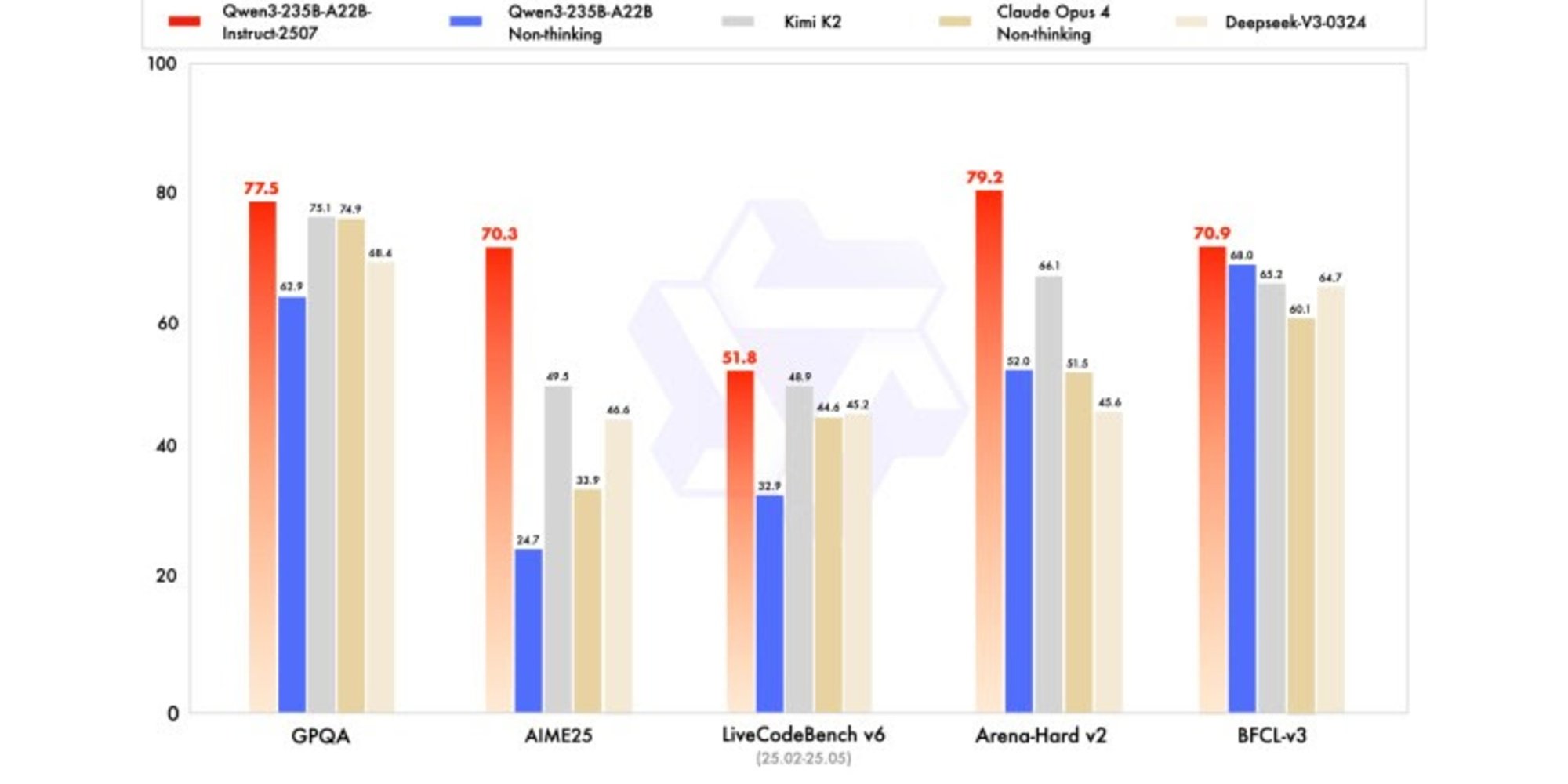
A nova versão exibe resultados competitivos, até mesmo superiores, aos modelos dos líderes concorrentes, notadamente em matemática, codificação e raciocínio lógico.
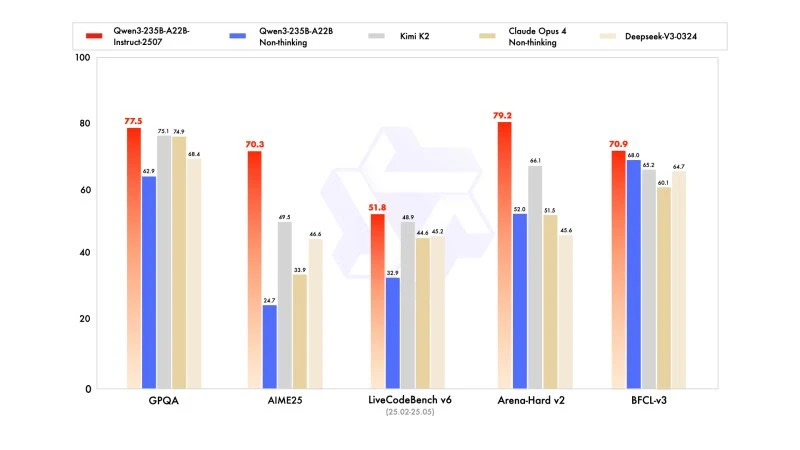
Em conhecimentos gerais, obteve uma pontuação de 83,0 no MMLU-Pro (contra 75,2 para a versão anterior) e 93,1 no MMLU-Redux, aproximando-se do nível de Claude Opus 4 (94,2).
Em raciocínio avançado, alcançou uma pontuação muito elevada em modelagem matemática: 70,3 no AIME (American Invitational Mathematics Examination) 2025, superando as pontuações de 46,6 do DeepSeek-V3-0324 e de 26,7 do GPT-4o-0327 da OpenAI.
Em codificação, sua pontuação de 87,9 no MultiPL-E, o posiciona atrás de Claude (88,5), mas à frente do GPT-4o e DeepSeek. No LiveCodeBench v6, atinge 51,8, a melhor performance medida neste benchmark.
Versão quantificada em FP8: otimização sem compromisso
Ao mesmo tempo que o Qwen3-235B-A22B-Instruct-2507, a Alibaba publicou sua versão quantificada em FP8. Este formato numérico comprimido reduz drasticamente as necessidades de memória e acelera a inferência, permitindo que o modelo funcione em ambientes onde os recursos são limitados, sem causar perda significativa de desempenho.