
In kort : De Chinese start-up DeepSeek heeft hun R1-model geüpdatet, waardoor de prestaties op het gebied van redenering, logica, wiskunde en programmering zijn verbeterd. Deze update, die fouten vermindert en de applicatie-integratie verbetert, stelt R1 in staat te concurreren met toonaangevende modellen zoals o3 van Open AI en Gemini 2.5 Pro van Google.
Samenvatting
Terwijl er volop werd gespeculeerd over de aanstaande lancering van DeepSeek R2, kondigde de gelijknamige Chinese start-up op 28 mei een update aan van het R1-model. Deze versie, genaamd DeepSeek-R1-0528, versterkt de capaciteiten van R1 op sleutelgebieden zoals redenering, logica, wiskunde en programmering. De prestaties van dit open-source model, gepubliceerd onder de MIT-licentie, komen nu dichter in de buurt van die van toonaangevende modellen zoals o3 van Open AI en Gemini 2.5 Pro van Google.
Significante verbeteringen in het beheer van complexe redeneertaken
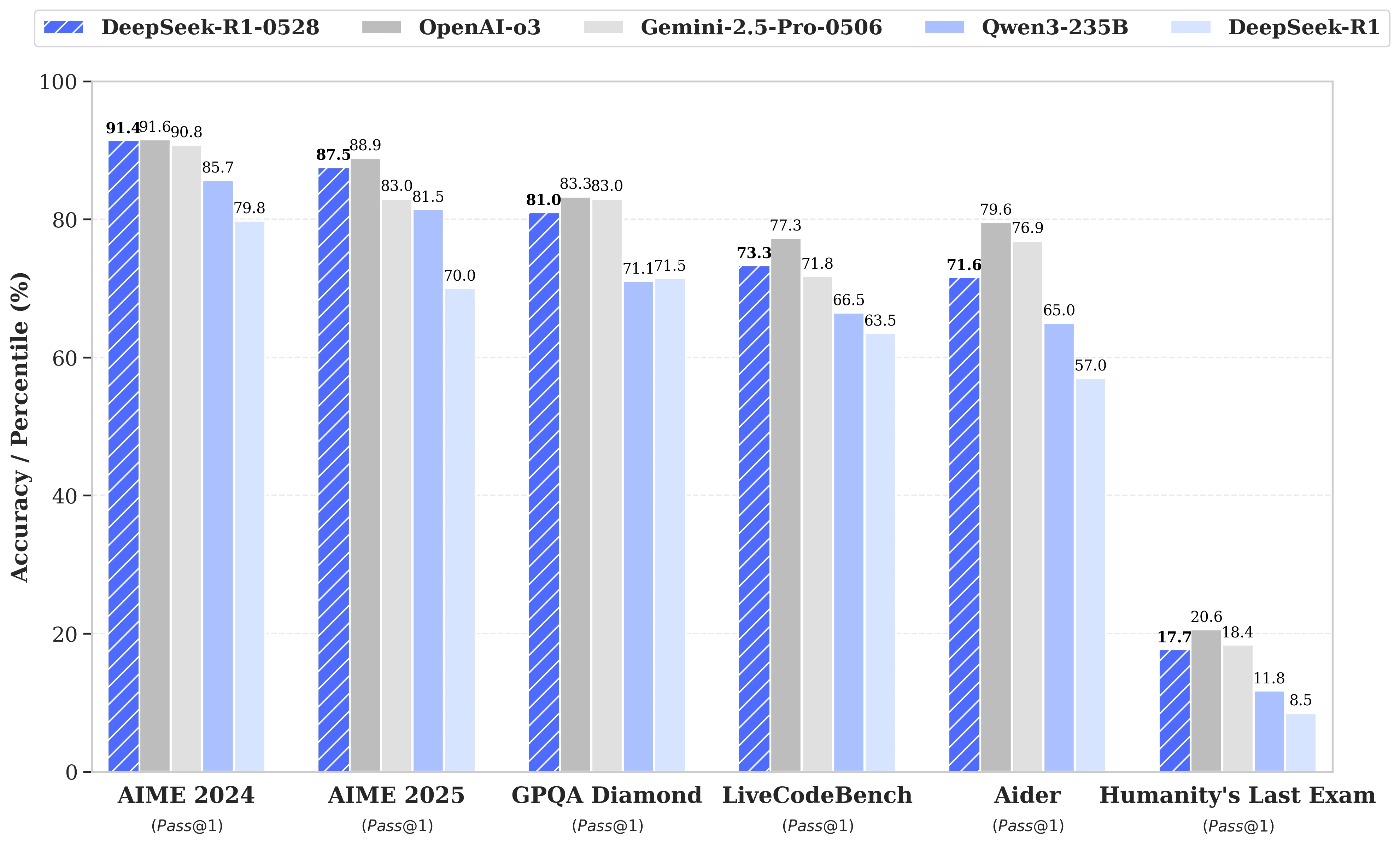
De update maakt gebruik van een efficiëntere benutting van de beschikbare rekenbronnen, gecombineerd met een reeks algoritmische optimalisaties die na de training zijn doorgevoerd. Deze aanpassingen zorgen voor een grotere diepte van nadenken tijdens het redeneren: terwijl de vorige versie gemiddeld 12.000 tokens per vraag verbruikte in de AIME-tests, gebruikt DeepSeek-R1-0528 nu bijna 23.000 tokens, wat heeft geleid tot een opmerkelijke toename in nauwkeurigheid, van 70% naar 87,5% bij de 2025-editie van de test.
- In de wiskunde bereiken de geregistreerde scores 91,4% (AIME 2024) en 79,4% (HMMT 2025), wat de prestaties van sommige gesloten modellen zoals o3 of Gemini 2.5 Pro evenaart of overtreft;
- In de programmering stijgt de LiveCodeBench-index met bijna 10 punten (van 63,5 naar 73,3%), en de SWE Verified-evaluatie stijgt van 49,2% naar 57,6% succes;
- In algemene redenering stijgt de score van het model in de GPQA-Diamant-test van 71,5% naar 81,0%, terwijl het bij de benchmark "Laatste examen van de mensheid" meer dan verdubbelt, van 8,5% naar 17,7%.
Vermindering van fouten en betere applicatie-integratie
Een van de opmerkelijke verbeteringen door deze update is de aanzienlijke vermindering van de hallucinatiegraad, een kritieke kwestie voor de betrouwbaarheid van LLM's. Door de frequentie van feitelijk onjuiste antwoorden te verminderen, wint DeepSeek-R1-0528 aan robuustheid, vooral in contexten waar precisie essentieel is.
De update introduceert ook functies gericht op gebruik in gestructureerde omgevingen, zoals de directe generatie van uitvoer in JSON-formaat en de uitgebreide ondersteuning van functieaanroepen. Deze technische vooruitgangen vereenvoudigen de integratie van het model in geautomatiseerde workflows, software-agents of back-end systemen, zonder dat zware tussenverwerkingen nodig zijn.
Een groeiende focus op distillatie
Tegelijkertijd heeft het team van DeepSeek een benadering van distillatie van denkketens naar lichtere modellen gestart, voor ontwikkelaars of onderzoekers met beperkte hardware. DeepSeek-R1-0528, dat 685 B (miljard) parameters bevat, werd gebruikt om Qwen3 8B Base na te trainen.
Het resulterende model, DeepSeek-R1-0528-Qwen3-8B, slaagt erin om gelijk te presteren met veel grotere open-source modellen op bepaalde benchmarks. Met een score van 86,0% op AIME 2024, overtreft het niet alleen die van Qwen3 8B met meer dan 10,0%, maar evenaart het ook de prestaties van Qwen3-235B-thinking.
Een benadering die vragen oproept over de toekomstige levensvatbaarheid van massieve modellen, tegenover zuinigere versies die beter getraind zijn in redeneren.
DeepSeek stelt:
"We denken dat de denkketen van DeepSeek-R1-0528 een significante rol zal spelen zowel voor academisch onderzoek naar redeneermodellen als voor industriële ontwikkelingen gericht op kleinschalige modellen".