Alibaba kondigde op 21 juli op X de publicatie aan van de laatste update van zijn LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. Het open source model, gedistribueerd onder Apache 2.0-licentie, telt 235 miljard parameters en is een serieuze concurrent voor DeepSeek-V3, Claude Opus 4 van Anthropic, GPT-4o van OpenAI of Kimi 2, onlangs gelanceerd door de Chinese start-up Moonshot, vier keer groter.
Alibaba Cloud vermeldt in zijn bericht:
"Na overleg met de gemeenschap en nadenken over de kwestie, hebben we besloten het hybride denkmode te verlaten. We gaan nu de Instruct en Thinking modellen afzonderlijk trainen om de best mogelijke kwaliteit te bereiken".
Qwen3-235B-A22B-Instruct-2507 is een niet-denkend model, wat betekent dat het geen complexe kettingredenering uitvoert, maar snelheid en relevantie in de uitvoering van instructies vooropstelt.
Dankzij deze strategische richting, maakt Qwen 3 niet alleen vooruitgang in het volgen van instructies, maar toont het ook vooruitgang in logisch redeneren, fijne begrip van gespecialiseerde domeinen, in het verwerken van minder vaak voorkomende talen, evenals in wiskunde, wetenschappen, programmeren en interactie met digitale hulpmiddelen.
Bij open taken, die oordeel, toon of creatie vereisen, past het zich beter aan de verwachtingen van de gebruiker aan, met nuttigere antwoorden en een natuurlijkere stijl van generatie.
Zijn contextuele venster, uitgebreid tot 256.000 tokens, is met acht vermenigvuldigd, waardoor het nu omvangrijke documenten kan verwerken.
Een architectuur gericht op flexibiliteit en efficiëntie
Het model is gebaseerd op een Mixture-of-Experts (MoE) architectuur met 128 gespecialiseerde experts, waarvan er 8 worden geselecteerd op basis van de vraag: van de 235 miljard parameters worden er slechts 22 miljard per verzoek geactiveerd.
Het maakt gebruik van 94 lagen diepte, een geoptimaliseerd GQA (Grouped Query Attention) schema: 64 hoofden voor de query (Q) en 4 voor de sleutels/waarden.
Prestaties van Qwen3‑235B‑A22B‑Instruct‑2507
De nieuwe versie toont competitieve, zelfs superieure resultaten vergeleken met de modellen van toonaangevende concurrenten, vooral in wiskunde, codering en logisch redeneren.
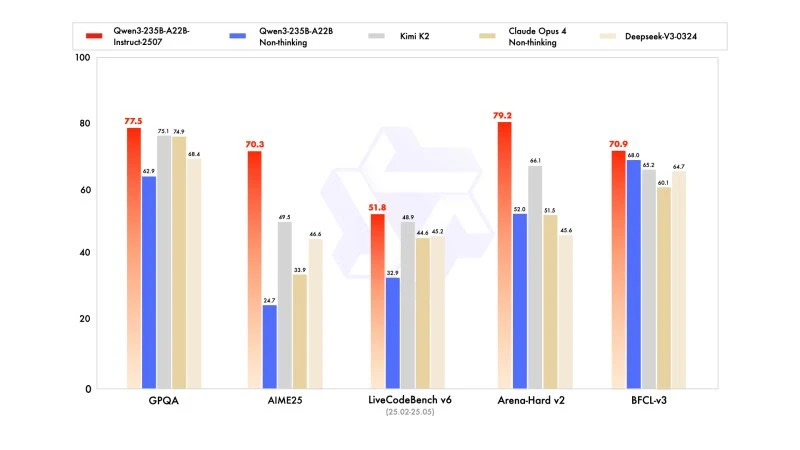
In algemene kennis behaalde het een score van 83,0 op MMLU-Pro (tegenover 75,2 voor de vorige versie) en 93,1 op MMLU-Redux, wat het dichter bij het niveau van Claude Opus 4 (94,2) brengt.
In geavanceerd redeneren behaalde het een zeer hoge score in wiskundige modellering: 70,3 op AIME (American Invitational Mathematics Examination) 2025, wat de scores van 46,6 van DeepSeek-V3-0324 en 26,7 van GPT-4o-0327 van OpenAI overtreft.
In codering, met een score van 87,9 op MultiPL-E, plaatst het zich achter Claude (88,5), maar voor GPT-4o en DeepSeek. Op LiveCodeBench v6 behaalt het 51,8, de beste prestatie gemeten op deze benchmark.
Gekwantificeerde versie in FP8: optimalisatie zonder compromissen
Tegelijk met Qwen3-235B-A22B-Instruct-2507, heeft Alibaba zijn gekwantificeerde versie in FP8 uitgebracht. Dit gecomprimeerde numerieke formaat vermindert drastisch het geheugengebruik en versnelt de inferentie, waardoor het model kan functioneren in omgevingen waar de middelen beperkt zijn, zonder significante prestatieverlies.