Alibaba ogłosiła 21 lipca na X wydanie najnowszej aktualizacji swojego LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. Model open source, dystrybuowany na licencji Apache 2.0, posiada 235 miliardów parametrów i stanowi poważnego konkurenta dla DeepSeek‑V3, Claude Opus 4 od Anthropic, GPT-4o od OpenAI czy Kimi 2, niedawno wprowadzonego przez chiński start-up Moonshot, czterokrotnie większy.
Alibaba Cloud precyzuje w swoim poście:
"Po dyskusjach z społecznością i przemyśleniu tej kwestii, zdecydowaliśmy się zrezygnować z trybu myślenia hybrydowego. Będziemy teraz szkolić modele Instruct i Thinking osobno, aby uzyskać jak najlepszą jakość".
Qwen3-235B-A22B-Instruct-2507 jest modelem nie-myślącym (non-thinking), co oznacza, że nie wykonuje złożonego rozumowania łańcuchowego, ale preferuje szybkość i trafność w wykonywaniu instrukcji.
Dzięki tej strategicznej orientacji, Qwen 3 nie tylko postępuje w śledzeniu instrukcji, ale również wykazuje postępy w rozumowaniu logicznym, głębokim zrozumieniu wyspecjalizowanych dziedzin, przetwarzaniu rzadkich języków, a także matematyce, naukach ścisłych, programowaniu i interakcji z narzędziami cyfrowymi.
W zadaniach otwartych, obejmujących osąd, ton lub twórczość, lepiej dostosowuje się do oczekiwań użytkownika, oferując bardziej użyteczne odpowiedzi i bardziej naturalny styl generacji.
Jego kontekstowe okno, zwiększone do 256 000 tokenów, zostało pomnożone przez osiem, co pozwala mu teraz przetwarzać obszerniejsze dokumenty.
Architektura ukierunkowana na elastyczność i wydajność
Model opiera się na architekturze Mixture-of-Experts (MoE) z 128 specjalistycznymi ekspertami, z których 8 jest wybieranych w zależności od zapotrzebowania: spośród 235 miliardów parametrów, tylko 22 miliardy są aktywowane na żądanie.
Opiera się na 94 warstwach głębokości, zoptymalizowanym schemacie GQA (Grouped Query Attention): 64 głowy dla zapytań (Q) i 4 dla kluczy/wartości.
Wydajność Qwen3‑235B‑A22B‑Instruct‑2507
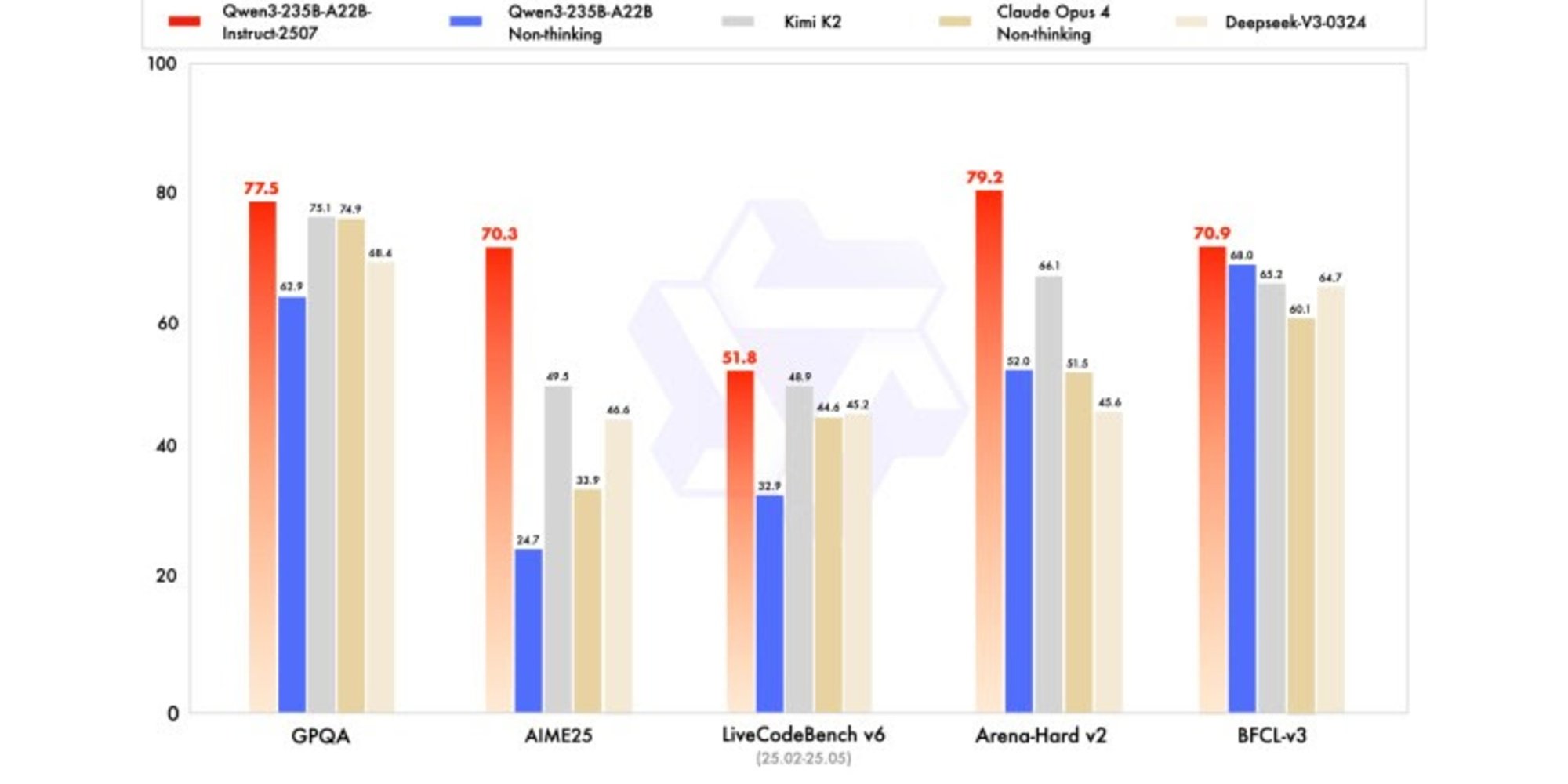
Nowa wersja wykazuje wyniki konkurencyjne, a nawet lepsze, w porównaniu z modelami liderów konkurencji, zwłaszcza w matematyce, kodowaniu i rozumowaniu logicznym.
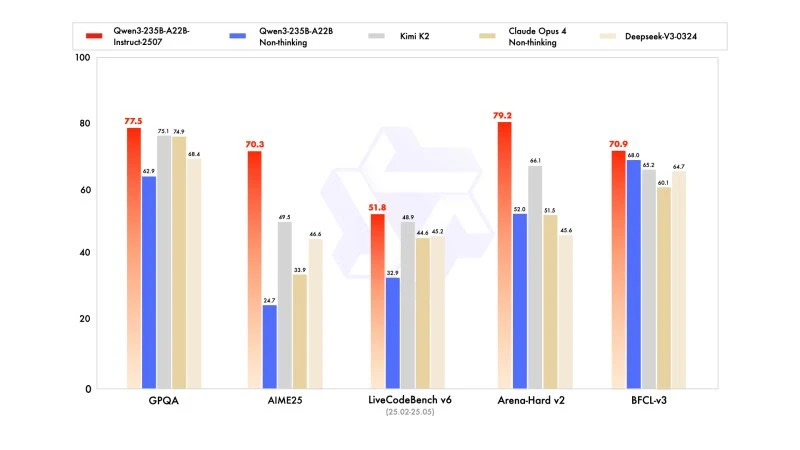
W wiedzy ogólnej uzyskał wynik 83,0 na MMLU-Pro (w porównaniu do 75,2 dla poprzedniej wersji) i 93,1 na MMLU-Redux, zbliżając się do poziomu Claude Opus 4 (94,2).
W zaawansowanym rozumowaniu osiągnął bardzo wysoki wynik w modelowaniu matematycznym: 70,3 na AIME (American Invitational Mathematics Examination) 2025, przewyższając wyniki 46,6 DeepSeek-V3-0324 i 26,7 GPT-4o-0327 od OpenAI.
W kodowaniu jego wynik 87,9 na MultiPL‑E plasuje go za Claude (88,5), ale przed GPT-4o i DeepSeek. Na LiveCodeBench v6 osiąga 51,8, co jest najlepszym wynikiem zmierzonym w tym benchmarku.
Wersja kwantowana w FP8: optymalizacja bez kompromisów
Równocześnie z Qwen3-235B-A22B-Instruct-2507, Alibaba opublikowała swoją wersję kwantowaną w FP8. Ten skompresowany format numeryczny drastycznie zmniejsza potrzeby pamięciowe i przyspiesza wnioskowanie, co pozwala modelowi działać w środowiskach o ograniczonych zasobach, i to bez znaczącej utraty wydajności.