
TLDR : La start-up china DeepSeek ha actualizado su modelo R1, mejorando su rendimiento en razonamiento, lógica, matemáticas y programación. Esta actualización, que reduce errores y mejora la integración aplicativa, permite a R1 competir con modelos estrella como o3 de Open AI y Gemini 2.5 Pro de Google.
Índice
Mientras que las especulaciones abundaban en torno al próximo lanzamiento de DeepSeek R2, finalmente fue una actualización del modelo R1 lo que la start-up china homónima anunció el pasado 28 de mayo. Bautizada como DeepSeek-R1-0528, esta versión refuerza las capacidades de R1 en áreas clave como el razonamiento, la lógica, las matemáticas y la programación. Ahora, el rendimiento de este modelo de código abierto publicado bajo licencia MIT se acerca al de los modelos estrella o3 de Open AI y Gemini 2.5 Pro de Google.
Mejoras significativas en la gestión de tareas de razonamiento complejo
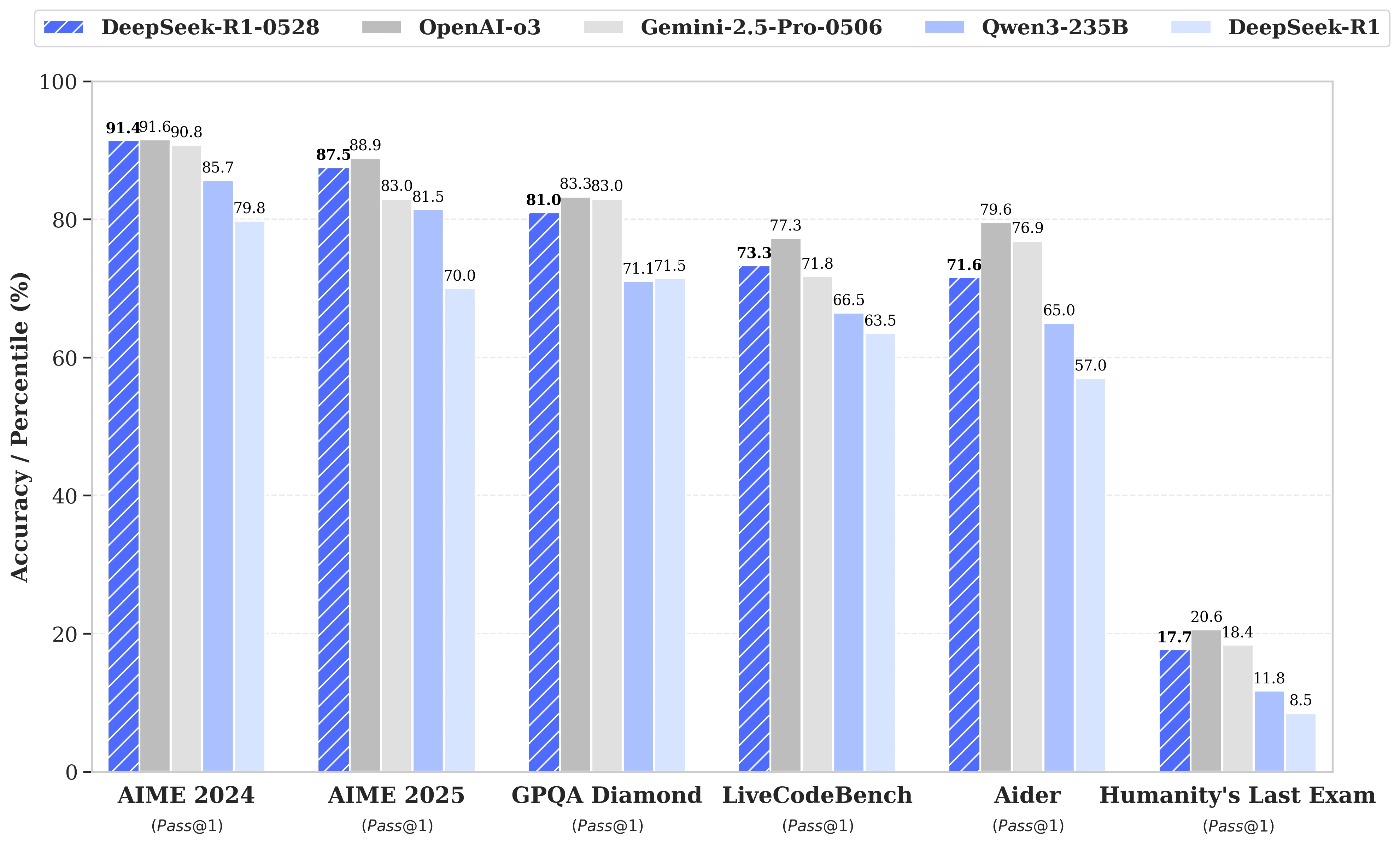
La actualización se basa en una explotación más eficaz de los recursos de cálculo disponibles, combinada con una serie de optimizaciones algorítmicas implementadas en post-entrenamiento. Estos ajustes se traducen en una mayor profundidad de reflexión durante el razonamiento: mientras que la versión anterior consumía en promedio 12,000 tokens por pregunta en las pruebas AIME, DeepSeek-R1-0528 ahora utiliza cerca de 23,000, con una notable mejora en la precisión, del 70% al 87.5% en la edición 2025 de la prueba.
- En matemáticas, las puntuaciones registradas alcanzan el 91.4% (AIME 2024) y el 79.4% (HMMT 2025), rozando o superando el rendimiento de algunos modelos cerrados como o3 o Gemini 2.5 Pro;
- En programación, el índice LiveCodeBench progresa cerca de 10 puntos (de 63.5 a 73.3%), y la evaluación SWE Verified sube del 49.2% al 57.6% de éxito;
- En razonamiento general, la prueba GPQA-Diamant ve la puntuación del modelo pasar del 71.5% al 81.0%, mientras que para el benchmark "Último examen de la humanidad", más que se duplica, pasando del 8.5% al 17.7%.
Reducción de errores y mejor integración aplicativa
Entre las evoluciones notables aportadas por esta actualización, se observa una sensible reducción de la tasa de alucinación, un desafío crítico para la fiabilidad de los LLMs. Al disminuir la frecuencia de respuestas factualmente inexactas, DeepSeek-R1-0528 gana en robustez, especialmente en contextos donde la precisión es indispensable.
La actualización también introduce funcionalidades orientadas hacia el uso en entornos estructurados, incluyendo la generación directa de salidas en formato JSON y el soporte ampliado para la llamada de funciones. Estos avances técnicos simplifican la integración del modelo en flujos de trabajo automatizados, agentes de software o sistemas back-end, sin necesidad de tratamientos intermedios pesados.
Una atención creciente a la destilación
En paralelo, el equipo de DeepSeek ha comenzado un enfoque de destilación de las cadenas de pensamiento hacia modelos más ligeros, para desarrolladores o investigadores con hardware limitado. DeepSeek-R1-0528, que cuenta con 685 B (mil millones) de parámetros, ha sido utilizado para post-entrenar Qwen3 8B Base.
El modelo resultante, DeepSeek-R1-0528-Qwen3-8B, logra igualar a modelos de código abierto mucho más voluminosos en algunos benchmarks. Con una puntuación del 86.0% en AIME 2024, supera no solo a Qwen3 8B en más de un 10.0%, sino que iguala el rendimiento de Qwen3-235B-thinking.
Un enfoque que cuestiona la viabilidad futura de los modelos masivos, frente a versiones más frugales pero mejor entrenadas para razonar.
DeepSeek afirma:
"Creemos que la cadena de pensamiento de DeepSeek-R1-0528 tendrá una importancia significativa tanto para la investigación académica sobre modelos de razonamiento como para el desarrollo industrial centrado en modelos a pequeña escala".