
TLDR : 中国初创公司DeepSeek更新了其R1模型,提高了其在推理、逻辑、数学和编程方面的性能。此次更新减少了错误并改善了应用集成,使R1能够与Open AI的o3和Google的Gemini 2.5 Pro等旗舰模型竞争。
目录
在关于DeepSeek R2即将发布的猜测甚嚣尘上之际,这家同名的中国初创公司于5月28日宣布更新其R1模型。被命名为DeepSeek-R1-0528的版本增强了R1在推理、逻辑、数学和编程等关键领域的能力。如今,这个以MIT开源许可发布的模型的性能接近Open AI的o3和Google的Gemini 2.5 Pro等旗舰模型。
在复杂任务推理管理方面的显著改进
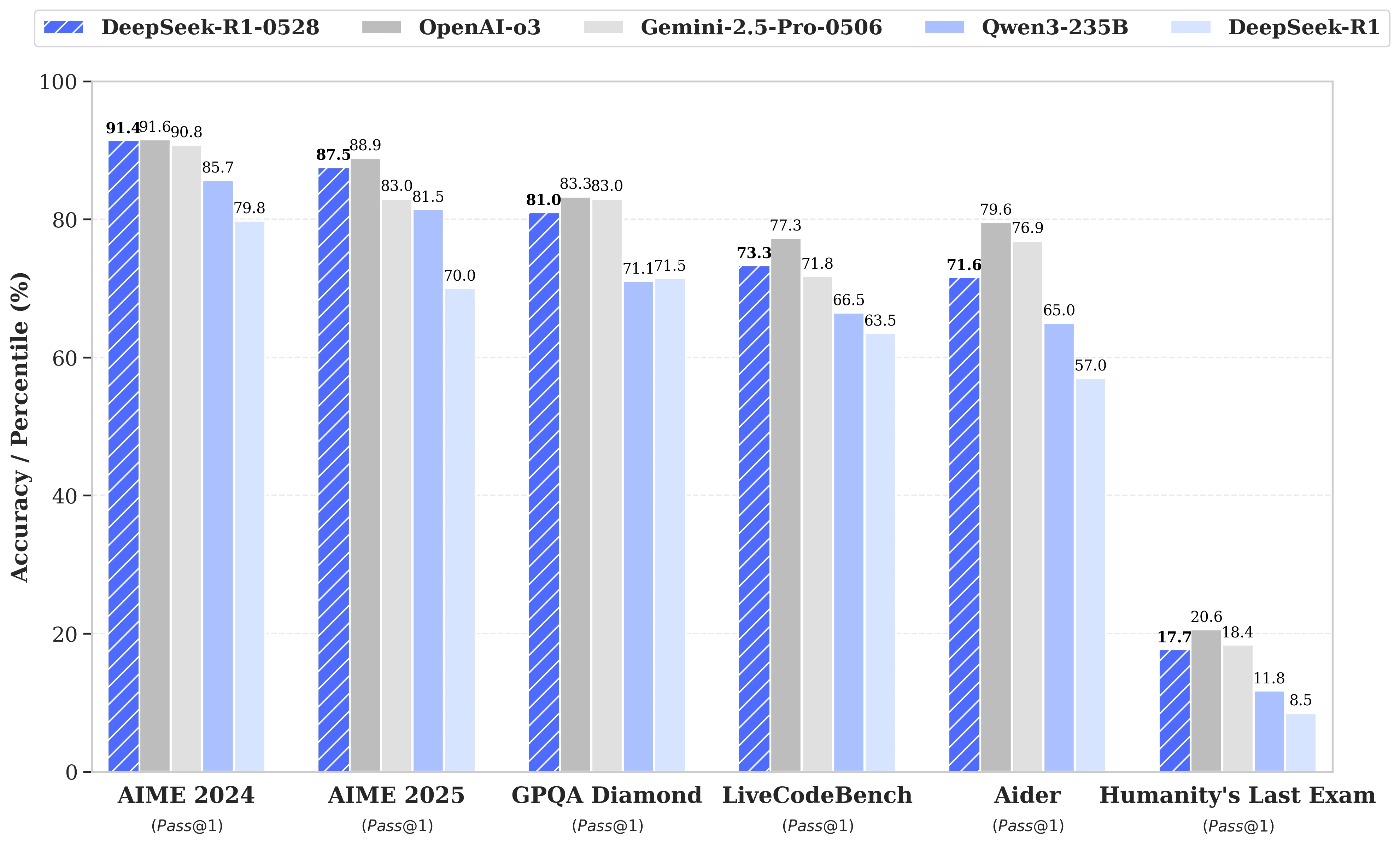
此次更新依托于更高效地利用可用计算资源,结合一系列在后期训练中实施的算法优化。这些调整带来了推理深度的提升:之前版本在AIME测试中平均每个问题消耗12,000个tokens,而DeepSeek-R1-0528现在使用近23,000个,精度显著提高,从70%提升到2025版测试的87.5%。
- 在 数学方面,成绩达到91.4% (AIME 2024)和79.4% (HMMT 2025),接近或超越一些封闭模型如o3或Gemini 2.5 Pro的性能;
- 在 编程方面,LiveCodeBench指数提高了近10分(从63.5%到73.3%),SWE Verified的评估从49.2%提升到57.6%的成功率;
- 在 一般推理方面,GPQA-Diamant测试中模型的得分从71.5%提高到81.0%,而在“人类最后的考试”基准上,得分从8.5%翻倍到17.7%。
减少错误和更好的应用集成
此更新所带来的显著变化之一是显著降低了幻觉率,这是LLMs可靠性的一项关键挑战。通过减少事实不准确的回答频率,DeepSeek-R1-0528在需要精确性的环境中变得更加稳健。
此次更新还引入了一些面向结构化环境使用的功能,特别是直接生成JSON格式的输出和扩展的函数调用支持。这些技术进步简化了模型在自动化工作流、软件代理或后端系统中的集成,而无需繁重的中间处理。
对蒸馏的日益关注
与此同时,DeepSeek团队开始了一项将思维链蒸馏到更轻量模型的工作,适用于硬件资源有限的开发者或研究人员。DeepSeek-R1-0528拥有685 B(十亿)参数,因而被用于后期训练Qwen3 8B Base。
由此产生的模型,DeepSeek-R1-0528-Qwen3-8B,在某些基准上可与体积更大的开源模型媲美。凭借86.0%的AIME 2024得分,它不仅超过了Qwen3 8B超过10.0%的成绩,还与Qwen3-235B-thinking的性能持平。
这种方法引发了对大规模模型未来可行性的质疑,因为更精简但训练有素的版本可能更具优势。
DeepSeek表示:
"我们认为DeepSeek-R1-0528的思维链对推理模型的学术研究和以小规模模型为重点的工业开发都将具有重大意义。"