
上周末,当所有人都把目光投向DeepSeek及其模型R1时,法国独角兽Mistral AI悄然推出了Mistral Small 3。该模型在Apache 2.0许可下发布,拥有240亿参数,优化了延迟,据称这是"对像GPT4o-mini这样不透明的专有模型的优秀开源替代"。
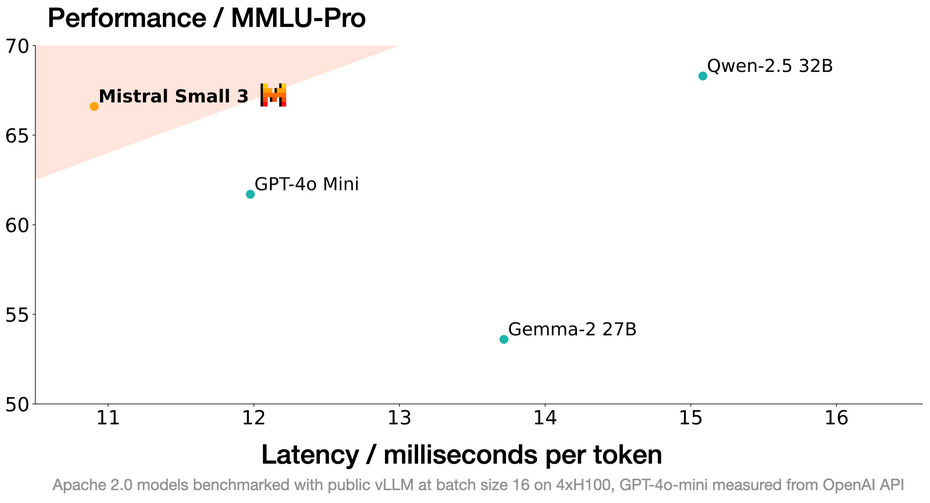
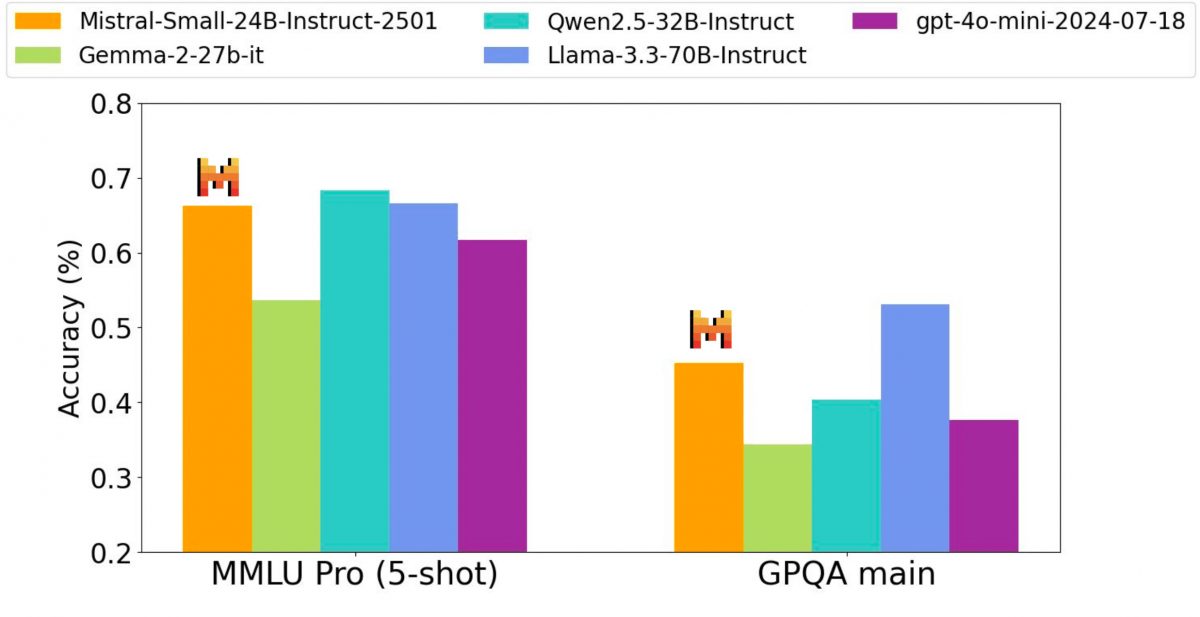
通过Small 3,这家独角兽公司再次证明了要实现高性能,大型语言模型(LLM)并不需要庞大的参数数量。该模型凭借每秒处理150个token的速度,以及在MMLU基准测试中超过81%的准确率,满足了日益增长的效率需求。
这种技术成就是通过优化架构实现的,减少了传统层数,从而降低了前向传播时间(一个神经网络模型处理输入并生成输出所需的时间),而不影响响应质量。
这种架构选择使得优化版本Mistral Small 3 Instruct能够与更大型的模型如Llama 3.3 70B或Qwen 32B竞争,同时确保在标准硬件上快速且高效的执行。
多行业应用
Mistral Small 3不仅在技术性能上表现出色,还致力于适应企业的具体需求。在预期使用案例中,多个领域脱颖而出:- 对话助手和功能调用:低延迟确保实时互动,这对聊天机器人或虚拟助手至关重要;
- 针对特定专业的微调:其小巧的体积便于针对特定领域进行精细调整,如医疗诊断或法律咨询;
- 本地推理:能够在可访问的硬件上部署模型,有利于在需要本地处理敏感数据的行业使用。
开放与协作的传播策略
根据Mistral AI的说法,参考DeepSeek的最新模型及Open-R1项目,"这是开源社区令人振奋的日子!Mistral Small 3补充了像DeepSeek最新版本这样的大型开源推理模型,并能作为一个坚实的基础模型,帮助开发推理能力"。公司选择在Apache 2.0许可下发布它,逐步放弃其更具限制性的MRL许可用于通用模型。公司已经宣布"未来几周将推出小型和大型Mistral模型,具有更强的推理能力"。
目前,Mistral Small 3可在Hugging Face、Ollama、Kaggle、Together AI和Fireworks AI等平台上使用,不久将在NVIDIA NIM、Amazon SageMaker、Groq、Databricks和Snowflake上提供。