Alibaba anunció el pasado 21 de julio en X la publicación de la última actualización de su LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. El modelo de código abierto, distribuido bajo licencia Apache 2.0, cuenta con 235 mil millones de parámetros y se presenta como un serio competidor para DeepSeek‑V3, Claude Opus 4 de Anthropic, GPT-4o de OpenAI o Kimi 2 lanzado recientemente por la start-up china Moonshot, cuatro veces más grande.
Alibaba Cloud precisa en su publicación:
"Después de haber discutido con la comunidad y reflexionado sobre la cuestión, hemos decidido abandonar el modo de pensamiento híbrido. Ahora entrenaremos los modelos Instruct y Thinking por separado para obtener la mejor calidad posible".
Qwen3-235B-A22B-Instruct-2507 es un modelo no-pensante, es decir, que no opera razonamiento complejo en cadena pero privilegia la rapidez y la pertinencia en la ejecución de las instrucciones.
Gracias a esta orientación estratégica, Qwen 3 no solo progresa en el seguimiento de instrucciones sino que también muestra avances en razonamiento lógico, en comprensión fina de dominios especializados, en tratamiento de lenguas poco comunes, así como en matemáticas, ciencias, programación e interacción con herramientas digitales.
En las tareas abiertas, que implican juicio, tono o creación, se ajusta mejor a las expectativas del usuario, con respuestas más útiles y un estilo de generación más natural.
Su ventana contextual, llevada a 256,000 tokens, se ha multiplicado por ocho, lo que le permite ahora tratar documentos voluminosos.
Una arquitectura orientada a flexibilidad y eficiencia
El modelo se basa en una arquitectura Mixture-of-Experts (MoE) que cuenta con 128 expertos especializados, de los cuales 8 son seleccionados en función de la demanda: de sus 235 mil millones de parámetros, solo 22 mil millones son activados por solicitud.
Se apoya en 94 capas de profundidad, un esquema GQA (Grouped Query Attention) optimizado: 64 cabezas para la consulta (Q) y 4 para las claves/valores.
Rendimiento de Qwen3‑235B‑A22B‑Instruct‑2507
La nueva versión muestra resultados competitivos, incluso superiores, a los modelos de los líderes competidores, especialmente en matemáticas, codificación y razonamiento lógico.
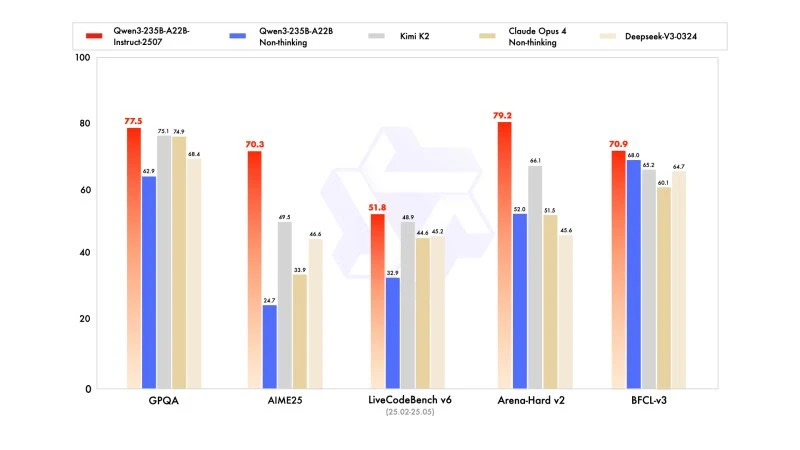
En conocimientos generales, obtuvo una puntuación de 83,0 en MMLU-Pro (frente a 75,2 de la versión anterior) y 93,1 en MMLU-Redux, acercándose al nivel de Claude Opus 4 (94,2).
En razonamiento avanzado, alcanzó una puntuación muy alta en modelización matemática: 70,3 en AIME (American Invitational Mathematics Examination) 2025, superando las puntuaciones de 46,6 de DeepSeek-V3-0324 y de 26,7 de GPT-4o-0327 de OpenAI.
En codificación, su puntuación de 87,9 en MultiPL‑E, lo posiciona detrás de Claude (88,5), pero delante de GPT-4o y DeepSeek. En LiveCodeBench v6, alcanza 51,8, la mejor performance medida en este benchmark.
Versión cuantificada en FP8: optimización sin compromisos
Al mismo tiempo que Qwen3-235B-A22B-Instruct-2507, Alibaba ha publicado su versión cuantificada en FP8. Este formato numérico comprimido reduce drásticamente las necesidades de memoria y acelera la inferencia, lo que permite al modelo funcionar en entornos donde los recursos son limitados, sin causar una pérdida significativa de rendimiento.