
TLDR : Mistral AI 推出 Voxtral 开源音频模型,专为专业用途设计,挑战现有市场主导者。
目录
上周二,Mistral AI 宣布推出 Voxtral,其首个开源音频模型系列。该系列专为专业用途设计,这些语音理解模型标志着这家法国独角兽公司进入战略性的语音智能领域,此前该领域一直由 OpenAI、Meta 和 Google 等公司主导。
Voxtral 系列包括两个主要模型:Voxtral Small(240 亿参数)和 Voxtral Mini(30 亿参数),分别适用于不同的环境。Small 模型定位于复杂的使用案例和大规模云部署,而 Mini 版本则针对嵌入式或资源有限的部署。Mistral AI 还提供 Voxtral Mini Transcribe,这是一个专为语音转录优化的版本,其性价比优于 Whisper 等模型。
超越转录的功能
Voxtral 是针对不可靠的 ASR(自动语音识别)系统和昂贵的封闭专有 API 的一种替代方案。
该模型设计用于处理长音频上下文,可支持长达 30 分钟的转录或 40 分钟的理解,其窗口大小为 32,000 个标记。
基于 Mistral Small 3.1 语言模型架构,Voxtral 可以响应口头请求,从音频文件生成摘要,或将口头表达的意图转化为 API 调用或后端流程。该模型支持多种常用语言,包括英语、西班牙语、阿拉伯语、法语、葡萄牙语、印地语、德语、荷兰语和意大利语。
卓越的性能
根据 Mistral 提供的初步评估,Voxtral Small 在多项自动转录指标上超越了参考模型 Whisper v3,以及 Open AI 的 Gemini 2.5 Flash 和 GPT-4o Mini Transcribe,同时资源消耗得到有效控制。
在 FLEURS(见下图)中,Voxtral Small 在测试的所有语言中表现出色,其准确性优于 Whisper。
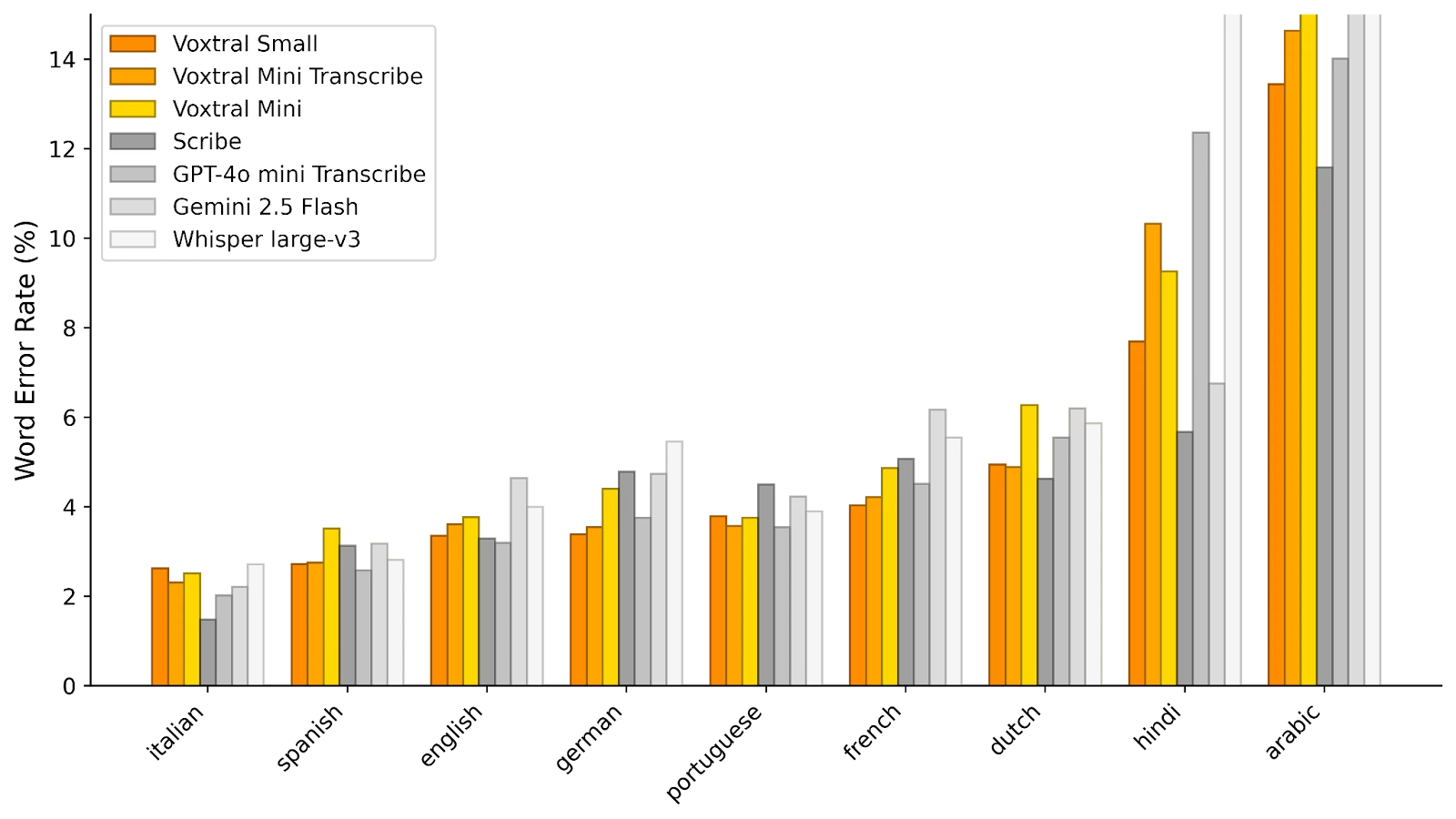
© Mistral AI
在语音翻译任务中,Voxtral Small 与 GPT-4o Mini 和 Gemini 具有竞争力。
可用性
这两个模型以 Apache 2.0 许可证发布,可在 Hugging Face 下载。对于希望将其集成到应用中的用户,Voxtral 还通过 API 提供,每分钟 0.001 美元起,比竞争对手的报价低一半以上,并将在不久后丰富 Mistral AI 的对话助手 Le Chat。
对于特定业务上下文,企业可以选择私人和安全的部署,特别是在法律或医疗领域。
Mistral AI 计划在未来几个月内为其添加新功能,如音频分割、说话人识别(不同说话者的识别)或情感检测。
市场动态扩展
此发布正值音频转录和分析解决方案需求旺盛之际,客户支持、交互分析、自动化文档或语音助手等使用案例加速发展。Voxtral 插入了一个已经被 Whisper(OpenAI,MIT)、SeamlessM4T(Meta,非商业)或 NVIDIA NeMo 和 ESPnet 等框架所占据的空间。
但目前为止,只有少数产品能够在单一解决方案中提供开放访问、集成语义理解和从语音触发操作的能力。
Cet article publirédactionnel est publié dans le cadre d'une collaboration commerciale