In kort : Onderzoekers van Google hebben MLE-STAR ontwikkeld, een machine learning agent die het proces van AI-modelcreatie verbetert door gerichte webzoekopdrachten, codeverfijning en adaptieve assemblage te combineren. MLE-STAR heeft zijn effectiviteit aangetoond door 63% van de competities in de MLE-Bench-Lite benchmark gebaseerd op Kaggle te winnen, en overtreft eerdere benaderingen aanzienlijk.
Samenvatting
De MLE-agenten (Machine Learning Engineering agent), gebaseerd op grote taalmodellen (LLMs), hebben nieuwe mogelijkheden geopend in de ontwikkeling van machine learning-modellen door het proces geheel of gedeeltelijk te automatiseren. Bestaande oplossingen stuiten echter vaak op beperkingen in verkenning of een gebrek aan methodologische diversiteit. De onderzoekers van Google pakken deze uitdagingen aan met MLE-STAR, een agent die gerichte webzoekopdrachten, fijnmazige verfijning van codeblokken en een adaptieve assemblagestrategie combineert.
Concreet begint een MLE-agent met een taakomschrijving (bijvoorbeeld "voorspel de verkoop op basis van tabelgegevens") en verstrekte datasets, en dan:
- Analyseert het probleem en kiest een geschikte aanpak;
- Genereert code (vaak in Python, met veelgebruikte of gespecialiseerde ML-bibliotheken);
- Test, evalueert en verfijnt de oplossing, soms in meerdere iteraties.
Deze agenten vertrouwen op twee kerncompetenties van LLMs:
- Algorithmisch redeneren (het identificeren van relevante methoden voor een gegeven probleem);
- Het genereren van uitvoerbare code (volledige scripts voor data-preparatie, training en evaluatie).
Hun doel is om de menselijke werklast te verminderen door tijdrovende stappen zoals feature engineering, hyperparameter tuning of modelselectie te automatiseren.
MLE-STAR: een gerichte en iteratieve optimalisatie
Volgens Google Research stuiten de bestaande MLE's op twee belangrijke obstakels. Ten eerste, hun sterke afhankelijkheid van de interne kennis van LLMs leidt ertoe dat ze generieke en gevestigde methoden zoals de scikit-learn bibliotheek voor tabulaire gegevens verkiezen boven meer gespecialiseerde en potentieel performantere benaderingen.
Ten tweede is hun verkenningsstrategie vaak gebaseerd op een volledige herschrijving van de code bij elke iteratie. Dit verhindert hen om hun inspanningen te concentreren op specifieke componenten van de pipeline, bijvoorbeeld door systematisch verschillende opties voor feature engineering te testen voordat ze naar andere stappen gaan.
Ten tweede is hun verkenningsstrategie vaak gebaseerd op een volledige herschrijving van de code bij elke iteratie. Dit verhindert hen om hun inspanningen te concentreren op specifieke componenten van de pipeline, bijvoorbeeld door systematisch verschillende opties voor feature engineering te testen voordat ze naar andere stappen gaan.
Om deze beperkingen te overwinnen hebben de onderzoekers van Google MLE-STAR ontworpen, een agent die drie hefbomen combineert:
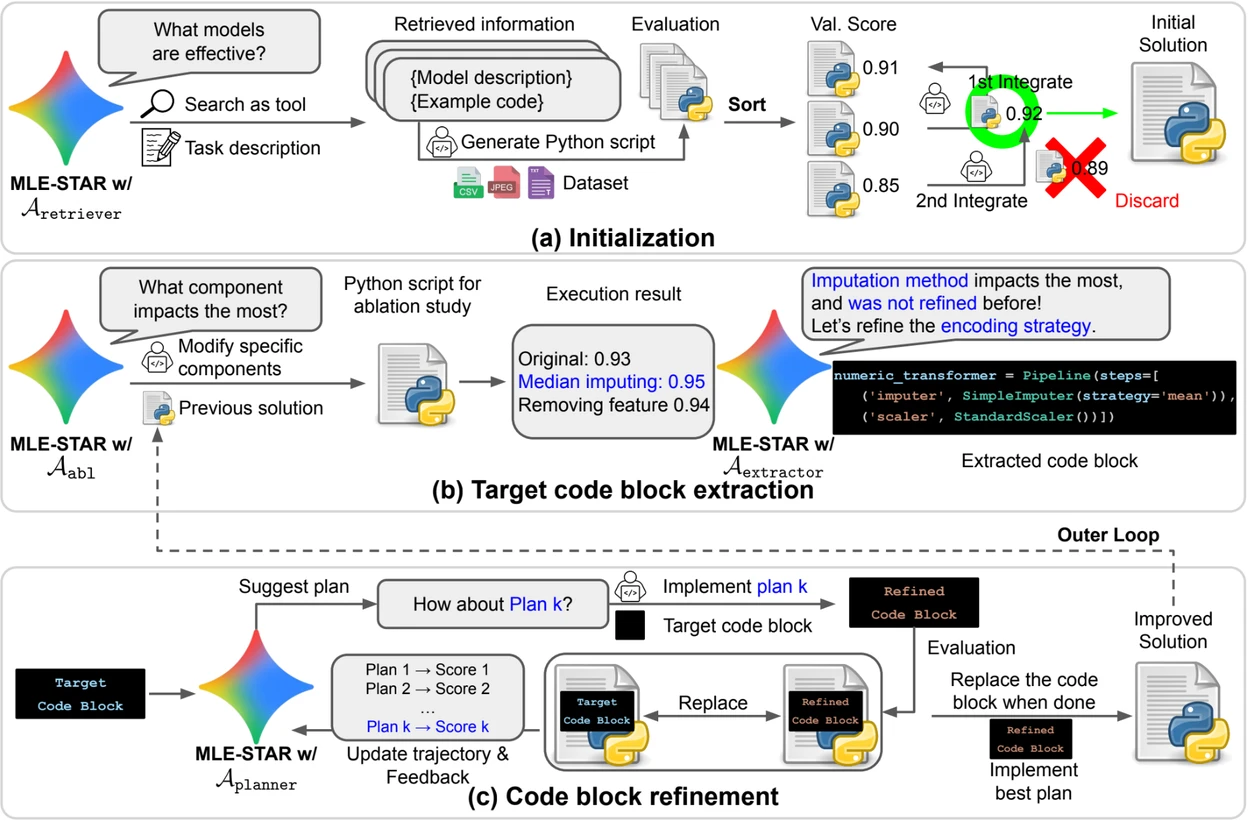
- Webzoekopdrachten om taak specifieke modellen te identificeren en een solide initiële oplossing te vormen;
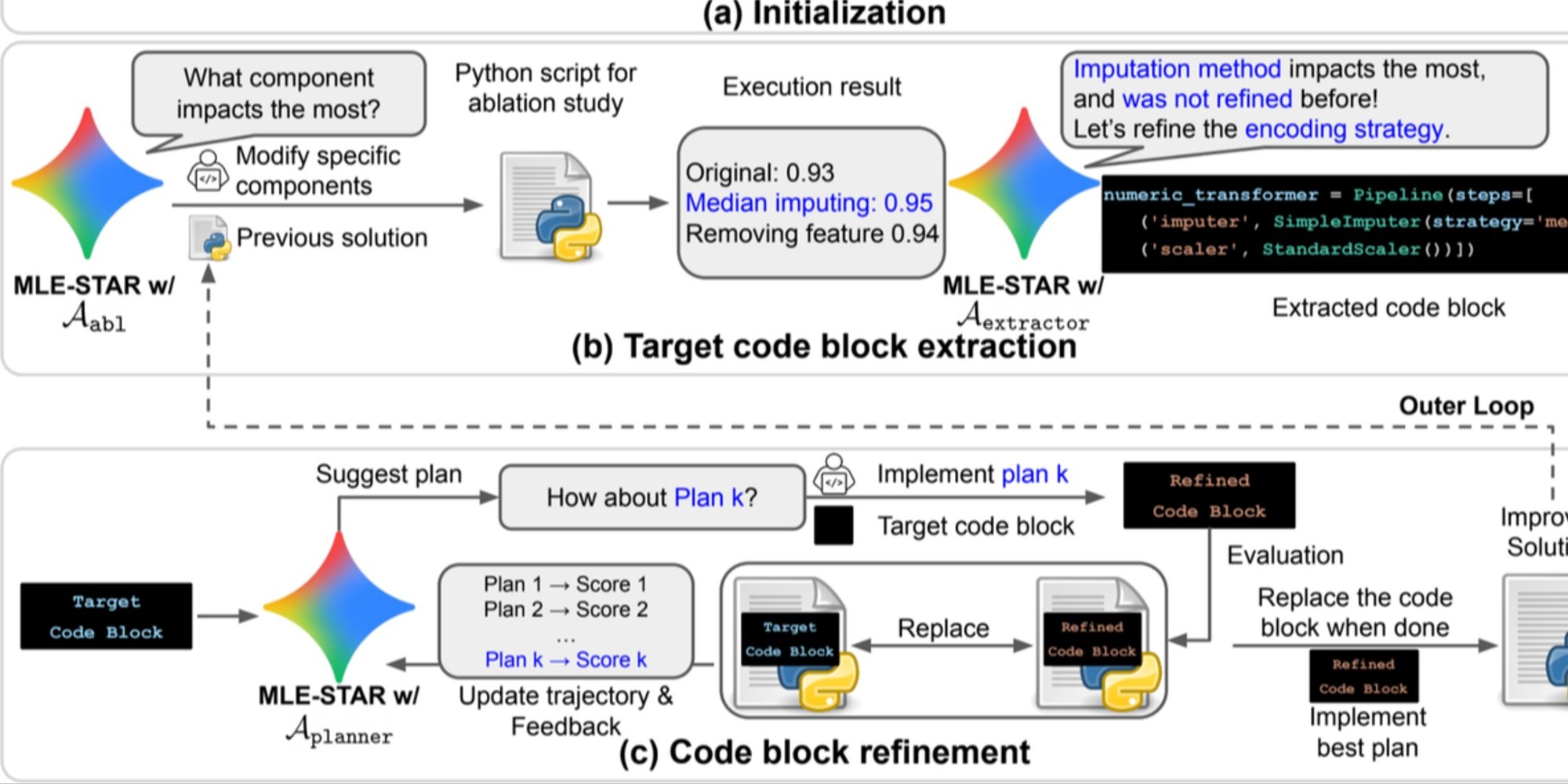
- Fijnmazige verfijning per codeblok, gebaseerd op ablatiestudies om de onderdelen met de grootste impact op prestaties te identificeren en deze iteratief te optimaliseren;
- Een adaptieve assemblagestrategie, die in staat is om meerdere kandidaatoplossingen te fuseren tot een verbeterde versie, verfijnd door opeenvolgende pogingen.
Dit iteratieve proces van zoeken, identificeren van het cruciale blok, optimaliseren, en dan opnieuw itereren, stelt MLE-STAR in staat om zijn inspanningen te concentreren waar ze de meeste meetbare winst opleveren.
Krediet: Google Research.
Overzicht. a) MLE-STAR begint met het gebruik van webzoekopdrachten om taak specifieke modellen te vinden en te integreren in een initiële oplossing. (b) Voor elke verfijningsstap voert het een ablatiestudie uit om het codeblok te bepalen dat de meest significante impact heeft op de prestaties. (c) Het geïdentificeerde codeblok ondergaat vervolgens iteratieve verfijning op basis van de door LLM voorgestelde plannen, die verschillende strategieën verkennen met behulp van feedback van vorige experimenten. Dit proces van selectie en verfijning van doelcodeblokken herhaalt zich, waarbij de verbeterde oplossing van (c) het startpunt wordt voor de volgende verfijningsstap (b).
Controlemodules om oplossingen te versterken
Naast zijn iteratieve aanpak integreert MLE-STAR drie modules om de robuustheid van de gegenereerde oplossingen te versterken:
- Een debugging-agent om uitvoeringsfouten te analyseren (bijvoorbeeld een traceback in Python) en automatische correcties voor te stellen;
- Een datalek-detectiemodule om situaties te detecteren waarin testgegevens onterecht worden gebruikt tijdens de training, een bias die de gemeten prestaties vertekent;
- Een datagebruik-verificatiemodule om ervoor te zorgen dat alle verstrekte gegevensbronnen worden gebruikt, zelfs wanneer ze niet in standaardformaten zoals CSV worden aangeboden.
Deze modules adresseren veelvoorkomende problemen die worden waargenomen in door LLMs gegenereerde code.
Betekenisvolle resultaten op Kaggle
Om de effectiviteit van MLE-STAR te evalueren, testten de onderzoekers het in de MLE-Bench-Lite benchmark, gebaseerd op Kaggle competities. Het protocol mat de capaciteit van een agent om vanuit een eenvoudige taakomschrijving een complete en concurrerende oplossing te produceren.
De resultaten tonen aan dat MLE-STAR in 63% van de competities een medaille behaalt, waaronder 36% goud, in vergelijking met 25,8% tot 36,6% voor de beste eerdere benaderingen. Deze winst wordt toegeschreven aan de combinatie van verschillende factoren: de snelle adoptie van recente modellen zoals EfficientNet of ViT, de mogelijkheid om modellen te integreren die niet door webzoeken zijn geïdentificeerd dankzij een eenmalige menselijke interventie, en de automatische correcties door de lek- en datagebruik-verificators.
Lees het wetenschappelijk artikel op arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
De open source code is beschikbaar op GitHub