W skrócie : Naukowcy z Google opracowali MLE-STAR, agenta uczenia maszynowego, który poprawia proces tworzenia modeli AI poprzez połączenie ukierunkowanego wyszukiwania w sieci, doskonalenia kodu i adaptacyjnego montażu. MLE-STAR wykazał swoją skuteczność, wygrywając 63% konkursów w benchmarku MLE-Bench-Lite opartym na Kaggle, znacznie przewyższając wcześniejsze podejścia.
Podsumowanie
Agenci MLE (Machine Learning Engineering agent), oparci na dużych modelach językowych (LLMs), otworzyli nowe perspektywy w rozwoju modeli uczenia maszynowego poprzez automatyzację całego lub części procesu. Jednak istniejące rozwiązania często napotykają na ograniczenia eksploracji lub brak metodologicznej różnorodności. Naukowcy z Google stawiają czoła tym wyzwaniom dzięki MLE-STAR, agentowi, który łączy ukierunkowane wyszukiwanie w sieci, granularne doskonalenie bloków kodu i adaptacyjną strategię montażu.
Konkretnie, agent MLE rozpoczyna od opisu zadania (na przykład, "przewidywanie sprzedaży na podstawie danych tabelarycznych") oraz dostarczonych zbiorów danych, a następnie:
- Analizuje problem i wybiera odpowiednie podejście;
- Generuje kod (często w Pythonie, z użyciem powszechnych lub specjalistycznych bibliotek ML);
- Testuje, ocenia i udoskonala rozwiązanie, czasami w wielu iteracjach.
Ci agenci opierają się na dwóch kluczowych umiejętnościach LLM:
- Rozumowanie algorytmiczne (identyfikacja odpowiednich metod dla danego problemu);
- Generowanie wykonalnego kodu (kompletne skrypty przygotowania danych, treningu i ewaluacji).
Ich celem jest zmniejszenie obciążenia pracą ludzką poprzez automatyzację uciążliwych etapów, takich jak inżynieria cech, dostrajanie hiperparametrów czy wybór modeli.
MLE-STAR: ukierunkowana i iteracyjna optymalizacja
Według Google Research, istniejące MLE napotykają na dwa główne przeszkody. Po pierwsze, ich silne uzależnienie od wewnętrznej wiedzy LLM prowadzi je do preferowania ogólnych i dobrze ugruntowanych metod, takich jak biblioteka scikit-learn dla danych tabelarycznych, kosztem bardziej specjalistycznych i potencjalnie bardziej wydajnych podejść.
Po drugie, ich strategia eksploracji często opiera się na całkowitym przepisaniu kodu przy każdej iteracji. Taki sposób działania uniemożliwia im skoncentrowanie wysiłków na określonych komponentach pipeline'u, na przykład systematycznym testowaniu różnych opcji inżynierii cech, zanim przejdą do kolejnych etapów.
Po drugie, ich strategia eksploracji często opiera się na całkowitym przepisaniu kodu przy każdej iteracji. Taki sposób działania uniemożliwia im skoncentrowanie wysiłków na określonych komponentach pipeline'u, na przykład systematycznym testowaniu różnych opcji inżynierii cech, zanim przejdą do kolejnych etapów.
Aby pokonać te ograniczenia, naukowcy z Google stworzyli MLE-STAR, agenta, który łączy trzy dźwignie:
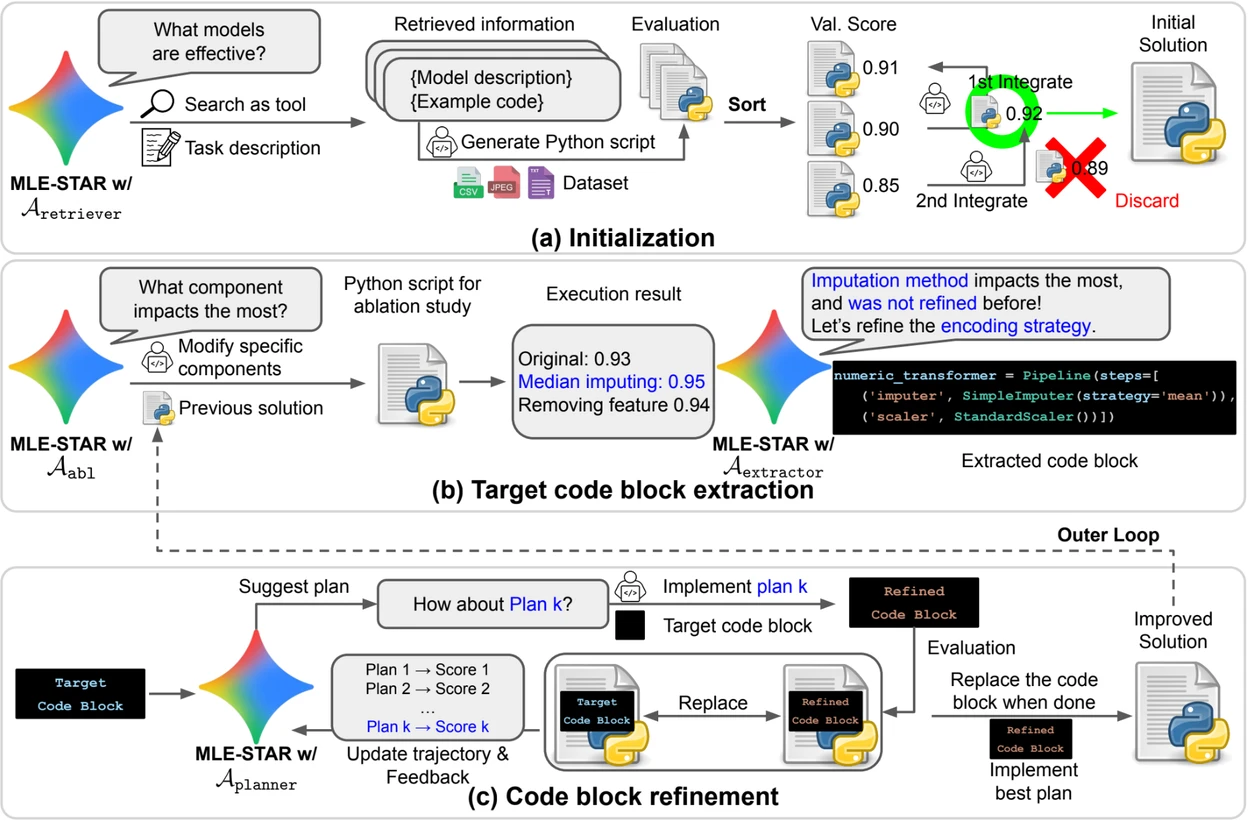
- Wyszukiwanie w sieci w celu zidentyfikowania modeli specyficznych dla zadania i stworzenia solidnego rozwiązania początkowego;
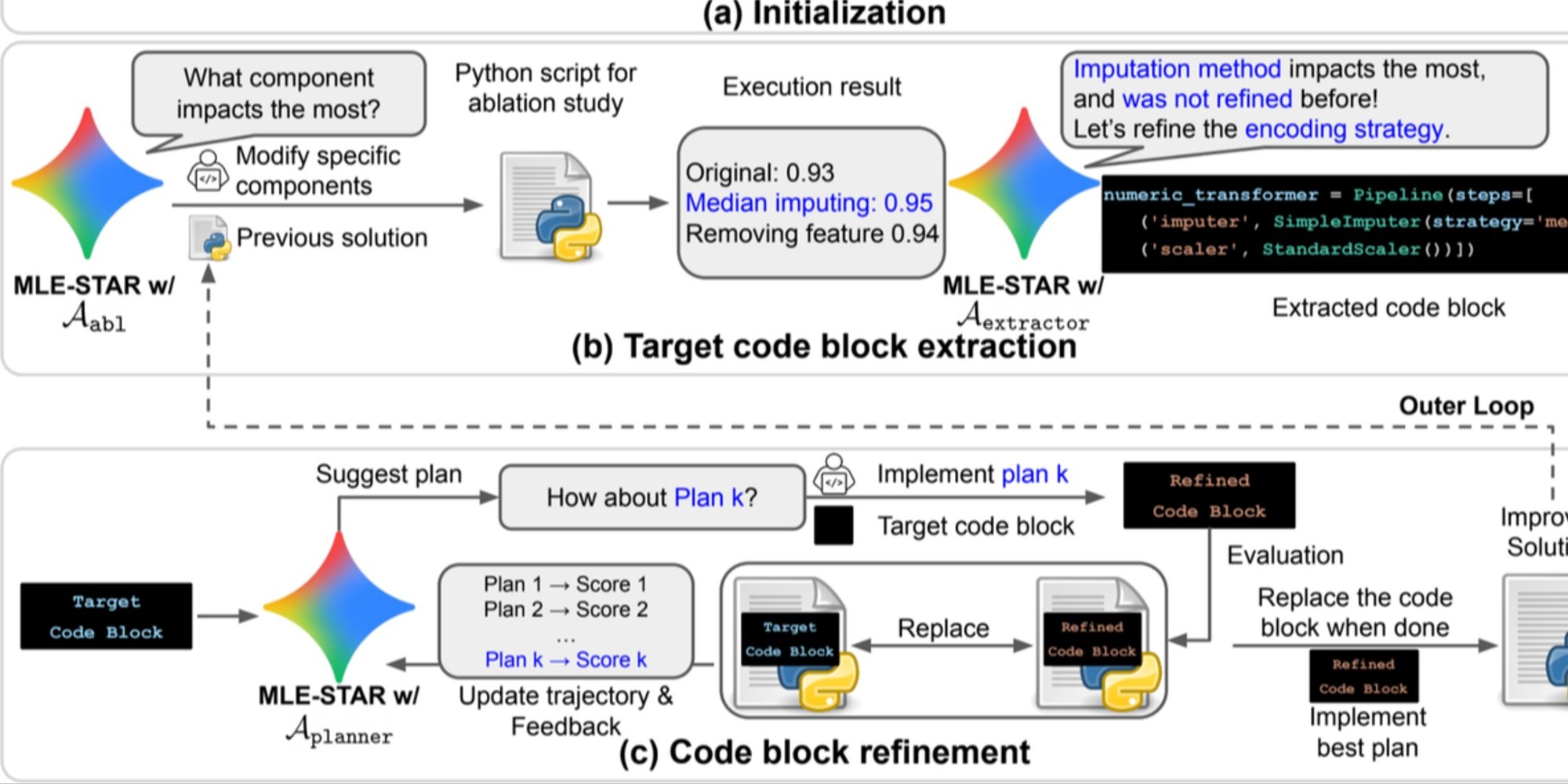
- Granularne doskonalenie przez bloki kodu, opierając się na badaniach ablation w celu zidentyfikowania części mających największy wpływ na wydajność, a następnie ich iteracyjne optymalizowanie;
- Adaptacyjna strategia montażu, zdolna do łączenia wielu kandydatów na rozwiązania w jedną ulepszoną wersję, doskonaloną z każdą próbą.
Ten iteracyjny proces, wyszukiwanie, identyfikacja krytycznego bloku, optymalizacja, a następnie nowa iteracja, pozwala MLE-STAR skoncentrować wysiłki tam, gdzie przynoszą one największe mierzalne korzyści.
Źródło: Google Research.
Podgląd. a) MLE-STAR rozpoczyna od wykorzystania wyszukiwania w sieci w celu znalezienia i włączenia modeli specyficznych dla zadania do rozwiązania początkowego. (b) Dla każdego etapu doskonalenia przeprowadza badanie ablation w celu określenia bloku kodu mającego najistotniejszy wpływ na wydajność. (c) Zidentyfikowany blok kodu poddawany jest następnie iteracyjnemu doskonaleniu na podstawie planów sugerowanych przez LLM, które badają różne strategie z wykorzystaniem komentarzy z poprzednich doświadczeń. Ten proces wyboru i doskonalenia docelowych bloków kodu powtarza się, gdzie ulepszone rozwiązanie z (c) staje się punktem wyjścia dla następnego etapu doskonalenia (b).
Moduły kontrolne dla zwiększenia niezawodności rozwiązań
Poza swoim iteracyjnym podejściem, MLE-STAR integruje trzy moduły mające na celu zwiększenie odporności generowanych rozwiązań:
- Agent debugowania do analizy błędów wykonania (na przykład, traceback Python) i proponowania automatycznych poprawek;
- Weryfikator wycieków danych do wykrywania sytuacji, w których informacje z danych testowych są używane błędnie podczas treningu, co fałszuje mierzone wydajności;
- Weryfikator wykorzystania danych do zapewnienia, że wszystkie dostarczone źródła danych są wykorzystywane, nawet jeśli nie są prezentowane w standardowych formatach, takich jak CSV.
Te moduły odpowiadają na powszechne problemy obserwowane w kodzie generowanym przez LLMs.
Znamienne wyniki na Kaggle
Aby ocenić skuteczność MLE-STAR, naukowcy przetestowali go w ramach benchmarku MLE-Bench-Lite, opartego na konkursach Kaggle. Protokół mierzył zdolność agenta do stworzenia, na podstawie prostego opisu zadania, kompletnego i konkurencyjnego rozwiązania.
Wyniki pokazują, że MLE-STAR zdobywa medal w 63% zawodów, z czego 36% to złote medale, w porównaniu do 25,8% do 36,6% dla najlepszych wcześniejszych podejść. Ten zysk przypisuje się kombinacji kilku czynników: szybkiemu przyjęciu nowych modeli, takich jak EfficientNet lub ViT, zdolności do integracji modeli nie zidentyfikowanych przez wyszukiwanie w sieci dzięki okazjonalnej interwencji człowieka oraz automatycznym poprawkom wprowadzanym przez weryfikatory wycieków i wykorzystania danych.
Przeczytaj artykuł naukowy na arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
Kod open source jest dostępny na GitHub