

A research team at Google Brain has revisited multilayer perceptrons (MLP) by designing MLP-Mixer. This is a no-frills model that approaches state-of-the-art performance in ImageNet classification, and could achieve performance comparable to systems like ViT (Vision Transformer), BiT (Big Transfer), HaloNet and NF-Net. In the future, it is quite possible that the simplest multilayer neural networks could be more sophisticated than the most advanced current architectures.
A study to exploit multilayer perceptrons for image classification and computer vision
Currently, convolutional neural networks excel in image processing and computer vision because they are designed to discern spatial relationships, and pixels that are close together in an image tend to be more related than pixels that are far apart.
MLPs do not have this bias, so they tend to take into account interpixel relationships that exist, but are not necessary to the image processing process. Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov and Lucas Beyer, along with Google Brain researchers, came up with the idea of modifying MLPs so that they could process and compare images through patches rather than by analyzing each pixel individually. So they designed MLP-Mixer, which allows MLPs to exploit this process.
Their creation waspublished in a paper entitled “MLP-Mixer: An all-MLP Architecture for Vision”. It should be noted that MLPs are the simplest “building blocks” of deep learning. This work shows that they can compete with the most powerful architectures for image classification.
How was MLP-Mixer designed and how does it work?
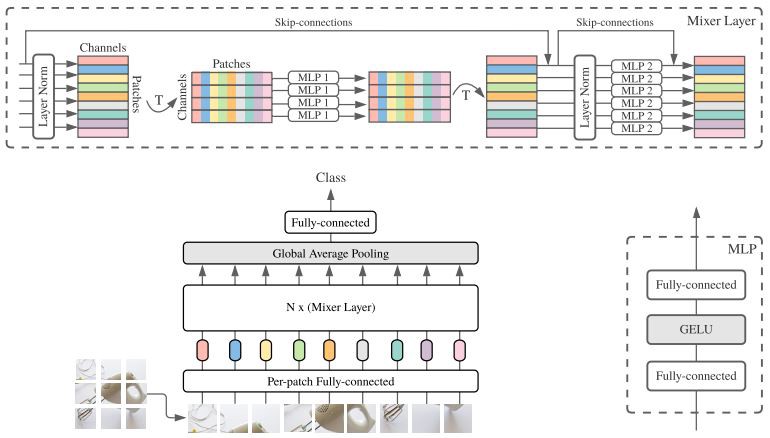
The authors pre-trained MLP-Mixer for image classification using ImageNet-21k, which contains 21,000 classes, and refined it on ImageNet which has 1,000 classes. Given an image divided into patches, MLP-Mixer uses an initial linear layer to generate 1,024 representations of each patch. MLP-Mixer stacks the representations in a matrix, so that each row contains all the representations of a patch and each column contains a representation of each patch.
MLP-Mixer consists of a series of mixing layers, each containing two MLPs, each consisting of two fully connected layers. Given a matrix, a mixer layer uses one MLP to mix the representations in the columns (which the authors call token mixing) and another to mix the representations in the rows (which the authors call channel mixing). This process renders a new matrix to be passed to the next mixer layer. A softmax layer renders a classification.
Encouraging results, but the hard part is yet to come…
According to the researchers, the MLP-Mixer with 16 mixer layers is 84.15 percent accurate for image classification. This is comparable to the accuracy of a 50-layer HaloNet (85.8%). The result is obviously satisfying, but it should be taken into account that MLP-Mixer only achieved this performance when it was pre-trained on a sufficiently large dataset.
When it was pre-trained on 10% of the JFT300M and refined on ImageNet, its accuracy rate drops to 54%, while the best performing ResNet-based models (such as BiT) trained in the same way achieve 67% accuracy. The researchers know they have more work to do, but they are hopeful with these encouraging results.
Translated from MLP-Mixer : le modèle de Google Brain qui exploite les perceptrons multicouches pour la classification d’images








