
W skrócie : Mistral AI uruchomiło Voxtral, modele głosowe open source dla zastosowań profesjonalnych, konkurując z OpenAI i Google w zakresie inteligencji głosowej.
Podsumowanie
W ubiegły wtorek, Mistral AI ogłosiło wprowadzenie Voxtral, swojej pierwszej rodziny modeli audio open source. Zaprojektowane do zastosowań profesjonalnych, te modele rozumienia mowy oznaczają wejście francuskiego jednorożca na strategiczny segment inteligencji głosowej, dotychczas zdominowany przez takie podmioty jak OpenAI, Meta i Google.
Seria Voxtral obejmuje dwa główne modele: Voxtral Small (24 miliardy parametrów) i Voxtral Mini (3 miliardy parametrów), każdy przeznaczony do różnych środowisk. Model Small koncentruje się na złożonych przypadkach użycia i wdrożeniach w chmurze na dużą skalę, podczas gdy wersja Mini jest przeznaczona do wdrożeń wbudowanych lub o ograniczonych zasobach. Mistral AI oferuje również Voxtral Mini Transcribe, wersję zoptymalizowaną wyłącznie do transkrypcji głosowej, z lepszym stosunkiem jakości do ceny niż modele takie jak Whisper.
Funkcje wykraczające poza transkrypcję
Voxtral ma być alternatywą dla zawodnych systemów ASR (automatycznego rozpoznawania mowy) oraz kosztownych, zamkniętych i własnościowych API.
Zaprojektowany do obsługi długich kontekstów audio, może obsługiwać do 30 minut transkrypcji lub 40 minut rozumienia, dzięki oknu obejmującemu 32 000 tokenów.
Opierając się na architekturze modelu językowego Mistral Small 3.1, potrafi odpowiadać na zapytania ustne, generować streszczenia na podstawie plików audio lub przekształcać wyrażoną ustnie intencję w wywołanie API lub strumień backendowy. Model obsługuje najczęściej używane języki, w tym angielski, hiszpański, arabski, francuski, portugalski, hindi, niemiecki, niderlandzki i włoski.
Doskonałe wyniki
Zgodnie z pierwszymi ocenami przekazanymi przez Mistral, Voxtral Small przewyższa model referencyjny Whisper v3, a także Gemini 2.5 Flash i GPT-4o Mini Transcribe Open AI w kilku metrykach automatycznej transkrypcji, zachowując jednocześnie kontrolowane zużycie zasobów.
W FLEURS (poniżej), Voxtral Small wykazuje doskonałe wyniki we wszystkich testowanych językach, z precyzją wyższą niż Whisper.
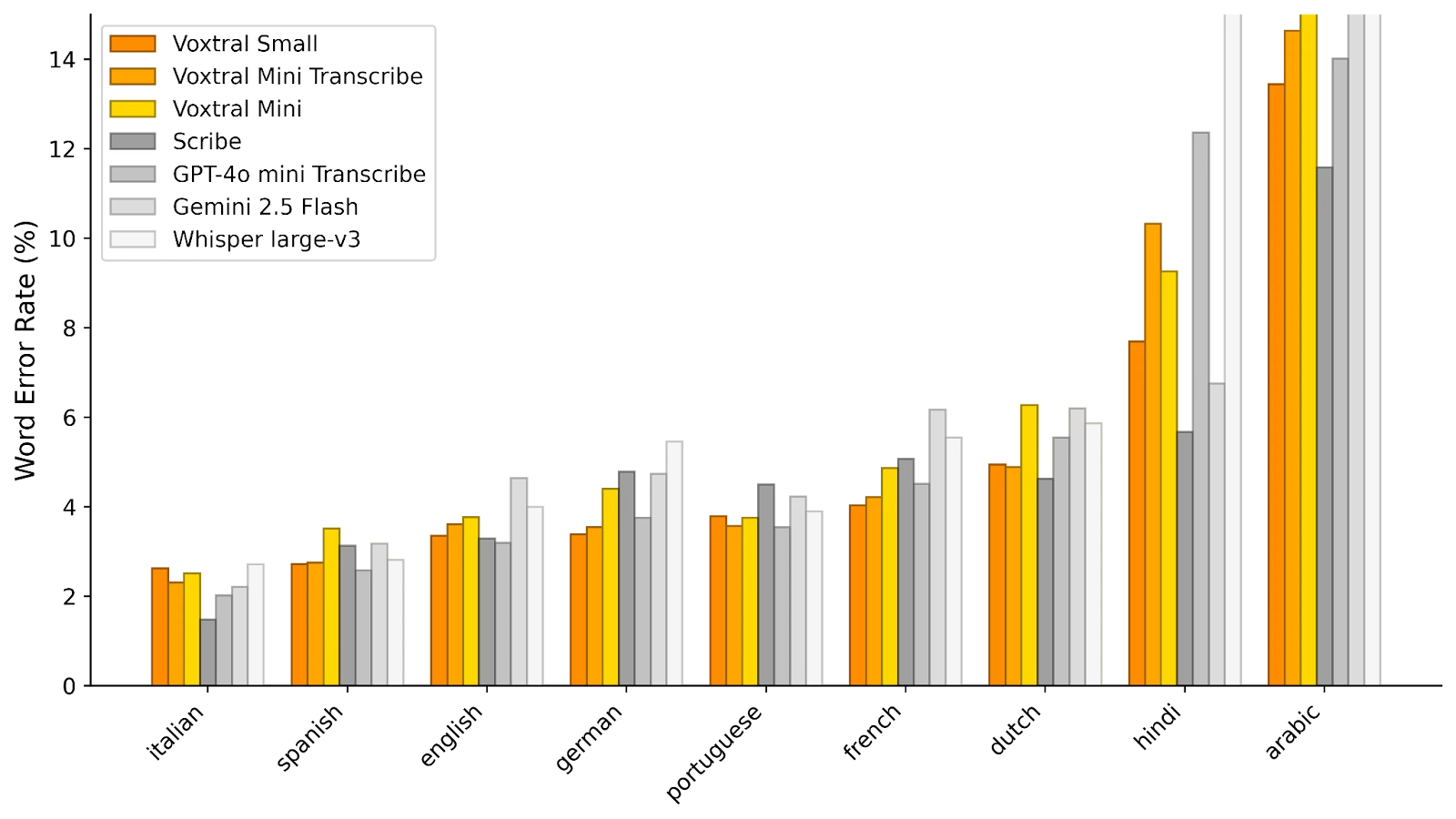
© Mistral AI
W zadaniach tłumaczenia głosowego, Voxtral Small konkuruje z GPT-4o Mini i Gemini.
Dostępność
Oba modele, dystrybuowane na licencji Apache 2.0, są dostępne do pobrania na Hugging Face. Voxtral jest również dostępny przez API od 0,001 $/minutę dla tych, którzy chcą go zintegrować ze swoją aplikacją, co stanowi mniej niż połowę kosztów ofert konkurencyjnych, i wkrótce wzbogaci konwersacyjnego asystenta Mistral AI, Le Chat.
Dla konkretnych kontekstów biznesowych, firmy mogą wybrać prywatne i bezpieczne wdrożenia, w szczególności w dziedzinach prawnych lub medycznych.
Mistral AI planuje w nadchodzących miesiącach wprowadzenie nowych funkcji, takich jak segmentacja audio, diarizacja (identyfikacja różnych mówców) czy wykrywanie emocji.
Dynamiczny rozwój rynku
To wprowadzenie następuje w momencie, gdy rozwiązania do transkrypcji i analizy audio są bardzo poszukiwane, z przyspieszeniem przypadków użycia w obsłudze klienta, analizie interakcji, automatycznej dokumentacji czy asystencji głosowej. Voxtral wchodzi w przestrzeń już zajmowaną przez takie inicjatywy jak Whisper (OpenAI, MIT), SeamlessM4T (Meta, niekomercyjny), czy frameworki jak NVIDIA NeMo lub ESPnet.
Jednak niewiele z nich oferuje obecnie otwarty dostęp, zintegrowane rozumienie semantyczne i zdolność do wywoływania działań za pomocą głosu, w jednym rozwiązaniu.
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale