TLDR : Google 的研究人员开发了 MLE-STAR,这是一种机器学习代理,通过结合目标网络搜索、代码优化和自适应组装来改进 AI 模型创建过程。MLE-STAR 在基于 Kaggle 的基准 MLE-Bench-Lite 中赢得了 63% 的比赛,远远超过了之前的方法。
目录
基于大型语言模型(LLMs)的机器学习工程代理(MLE)在自动化部分或全部机器学习模型开发过程中,开辟了新的视角。然而,现有解决方案往往在探索性或方法多样性方面受到限制。Google 的研究人员通过 MLE-STAR 回应了这些挑战,这是一种结合了目标网络搜索、代码块细化以及自适应组装策略的代理。
具体而言,一个 MLE 代理从任务描述(例如,“根据表格数据预测销售”)和提供的数据集开始,然后:
- 分析问题并选择合适的方法;
- 生成代码(通常使用 Python 以及常见或专业的机器学习库);
- 测试、评估和优化解决方案,有时需要多次迭代。
这些代理依赖于 LLM 的两项关键能力:
- 算法推理(为给定问题识别相关方法);
- 生成可执行代码(完整的数据准备、训练和评估脚本)。
他们的目标是通过自动化繁琐的步骤,如特征工程、超参数调优或模型选择,来减少人类的工作量。
MLE-STAR:目标明确且迭代优化
根据 Google Research,现有的 MLE 面临两个主要障碍。首先,他们对 LLM 内部知识的高度依赖使其倾向于偏爱通用且成熟的方法,如 scikit-learn 库用于表格数据,而不是更专业且可能更高效的方法。其次,他们的探索策略通常依赖于每次迭代的完整代码重写。这种操作方式阻止了他们专注于管道的特定组件,例如在进行其他步骤之前系统地测试不同的特征工程选项。
为了突破这些限制,Google 的研究人员设计了 MLE-STAR,这是一种结合了三个杠杆的代理:
- 网络搜索以识别特定任务的模型并构建一个坚实的初始解决方案;
- 通过代码块的细化,利用消融研究识别对性能影响最大的部分,然后迭代优化它们;
- 自适应组装策略,能够将多个候选解决方案融合成一个经过改进的版本,并在尝试过程中精细化。
这种迭代过程,搜索、关键块识别、优化,然后再进行新一轮迭代,使得 MLE-STAR 能够专注于产生最大可测量收益的地方。
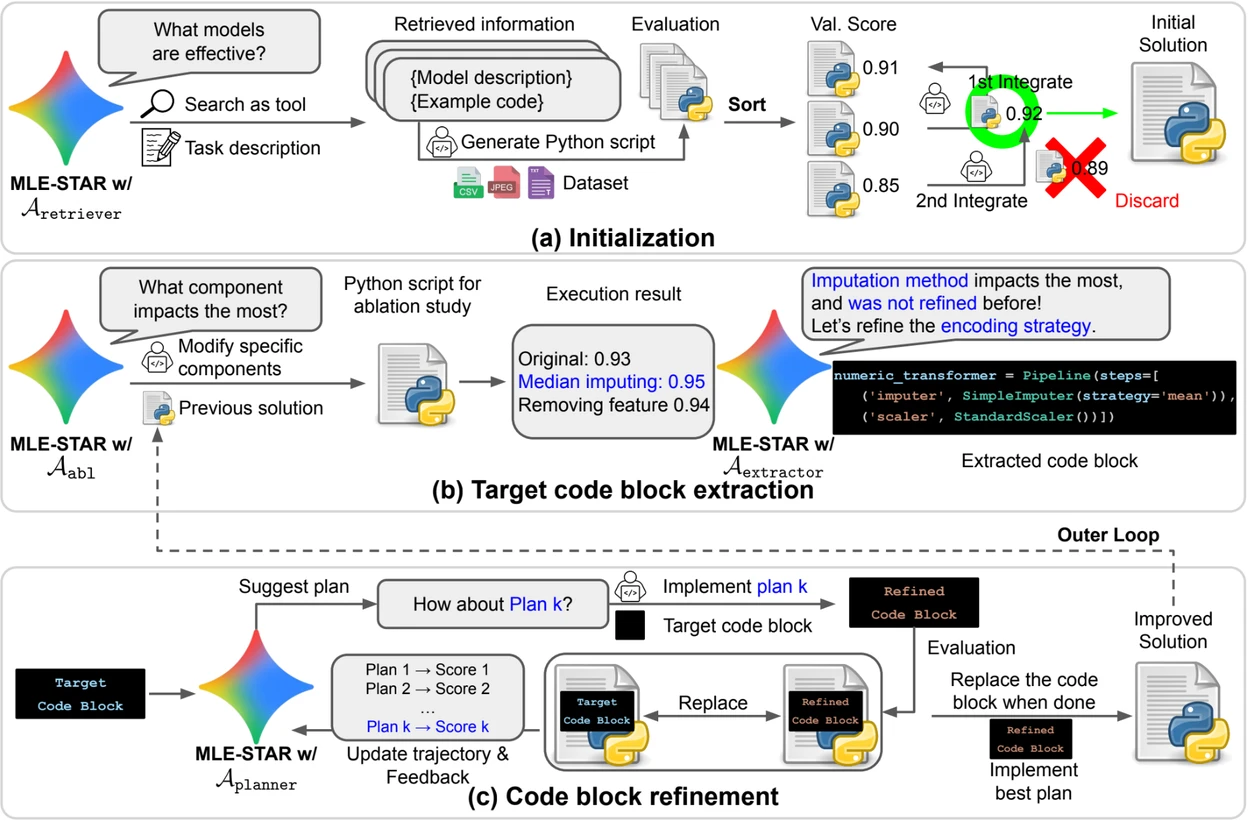
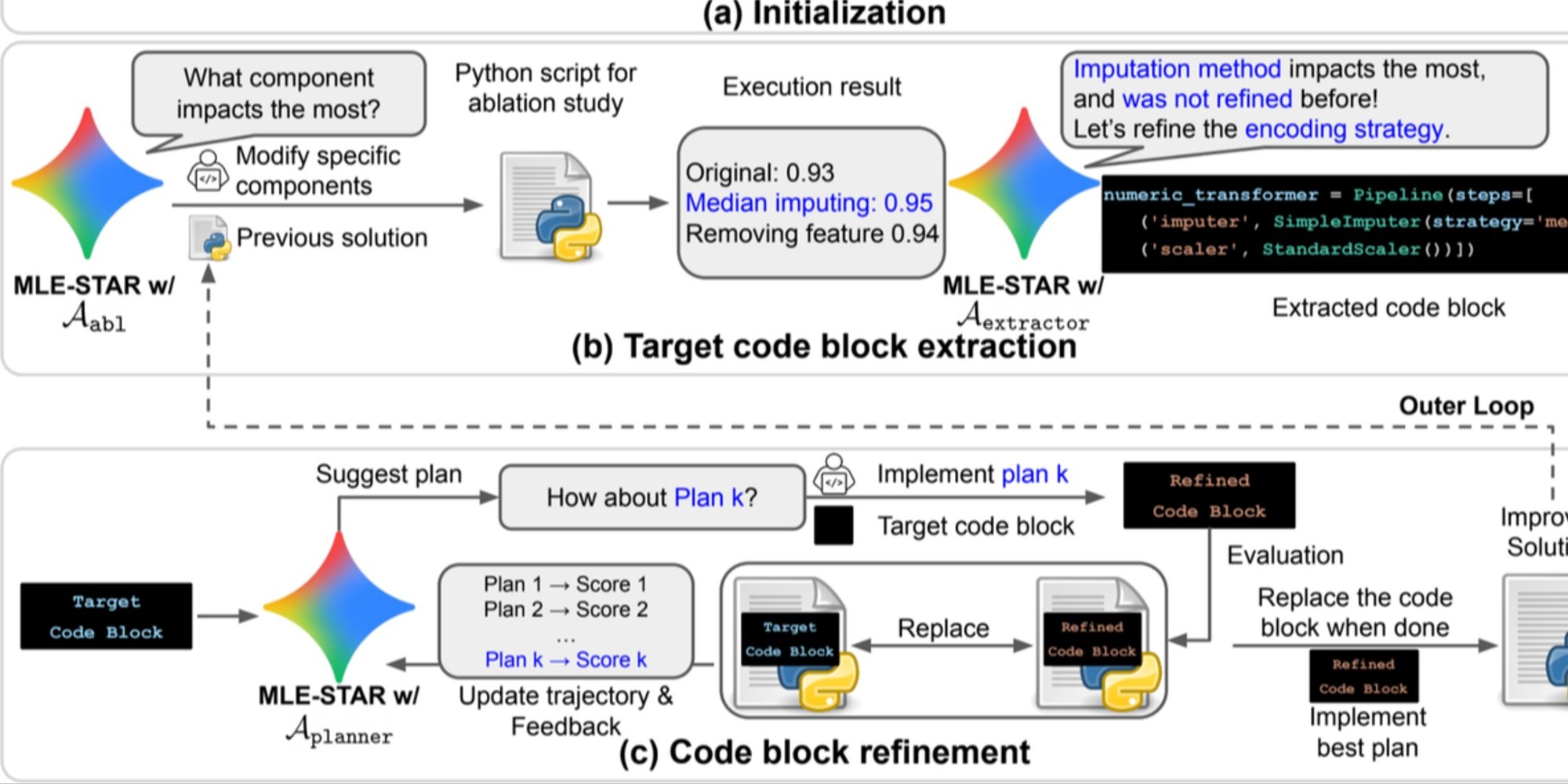
图片来源:Google Research。
概览。a) MLE-STAR 首先通过网络搜索找到并将特定任务的模型纳入初始解决方案。 (b) 对于每个细化步骤,它进行消融研究以确定对性能影响最大的代码块。 (c) 然后根据 LLM 提出的计划,对识别的代码块进行迭代优化,该计划探索使用前次实验反馈的各种策略。 这种代码块选择和细化过程重复进行,其中改进的 (c) 解决方案成为接下来的细化步骤的起点 (b)。
控制模块以增强解决方案的稳定性
除了其迭代方法,MLE-STAR 还集成了三个模块,旨在增强生成解决方案的稳健性:
- 调试代理 用于分析执行错误(例如,Python 的 traceback)并提供自动修正建议;
- 数据泄露检查器 用于 检测在训练过程中错误使用测试数据的信息,这种偏差会导致测量性能失真;
- 数据使用检查器 确保所有提供的数据源都被利用,即使它们不是以 CSV 这样的标准格式出现。
这些模块解决了 LLM 生成代码中常见的问题。
在 Kaggle 上的显著结果
为了评估 MLE-STAR 的有效性,研究人员在基于 Kaggle 比赛的 MLE-Bench-Lite 基准中对其进行了测试。该协议测量了代理从简单任务描述生成完整且有竞争力的解决方案的能力。
结果显示,MLE-STAR 在 63% 的比赛中获得了奖牌,其中 36% 是金牌,而之前最佳方法的获奖率为 25.8% 至 36.6%。这种收益归因于多个因素的结合:快速采用像 EfficientNet 或 ViT 这样的新模型、通过人类的偶尔干预来整合未被网络搜索识别的模型,以及数据泄露和数据使用检查器提供的自动校正。
在 arXiv 上查看科学论文 : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
开源代码 可在 GitHub 上获得