TLDR : Los investigadores de Google han desarrollado MLE-STAR, un agente de aprendizaje automático que mejora el proceso de creación de modelos de IA combinando búsqueda web dirigida, refinamiento de código y ensamblaje adaptativo. MLE-STAR ha demostrado su efectividad al ganar el 63% de las competiciones en el benchmark MLE-Bench-Lite basado en Kaggle, superando ampliamente los enfoques anteriores.
Índice
Los agentes MLE (Machine Learning Engineering agent), basados en grandes modelos de lenguaje (LLMs), han abierto nuevas perspectivas en el desarrollo de modelos de aprendizaje automático al automatizar parte o todo el proceso. Sin embargo, las soluciones existentes a menudo enfrentan límites de exploración o falta de diversidad metodológica. Los investigadores de Google afrontan estos desafíos con MLE-STAR, un agente que combina búsqueda web dirigida, refinamiento granular de bloques de código y estrategia de ensamblaje adaptativa.
Concretamente, un agente MLE parte de una descripción de tarea (por ejemplo, "predecir ventas a partir de datos tabulares") y conjuntos de datos proporcionados, luego:
- Analiza el problema y elige un enfoque adecuado;
- Genera código (a menudo en Python, con bibliotecas ML comunes o especializadas);
- Prueba, evalúa y refina la solución, a veces en varias iteraciones.
Estos agentes se apoyan en dos habilidades clave de los LLM:
- El razonamiento algorítmico (identificar los métodos relevantes para un problema dado);
- La generación de código ejecutable (scripts completos de preparación de datos, entrenamiento y evaluación).
Su objetivo es reducir la carga de trabajo humano al automatizar pasos tediosos como la ingeniería de características, el ajuste de hiperparámetros o la selección de modelos.
MLE-STAR: una optimización dirigida e iterativa
Según Google Research, los MLE existentes enfrentan dos obstáculos principales. Primero, su fuerte dependencia de los conocimientos internos de los LLMs los lleva a privilegiar métodos genéricos y bien establecidos, como la biblioteca scikit-learn para datos tabulares, en detrimento de enfoques más especializados y potencialmente más efectivos.
En segundo lugar, su estrategia de exploración a menudo se basa en una reescritura completa del código en cada iteración. Este funcionamiento les impide concentrar sus esfuerzos en componentes específicos del pipeline, por ejemplo, probar de manera sistemática diferentes opciones de ingeniería de características, antes de pasar a otros pasos.
En segundo lugar, su estrategia de exploración a menudo se basa en una reescritura completa del código en cada iteración. Este funcionamiento les impide concentrar sus esfuerzos en componentes específicos del pipeline, por ejemplo, probar de manera sistemática diferentes opciones de ingeniería de características, antes de pasar a otros pasos.
Para superar estos límites, los investigadores de Google han diseñado MLE-STAR, un agente que combina tres palancas:
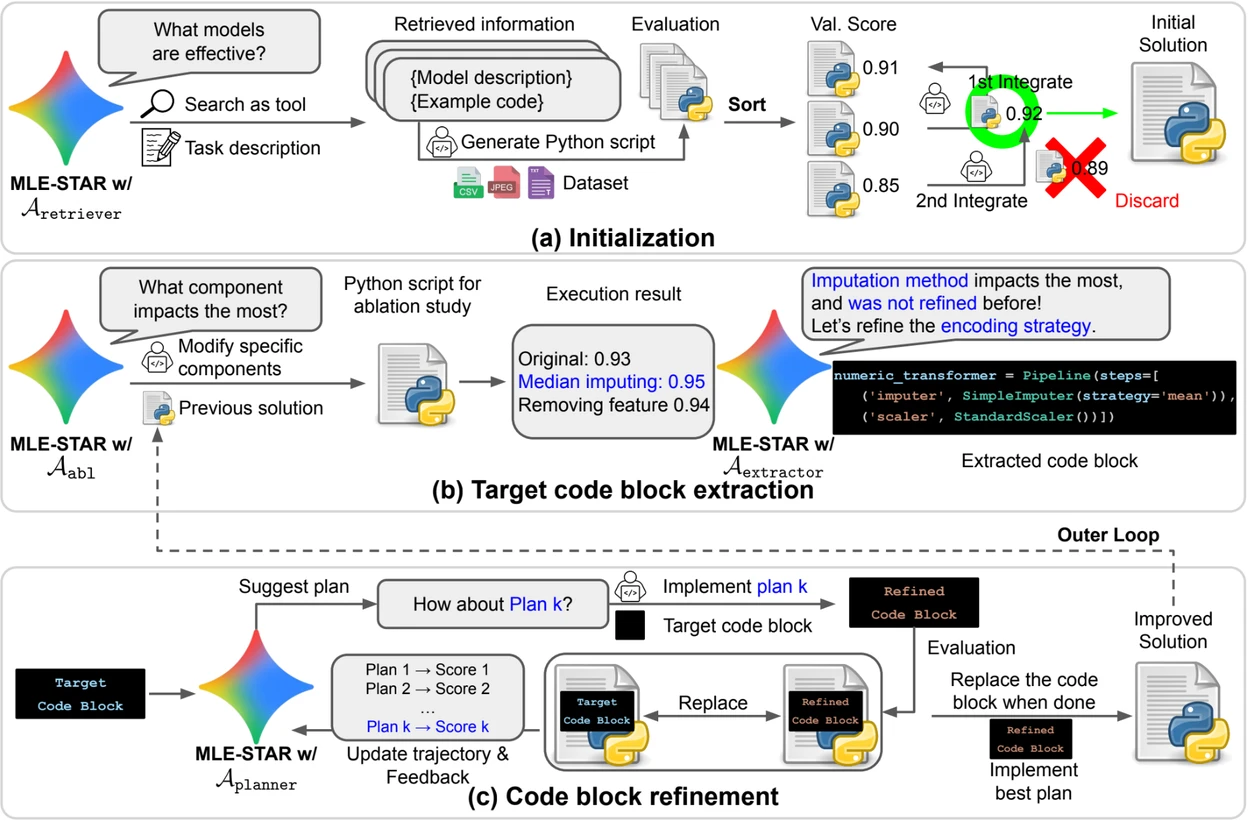
- Búsqueda web para identificar modelos específicos de la tarea y constituir una solución inicial sólida;
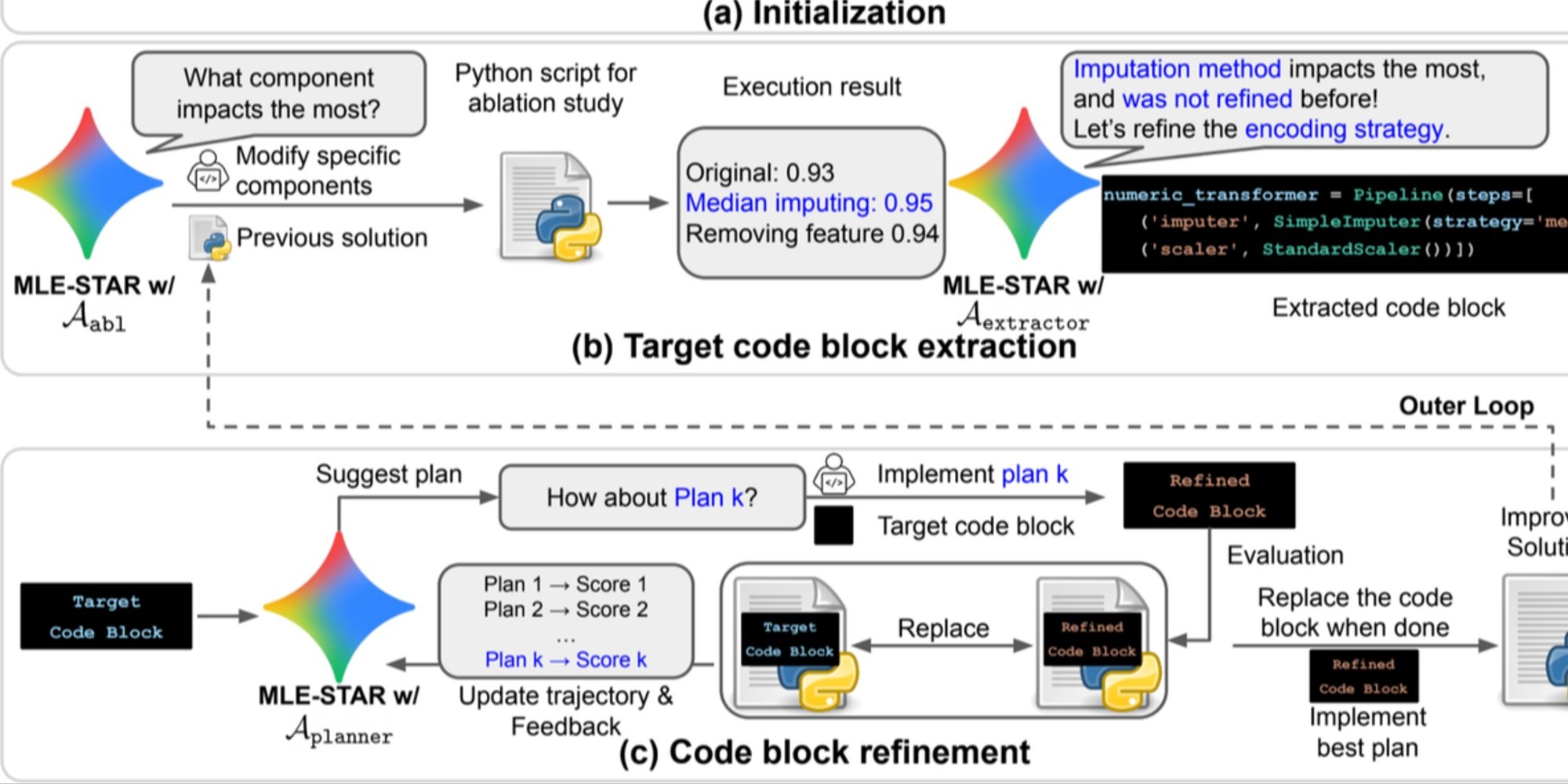
- Refinamiento granular por bloques de código, apoyándose en estudios de ablación para identificar las partes con mayor impacto en el rendimiento, luego optimizándolas iterativamente;
- Estrategia de ensamblaje adaptativa, capaz de fusionar varias soluciones candidatas en una versión mejorada, afinada a lo largo de los intentos.
Este proceso iterativo, búsqueda, identificación del bloque crítico, optimización, luego nueva iteración, permite a MLE-STAR concentrar sus esfuerzos donde producen los mayores beneficios medibles.
Crédito: Google Research.
Vista previa. a) MLE-STAR comienza utilizando la búsqueda en la web para encontrar e incorporar modelos específicos de una tarea en una solución inicial. (b) Para cada etapa de refinamiento, realiza un estudio de ablación para determinar el bloque de código con el impacto más significativo en el rendimiento. (c) El bloque de código identificado luego pasa por un refinamiento iterativo basado en los planes sugeridos por LLM, que exploran diversas estrategias utilizando los comentarios de las experiencias anteriores. Este proceso de selección y refinamiento del bloque de código objetivo se repite, donde la solución mejorada de (c) se convierte en el punto de partida de la etapa de refinamiento siguiente (b).
Módulos de control para asegurar la fiabilidad de las soluciones
Más allá de su enfoque iterativo, MLE-STAR integra tres módulos destinados a reforzar la robustez de las soluciones generadas:
- Un agente de depuración para analizar errores de ejecución (por ejemplo, un traceback de Python) y proponer correcciones automáticas;
- Un verificador de fuga de datos para detectar situaciones en las que se utilizan erróneamente datos de prueba durante el entrenamiento, un sesgo que distorsiona el rendimiento medido;
- Un verificador de uso de datos para asegurar que todas las fuentes de datos proporcionadas sean explotadas, incluso cuando no se presentan en formatos estándar como CSV.
Estos módulos responden a problemas comunes observados en el código generado por LLMs.
Resultados significativos en Kaggle
Para evaluar la efectividad de MLE-STAR, los investigadores lo probaron en el marco del benchmark MLE-Bench-Lite, basado en competiciones Kaggle. El protocolo medía la capacidad de un agente para producir, a partir de una simple descripción de tarea, una solución completa y competitiva.
Los resultados muestran que MLE-STAR obtiene una medalla en el 63 % de las competiciones, incluyendo 36 % de oro, frente a 25,8 % a 36,6 % para los mejores enfoques anteriores. Esta ganancia se atribuye a la combinación de varios factores: la adopción rápida de modelos recientes como EfficientNet o ViT, la capacidad de integrar modelos no identificados por la búsqueda web gracias a una intervención humana puntual, y las correcciones automáticas aportadas por los verificadores de fugas y uso de datos.
Encontrar el documento científico en arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
El código abierto está disponible en GitHub