TLDR : طور باحثو جوجل MLE-STAR، وكيل تعلم آلي يحسن عملية إنشاء نماذج الذكاء الاصطناعي عبر البحث على الويب الموجه، تحسين الكود، والتجميع التكيفي. أثبت MLE-STAR فعاليته بفوزه بـ 63% من المسابقات في معيار MLE-Bench-Lite المستند إلى Kaggle، متفوقًا على النهج السابقة.
المحتوى
لقد فتح وكلاء MLE (Machine Learning Engineering agent)، المبنيون على نماذج لغة كبيرة (LLMs)، آفاقًا جديدة في تطوير نماذج التعلم الآلي من خلال أتمتة كل أو جزء من العملية. ومع ذلك، غالبًا ما تواجه الحلول الموجودة حدودًا في الاستكشاف أو نقصًا في التنوع المنهجي. يواجه الباحثون في جوجل هذه التحديات باستخدام MLE-STAR، وهو وكيل يجمع بين البحث على الويب الموجه، تحسين الكود بشكل دقيق، واستراتيجية تجميع تكيفية.
بشكل ملموس، يبدأ وكيل MLE بوصف المهمة (على سبيل المثال، "التنبؤ بالمبيعات من البيانات الجدولية") ومن ثم:
- تحليل المشكلة واختيار النهج المناسب؛
- توليد الكود (غالبًا بلغة Python، باستخدام مكتبات ML شائعة أو متخصصة)؛
- اختبار، تقييم وتحسين الحل، أحيانًا عبر عدة تكرارات.
يعتمد هؤلاء الوكلاء على مهارتين رئيسيتين لنماذج LLM:
- التفكير الخوارزمي (تحديد الأساليب المناسبة لمشكلة معينة)؛
- توليد الكود القابل للتنفيذ (نصوص كاملة لتحضير البيانات، التدريب والتقييم).
هدفهم هو تقليل عبء العمل البشري من خلال أتمتة خطوات شاقة مثل هندسة الميزات، ضبط المعلمات الفائقة أو اختيار النماذج.
MLE-STAR: تحسين موجه وتكراري
وفقًا لجوجل ريسيرش، تواجه MLE الحالية عقبتين رئيسيتين. أولاً، اعتمادها الكبير على المعرفة الداخلية لنماذج LLMs يدفعها لتفضيل أساليب عامة ومعروفة جيدًا، مثل مكتبة scikit-learn للبيانات الجدولية، على حساب مناهج أكثر تخصصًا وربما أكثر أداءً.
ثانيًا، تعتمد استراتيجيتها الاستكشافية غالبًا على إعادة كتابة الكود بالكامل في كل تكرار. هذا الأسلوب يمنعها من تركيز جهودها على مكونات محددة في خط الأنابيب، مثل اختبار خيارات هندسة الميزات بشكل منهجي قبل الانتقال إلى خطوات أخرى.
ثانيًا، تعتمد استراتيجيتها الاستكشافية غالبًا على إعادة كتابة الكود بالكامل في كل تكرار. هذا الأسلوب يمنعها من تركيز جهودها على مكونات محددة في خط الأنابيب، مثل اختبار خيارات هندسة الميزات بشكل منهجي قبل الانتقال إلى خطوات أخرى.
لتجاوز هذه الحدود، قام باحثو جوجل بتصميم MLE-STAR، وكيل يجمع بين ثلاثة عوامل:
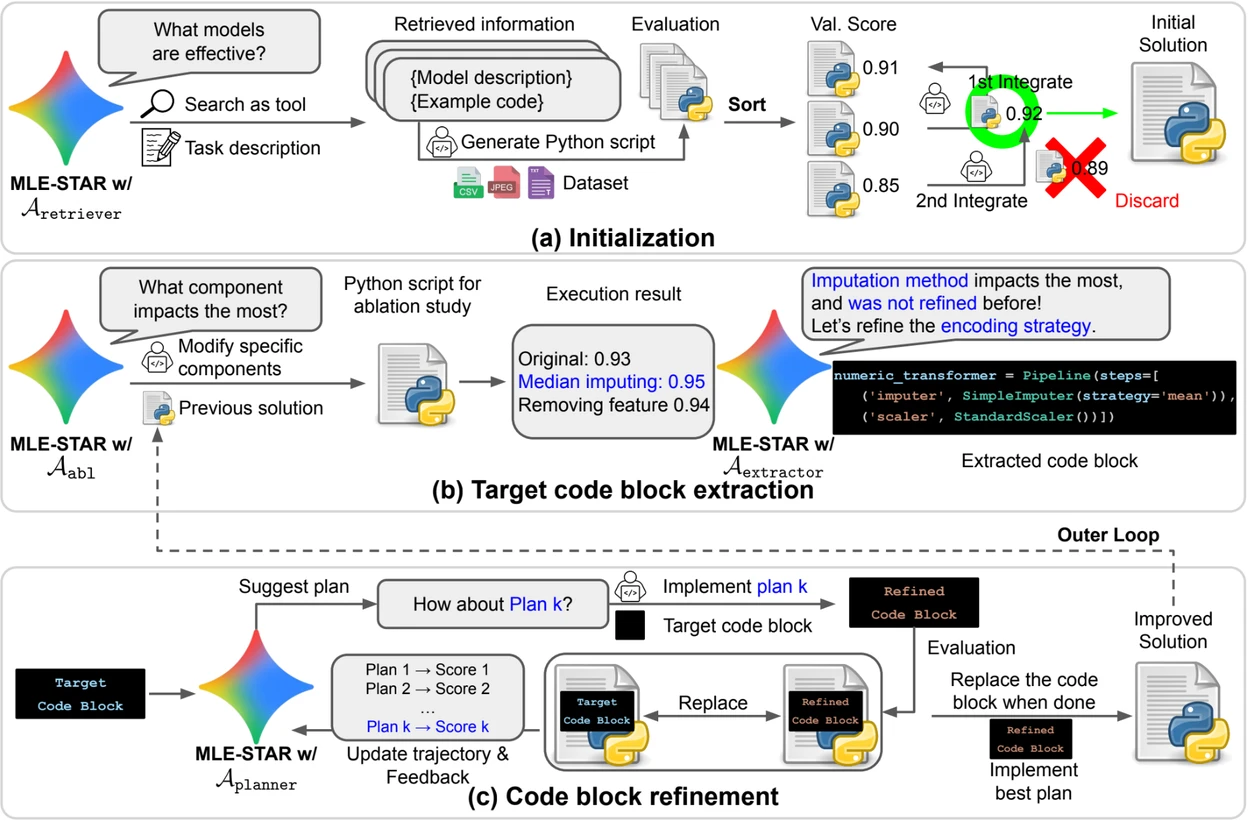
- بحث على الويب لتحديد نماذج خاصة بالمهمة وتكوين حل أولي قوي؛
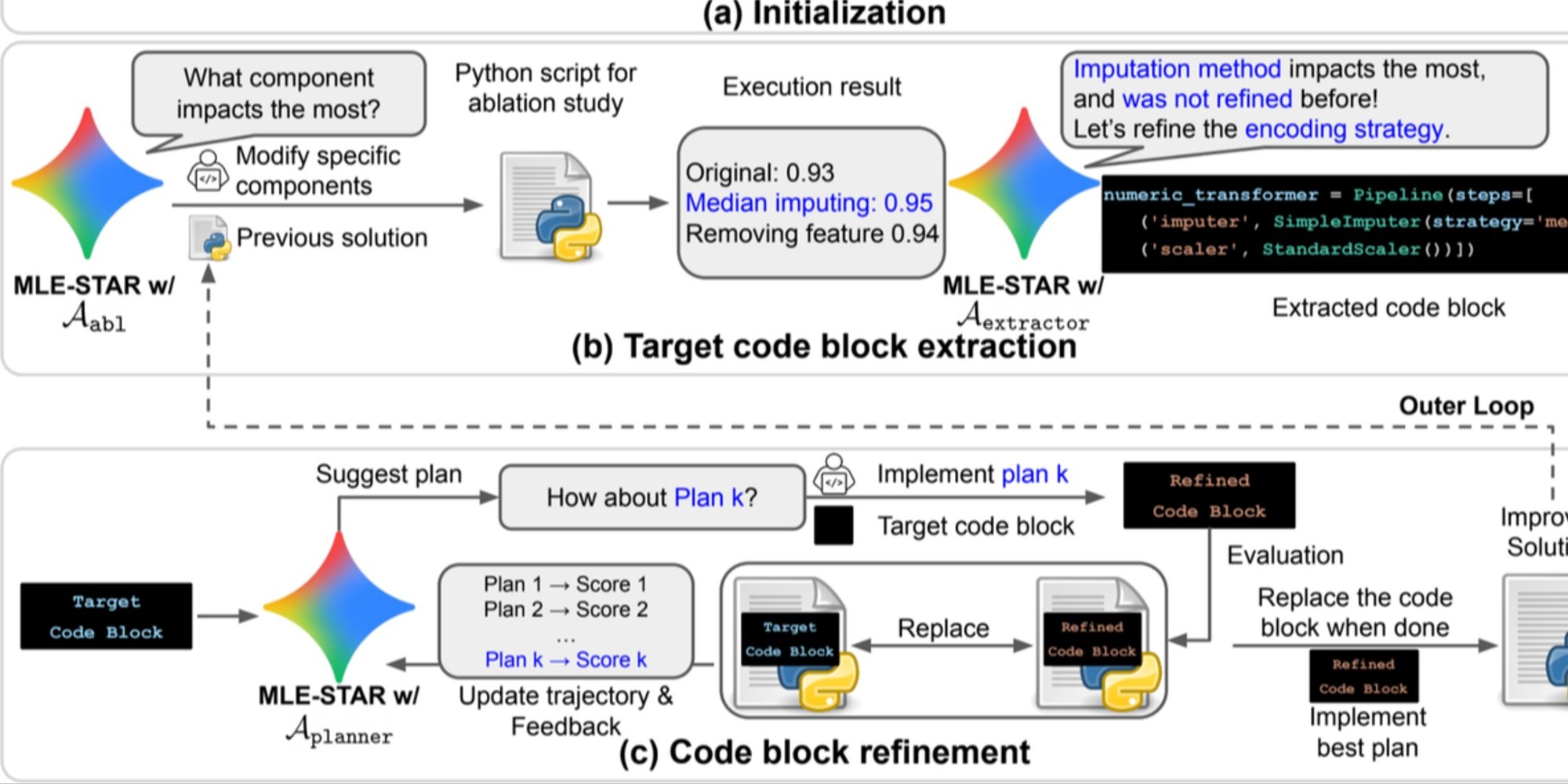
- تحسين دقيق بواسطة الكتل البرمجية، استنادًا إلى دراسات إبلاس لإيجاد الأجزاء الأكثر تأثيرًا على الأداء، ثم تحسينها بشكل تكراري؛
- استراتيجية تجميع تكيفية، قادرة على دمج عدة حلول مرشحة في نسخة محسنة، محكمة مع المحاولات المتكررة.
تسمح هذه العملية التكرارية، البحث، تحديد الكتلة الحرجة، التحسين، ثم التكرار الجديد، لـMLE-STAR بتركيز جهودها حيث تحقق أكبر مكاسب قابلة للقياس.
الائتمان: جوجل ريسيرش.
نظرة عامة. a) يبدأ MLE-STAR باستخدام البحث على الويب للعثور على نماذج خاصة بمهمة ودمجها في حل أولي. (b) لكل مرحلة تحسين، يقوم بدراسة إبلاس لتحديد الكتلة البرمجية ذات التأثير الأكثر أهمية على الأداء. (c) تخضع الكتلة البرمجية المحددة لتحسين تكراري بناءً على الخطط المقترحة من LLM، التي تستكشف استراتيجيات متنوعة باستخدام تعليقات من التجارب السابقة. تتكرر هذه العملية من اختيار وتحسين الكتل البرمجية المستهدفة، حيث تصبح الحلول المحسنة من (c) نقطة البداية للمرحلة التالية من التحسين (b).
وحدات التحكم لتحسين موثوقية الحلول
بالإضافة إلى نهجها التكراري، يتضمن MLE-STAR ثلاث وحدات مصممة لتعزيز متانة الحلول المولدة:
- وكيل تصحيح الأخطاء لتحليل أخطاء التنفيذ (على سبيل المثال، traceback في Python) وتقديم تصحيحات تلقائية؛
- مدقق تسرب البيانات للكشف عن المواقف التي يتم فيها استخدام معلومات من بيانات الاختبار بشكل خاطئ أثناء التدريب، وهو انحياز يشوه الأداء المقاس؛
- مدقق استخدام البيانات لضمان استخدام جميع مصادر البيانات المقدمة، حتى عندما لا تكون في تنسيقات قياسية مثل CSV.
تستجيب هذه الوحدات للمشاكل الشائعة التي لوحظت في الكود المولد بواسطة نماذج LLMs.
نتائج مهمة على Kaggle
لتقييم فعالية MLE-STAR، اختبرها الباحثون في إطار MLE-Bench-Lite، المبني على مسابقات Kaggle. كان البروتوكول يقيس قدرة الوكيل على إنتاج حل كامل وتنافسي من وصف مهمة بسيطة.
تظهر النتائج أن MLE-STAR تحصل على ميدالية في 63% من المسابقات، بما في ذلك 36% ذهبية، مقابل 25.8% إلى 36.6% للأساليب السابقة الأفضل. يُعزى هذا الربح إلى مجموعة من العوامل: التبني السريع لنماذج حديثة مثل EfficientNet أو ViT، القدرة على دمج نماذج غير محددة بواسطة البحث على الويب بفضل تدخل بشري عرضي، والتصحيحات التلقائية التي قدمها مدققو التسرب واستخدام البيانات.
يمكن العثور على الورقة العلمية على arXiv : "MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" (https://www.arxiv.org/abs/2506.15692 ).
الكود المفتوح المصدر متاح على GitHub