
El martes pasado, Mistral AI anunció el lanzamiento de Voxtral, su primera familia de modelos de audio de código abierto. Diseñados para usos profesionales, estos modelos de comprensión del habla marcan la entrada de la unicornio francesa en el segmento estratégico de la inteligencia vocal, un campo hasta ahora dominado por actores como OpenAI, Meta y Google.
La gama Voxtral se presenta en dos modelos principales: Voxtral Small (24 mil millones de parámetros) y Voxtral Mini (3 mil millones de parámetros), cada uno destinado a entornos distintos. El modelo Small se posiciona para casos de uso complejos y despliegue en la nube a gran escala, mientras que la versión Mini apunta a despliegues integrados o con recursos limitados. Mistral AI también ofrece Voxtral Mini Transcribe, una versión optimizada únicamente para la transcripción de voz, con una relación calidad/precio superior a la de modelos como Whisper.
Funciones que van más allá de la transcripción
Voxtral se presenta como una alternativa a los sistemas ASR (reconocimiento automático del habla) poco fiables y a las costosas API cerradas y propietarias.
Diseñado para procesar contextos de audio largos, puede manejar hasta 30 minutos de transcripción o 40 minutos de comprensión, gracias a una ventana de 32,000 tokens.
Basado en la arquitectura del modelo lingüístico Mistral Small 3.1, puede responder a consultas orales, generar resúmenes a partir de archivos de audio o transformar una intención expresada oralmente en una llamada API o flujo backend. El modelo admite los idiomas más utilizados, incluyendo inglés, español, árabe, francés, portugués, hindi, alemán, neerlandés e italiano.
Rendimiento de vanguardia
Según las primeras evaluaciones comunicadas por Mistral, Voxtral Small supera al modelo de referencia Whisper v3, así como a Gemini 2.5 Flash y GPT-4o Mini Transcribe de OpenAI en varias métricas de transcripción automática, mientras mantiene un consumo de recursos controlado.
En FLEURS (abajo), Voxtral Small muestra un rendimiento superior en todos los idiomas probados, con una precisión mayor que Whisper.
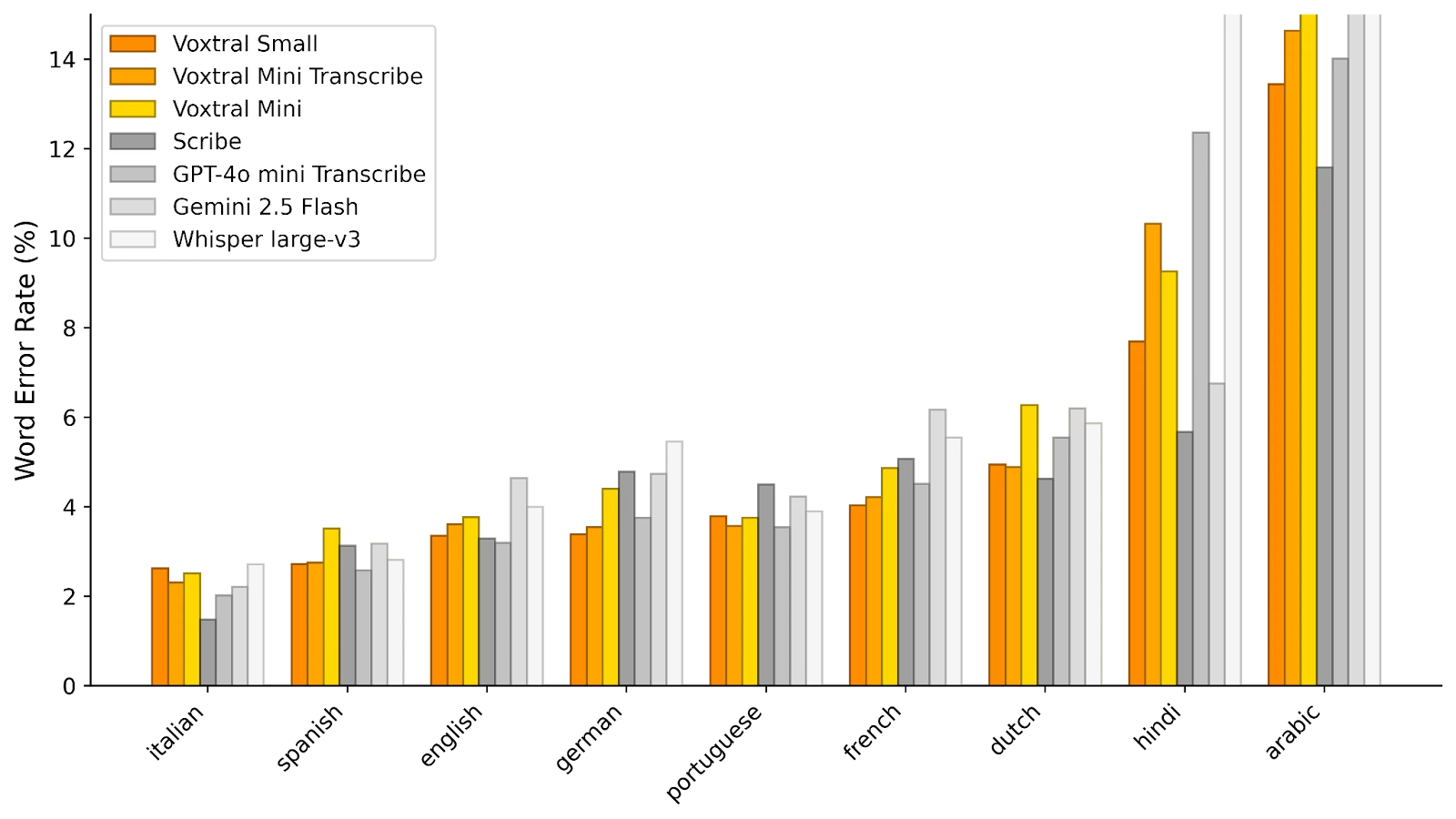
© Mistral AI
En tareas de traducción de voz, Voxtral Small es competitivo con GPT-4o Mini y Gemini.
Disponibilidad
Los dos modelos, distribuidos bajo la licencia Apache 2.0, están disponibles para descarga en Hugging Face. Voxtral también es accesible a través de API desde 0,001 $/minuto para aquellos que deseen integrarlo en su aplicación, lo que es menos de la mitad del costo de las ofertas competidoras, y pronto enriquecerá al asistente conversacional de Mistral AI, Le Chat.
Para contextos empresariales específicos, las empresas pueden optar por despliegues privados y seguros, especialmente en los campos legales o médicos.
Mistral AI planea agregar en los próximos meses nuevas funcionalidades como la segmentación de audio, la diarización (identificación de diferentes hablantes) o la detección de emociones.
Una dinámica de mercado en expansión
Este lanzamiento se produce en un momento en que las soluciones de transcripción y análisis de audio están en alta demanda, con un aumento en los casos de uso en soporte al cliente, análisis de interacciones, documentación automatizada o asistencia de voz. Voxtral se inserta en un espacio ya ocupado por iniciativas como Whisper (OpenAI, MIT), SeamlessM4T (Meta, no comercial), o frameworks como NVIDIA NeMo o ESPnet.
Pero pocos de ellos ofrecen, hasta hoy, acceso gratuito, comprensión semántica integrada y capacidad para desencadenar acciones a partir de la voz, en una única solución.
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale