
W skrócie : Chińska start-up DeepSeek zaktualizowała model R1, poprawiając jego osiągi w rozumowaniu, logice, matematyce i programowaniu. Aktualizacja zmniejsza błędy i poprawia integrację aplikacyjną, umożliwiając R1 konkurowanie z modelami takimi jak o3 od Open AI i Gemini 2.5 Pro od Google.
Podsumowanie
Podczas gdy spekulacje dotyczące kolejnego uruchomienia DeepSeek R2 rosły, to ostatecznie aktualizacja modelu R1 została ogłoszona przez chińską start-up o tej samej nazwie 28 maja. Nazwana DeepSeek-R1-0528, ta wersja wzmacnia zdolności R1 w kluczowych obszarach, takich jak rozumowanie, logika, matematyka i programowanie. Obecnie, osiągi tego modelu open source opublikowanego na licencji MIT zbliżają się do osiągnięć flagowych modeli o3 od Open AI i Gemini 2.5 Pro od Google.
Znaczące ulepszenia w zarządzaniu złożonymi zadaniami rozumowania
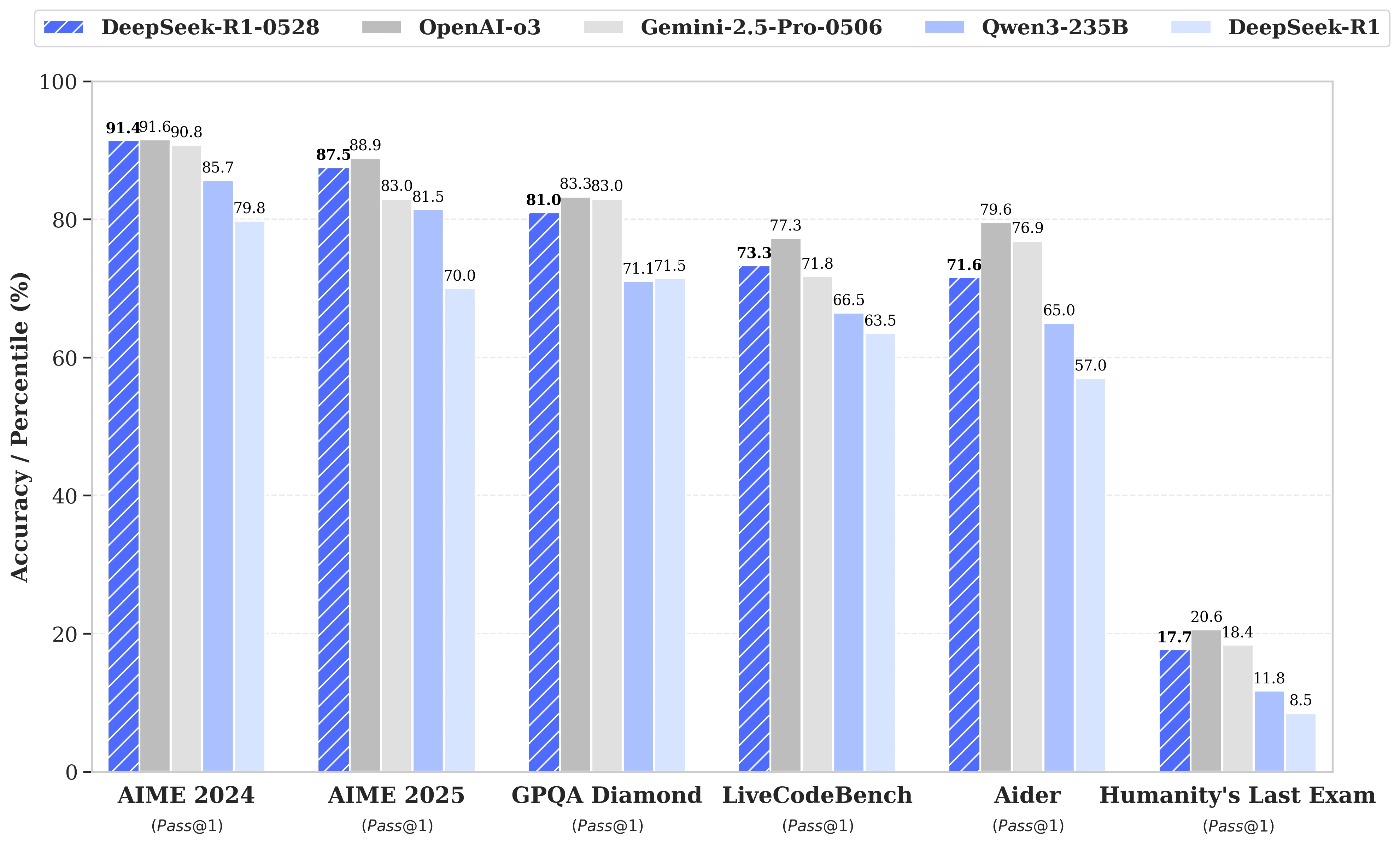
Aktualizacja opiera się na bardziej efektywnym wykorzystaniu dostępnych zasobów obliczeniowych, w połączeniu z serią optymalizacji algorytmicznych wdrożonych po szkoleniu. Te poprawki skutkują zwiększoną głębokością refleksji podczas rozumowania: podczas gdy poprzednia wersja zużywała średnio 12 000 tokenów na pytanie w testach AIME, DeepSeek-R1-0528 zużywa obecnie prawie 23 000, co przekłada się na znaczną poprawę precyzji, z 70% do 87,5% w edycji testu z 2025 roku.
- W matematyce uzyskane wyniki sięgają 91,4% (AIME 2024) i 79,4% (HMMT 2025), ocierając się o osiągi lub przekraczając niektóre modele zamknięte, takie jak o3 czy Gemini 2.5 Pro;
- W programowaniu wskaźnik LiveCodeBench wzrasta o prawie 10 punktów (z 63,5 do 73,3%), a ocena SWE Verified wzrasta z 49,2% do 57,6% sukcesów;
- W ogólnym rozumowaniu test GPQA-Diamant pokazuje wzrost wyniku modelu z 71,5% do 81,0%, podczas gdy dla benchmarku "Ostatni egzamin ludzkości" wynik się podwoił, wzrastając z 8,5% do 17,7%.
Redukcja błędów i lepsza integracja aplikacyjna
Wśród godnych uwagi zmian wprowadzonych przez tę aktualizację znajduje się znacząca redukcja wskaźnika halucynacji, co jest kluczowym problemem dla niezawodności LLM. Zmniejszając częstotliwość faktualnie niepoprawnych odpowiedzi, DeepSeek-R1-0528 zyskuje na solidności, zwłaszcza w kontekstach, gdzie precyzja jest niezbędna.
Aktualizacja wprowadza również funkcje zorientowane na użycie w środowisku strukturalnym, w tym bezpośrednie generowanie wyjść w formacie JSON oraz rozszerzone wsparcie dla wywoływania funkcji. Te postępy techniczne upraszczają integrację modelu w zautomatyzowanych przepływach pracy, agentach programowych lub systemach zaplecza, bez konieczności ciężkich przetwarzań pośrednich.
Coraz większa uwaga na destylację
Równolegle, zespół DeepSeek rozpoczął podejście destylacji łańcuchów myślenia do lżejszych modeli, dla deweloperów lub badaczy z ograniczonym sprzętem. DeepSeek-R1-0528, który liczy 685 miliardów parametrów, został użyty do dalszego szkolenia Qwen3 8B Base.
Model, który z tego wynikł, DeepSeek-R1-0528-Qwen3-8B, osiąga wyniki równające się znacznie większym modelom open source na niektórych benchmarkach. Z wynikiem 86,0% na AIME 2024, przewyższa on wynik Qwen3 8B o ponad 10,0% i dorównuje osiągnięciom Qwen3-235B-thinking.
Podejście to rodzi pytania dotyczące przyszłej żywotności masywnych modeli, w obliczu bardziej oszczędnych, ale lepiej wyszkolonych w rozumowaniu wersji.
DeepSeek stwierdza:
"Uważamy, że łańcuch myślenia DeepSeek-R1-0528 będzie miał znaczące znaczenie zarówno dla badań akademickich nad modelami rozumowania, jak i dla rozwoju przemysłowego skoncentrowanego na modelach małej skali".