أعلنت Alibaba في 21 يوليو الماضي على X عن إصدار آخر تحديث لنموذجها LLM Qwen 3: Qwen3-235B-A22B-Instruct-2507. النموذج مفتوح المصدر، يتم توزيعه تحت رخصة Apache 2.0، ويحتوي على 235 مليار متغير ويُعتبر منافسًا جديًا لـ DeepSeek-V3، وClaude Opus 4 من Anthropic، وGPT-4o من OpenAI، أو Kimi 2 الذي أطلقته مؤخرًا شركة Moonshot الصينية الناشئة، والذي يعد أكبر بأربع مرات.
توضح Alibaba Cloud في منشورها:
"بعد مناقشة مع المجتمع والتفكير في الأمر، قررنا التخلي عن وضع التفكير الهجين. سنقوم الآن بتدريب النماذج Instruct وThinking بشكل منفصل للحصول على أفضل جودة ممكنة".
Qwen3-235B-A22B-Instruct-2507 هو نموذج غير مفكر، (غير مفكر)، أي أنه لا يقوم بتنفيذ عمليات تفكير معقدة متسلسلة ولكنه يفضل السرعة والملاءمة في تنفيذ التعليمات.
بفضل هذا التوجه الاستراتيجي، لا يكتفي Qwen 3 بالتقدم في متابعة التعليمات بل يظهر أيضًا تقدمًا في التفكير المنطقي، وفهم مجالات متخصصة بشكل دقيق، ومعالجة لغات نادرة الاستخدام، بالإضافة إلى الرياضيات والعلوم والبرمجة والتفاعل مع الأدوات الرقمية.
في المهام المفتوحة، التي تتضمن الحكم أو النبرة أو الإبداع، يتكيف النموذج بشكل أفضل مع توقعات المستخدم، مع ردود أكثر فائدة وأسلوب توليد أكثر طبيعية.
نافذته السياقية، التي تصل إلى 256,000 tokens، تم زيادتها إلى ثمانية أضعاف، مما يمكنه الآن من معالجة مستندات ضخمة.
هندسة موجهة نحو المرونة والكفاءة
يعتمد النموذج على هندسة Mixture-of-Experts (MoE) التي تضم 128 خبيرًا متخصصًا، يتم اختيار 8 منهم بناءً على الطلب: من بين 235 مليار متغير، يتم تفعيل 22 مليار فقط لكل طلب.
يعتمد على 94 طبقة من العمق، ومخطط GQA (Grouped Query Attention) المحسن: 64 رأسًا للاستعلام (Q) و4 للمفاتيح/القيم.
أداء Qwen3‑235B‑A22B‑Instruct‑2507
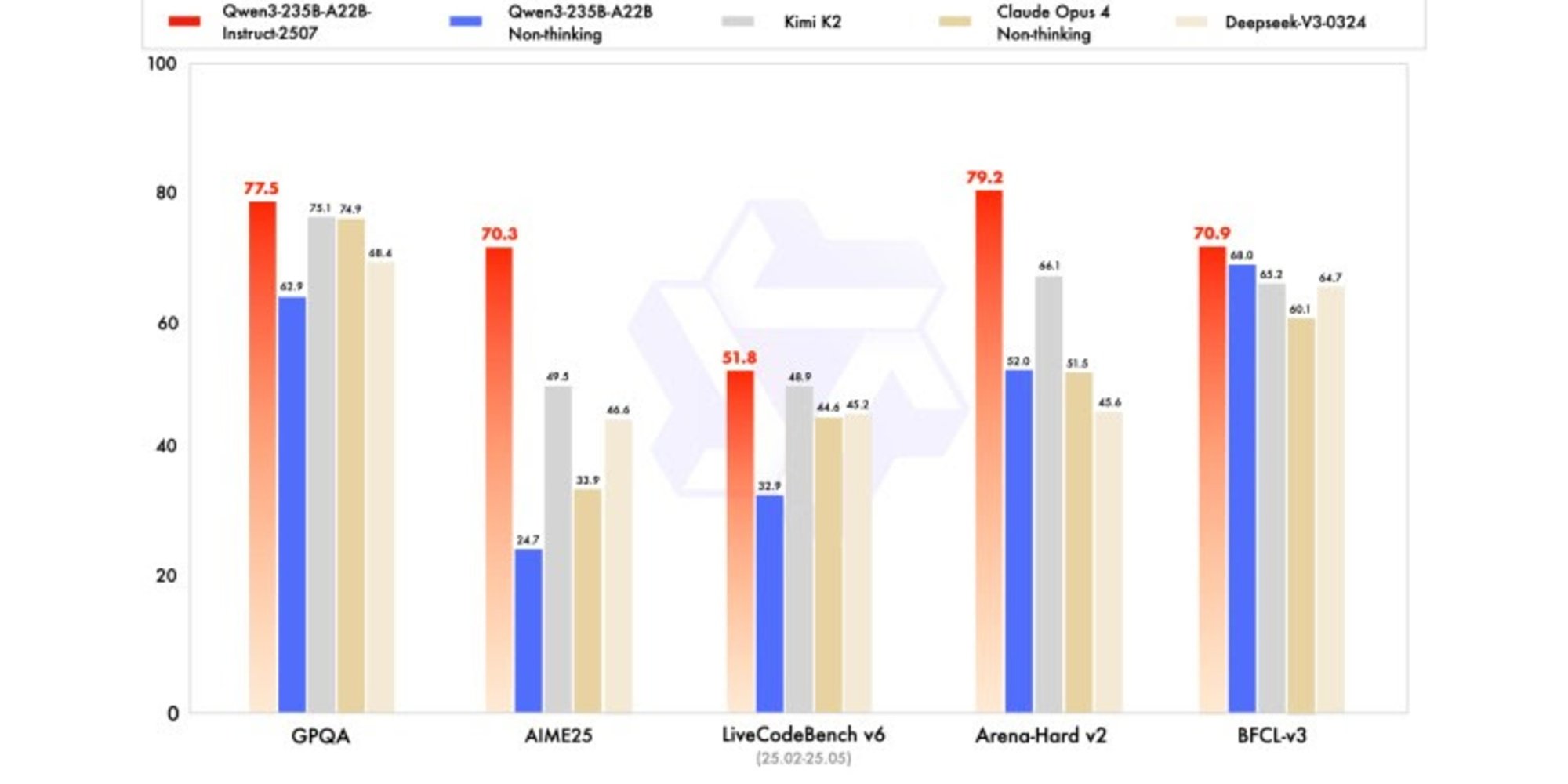
تعرض النسخة الجديدة نتائج تنافسية، بل وأحيانًا متفوقة، على نماذج المنافسين الرائدين، لا سيما في الرياضيات والبرمجة والتفكير المنطقي.
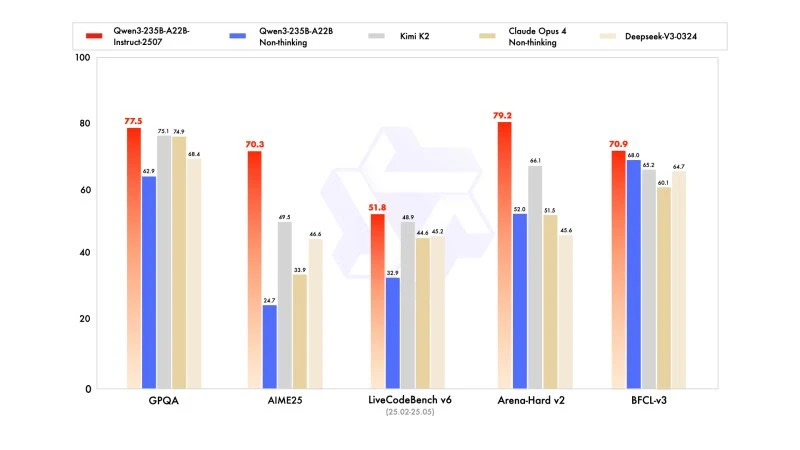
في المعارف العامة، حصل على درجة 83,0 في MMLU-Pro (مقابل 75,2 للنسخة السابقة) و93,1 في MMLU-Redux، مقتربًا من مستوى Claude Opus 4 (94,2).
في التفكير المتقدم، حصل على درجة عالية جدًا في النمذجة الرياضية: 70,3 في AIME (American Invitational Mathematics Examination) 2025، متجاوزًا درجات 46,6 لـ DeepSeek-V3-0324 و26,7 لـ GPT-4o-0327 من OpenAI.
في البرمجة، حصل على درجة 87,9 في MultiPL‑E، مما يجعله خلف Claude (88,5)، ولكنه أمام GPT-4o وDeepSeek. في LiveCodeBench v6، حقق 51,8، وهي أفضل أداء تمت قياسه على هذا benchmark.
نسخة مضغوطة FP8: تحسين دون تنازلات
في الوقت نفسه مع Qwen3-235B-A22B-Instruct-2507، نشرت Alibaba نسختها المضغوطة في FP8. هذا التنسيق الرقمي المضغوط يقلل بشكل جذري احتياجات الذاكرة ويسرع الاستدلال، مما يسمح للنموذج بالعمل في البيئات التي تكون الموارد فيها محدودة، وذلك دون التسبب في فقدان كبير في الأداء.