阿里巴巴于7月21日通过 X 宣布发布其最新的 LLM Qwen 3 更新:Qwen3-235B-A22B-Instruct-2507。该开源模型在 Apache 2.0 许可证下分发,拥有 2350 亿个参数,并被视为 DeepSeek‑V3、Anthropic 的 Claude Opus 4、OpenAI 的 GPT-4o 或中国初创公司 Moonshot 最近推出的四倍大的 Kimi 2 的有力竞争者。
阿里云在其帖子中指出:
“经过与社区的讨论和深思熟虑,我们决定放弃混合思维模式。我们将分别训练 Instruct 和 Thinking 模型,以获得最佳质量。”
Qwen3-235B-A22B-Instruct-2507 是一个非思维(non-thinking)模型,即不进行复杂的链式推理,而是优先考虑指令执行的速度和准确性。
通过这一战略方向,Qwen 3 不仅在指令跟随中取得进展,还在逻辑推理、专业领域的精细理解、处理罕见语言、数学、科学、编程及与数字工具的互动等方面展示了进步。
在涉及判断、语气或创造的开放任务中,它更好地适应用户期望,提供更有用的响应和更自然的生成风格。
其上下文窗口扩展到 256,000 个 token,增加了八倍,使其现在可以处理大规模文档。
面向灵活性和效率的架构
该模型基于一个包含 128 个专家的 Mixture-of-Experts(MoE)架构,根据需求选择其中 8 个:在其 2350 亿个参数中,每个请求仅激活 220 亿个。
它依靠 94 层深度和一个优化的 GQA(Grouped Query Attention)方案:查询(Q)有 64 个头,键/值有 4 个头。
Qwen3‑235B‑A22B‑Instruct‑2507 的性能
新版本显示出与竞争对手领导者的模型相比有竞争力甚至更好的结果,尤其是在数学、编码和逻辑推理方面。
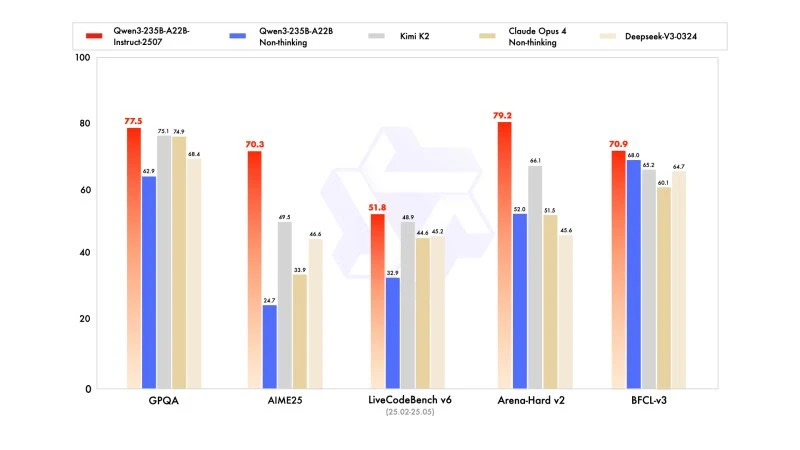
在一般知识方面,它在 MMLU-Pro 上获得了 83.0 的分数(相比之前版本的 75.2),在 MMLU-Redux 上获得了 93.1,接近 Claude Opus 4 的 94.2。
在高级推理方面,它在数学建模中取得了很高的分数:在 2025 年 AIME(美国邀请数学考试)上达到 70.3,超过了 DeepSeek-V3-0324 的 46.6 和 OpenAI 的 GPT-4o-0327 的 26.7。
在编码方面,其在 MultiPL-E 上获得 87.9 分,位于 Claude(88.5)之后,但领先于 GPT-4o 和 DeepSeek。在 LiveCodeBench v6 上,其达到 51.8,是该基准测试中测得的最佳性能。
FP8 量化版本:优化无妥协
与 Qwen3-235B-A22B-Instruct-2507 同时,阿里巴巴发布了其 FP8 量化版本。该压缩数字格式大幅减少内存需求并加快推理速度,使得模型能够在资源有限的环境中运行,而不显著降低性能。